
Getting Big Data System Architecture Right on the First Try
Getting the architecture of a Big Data system right is not easy. There are so many different aspects to consider, and so many different trade-offs to get right. Getting to a system where network bandwidth, storage bandwidth and latencies, main memory size, and processor speed all balance nicely for the relevant workloads can be really challenging. Simulation offers an efficient way to try out different system configurations and component choices, to get the deployed system right on the first try. Intel® CoFluent™ Technology for Big Data (Intel CoFluent Technology) applies modeling and simulation technology to the Big Data system architecture domain with impressive results!
Modeling Big Data with Intel CoFluent Studio
Intel CoFluent Studio is a product from Intel that lets you build models of pretty much any system to evaluate performance and behavior using an abstract model instead of concrete code. I have written about the use of Intel® CoFluent™ Technology for IoT previously, and now we will take a look at how it works for Big Data.
A CoFluent model of a big data system reflects both the hardware resources available, how they are connected, and how the software components and operations map to the hardware. The model is naturally layered, as shown in this diagram (from the Intel® CoFluent™ Technology for Big Data whitepaper):
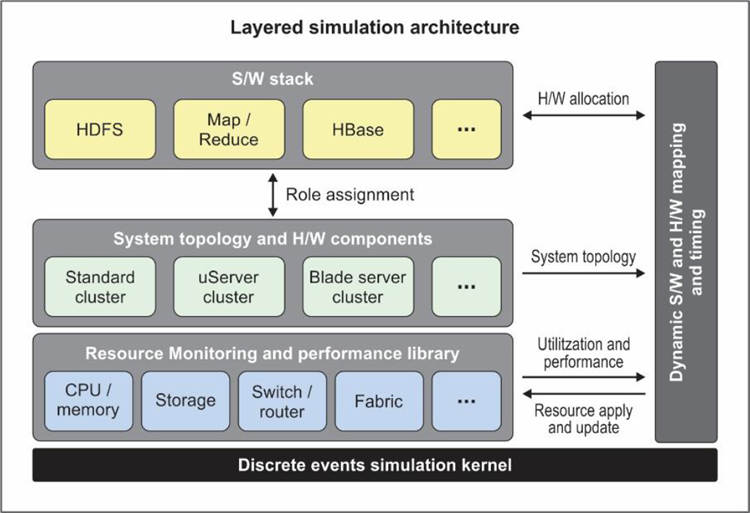
The performance values used for components in the model are calibrated against real hardware, to ensure the relevance and validity of the results. Such calibration is performed on a component basis, and the results reused in many different system designs and simulated scenarios. In this way, the problem of modeling a big system is broken down into small pieces: in a classic divide-and-conquer approach – allowing users to model systems ahead of their implementation, with results that are relevant for the eventual implementation.
Getting Results with Intel® CoFluent™ Technology
Using a model of a big data system, it is possible to quickly run simulations of very many different system configurations. This provides a map of the system performance as parameters are changed, and makes it possible to pin-point bottlenecks and imbalances in the system. It provides a way to evaluate the impact of making changes to the system, such as moving from spinning disks to SSDs in the storage system, or using a slower backplane.
A recent white paper about Intel® CoFluent™ Technology for Big Data provides several examples of the kind of results you can get from simulation.
For instance, the graph below (source) shows how the throughput of a Swift* cloud storage cluster varies with item size (16 kB, 1 MB, 16 MB), read/write ratio, and the nature of the storage (SSD or HDD). The benefit of using SSDs is clear – it enhances throughput several times, all other things being equal.
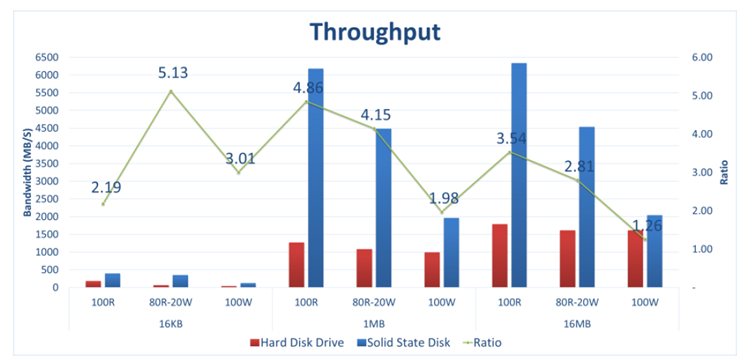
By looking at the system from different angles like this, you can get a good grip on its performance profile, and make informed decisions on where to invest on the hardware.
Checking the World
There is a classic joke from the Swedish military that goes like this: “Om kartan och terrängen inte stämmer överens är det kartan som gäller” – “if the terrain and the map do not agree, follow the map.” Which sounds absurd – but might actually be useful advice. In the world of simulation results, if the results from the simulator do not agree with what gets measured in reality, it is easy to dismiss the simulation as a map that is disassociated from reality…. But it might also be an indication that something in reality is a bit off.
For example, if the throughput of a system when built is significantly different from the predicted results from the simulator, it might indicate that something is not set up right. The simulator predictions are basically based assuming proper configuration of the real system, and a deviation might mean that the real system is not set up right.
One such case is discussed in the Intel® CoFluent™ Technology for Big Data whitepaper:
When we compared that data with our simulation numbers, we found that the throughput of small object writes in the physical system was much lower than the simulation numbers.
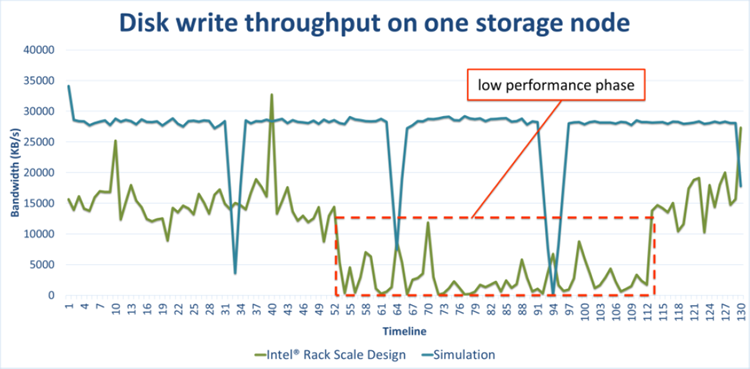
After we updated the OS configuration, the measurement numbers of the physical system matched the simulation numbers. This indicated that we had established an appropriate hardware and software configuration.
Thus, a simulation can act as a sanity check on reality. The mapping goes both ways – when the map and the terrain diverge, it makes sense to have a look at both sides and see where things need to be adjusted. It means that a simulation can be used downstream. It is just not an architecture tool, but also a debugging tool to be used during deployment and maintenance.
Learn More
To learn more about Intel CoFluent Technology, see Intel® CoFluent™ Technology
For more about Intel CoFluent Technology for Big Data, see Intel® CoFluent™ Technology for Big Data
Intel CoFluent Technology can also be applied to Internet-of-Things (IoT) systems, see Intel® CoFluent™ Technology for IoT