Weather forecasting is a crucial aspect of modern life, enabling efficient planning and logistics, while also protecting life and property through timely warnings of severe conditions. But accurate, long-range weather prediction is extremely complex, often involving enormous data sets and requiring code that is optimized to leverage the most advanced computer hardware features available.
Part of the challenge in creating modern, high-performance code is to identify aspects of the problem domain and related data sets that lend themselves to parallel optimizations. Developers also need to examine existing application processes and code to maximize the use of parallel hardware resources available in the system.
Toward this goal, Intel has defined a five-stage code modernization framework for multi-level parallelism that offers software developers a systematic approach to application performance improvement. In this case study, we will focus on describing the code optimizations related to vectorization, thread parallelization, and I/O throughput maximization, as applied to the Weather Research and Forecasting model, with special focus on the Intel® VTune™ Amplifier, the Intel® Advisor XE, and Intel® Xeon® processors.
Lessons from the Weather Research and Forecasting Model
Modern forecasting relies on numerical weather prediction systems, which run computer simulations of mathematical models of the atmosphere and oceans. One of the leading systems is the Weather Research and Forecasting (WRF) model, an open-source solution used around the world for both atmospheric research and day-to-day operational forecasting. Initially developed in the late 1990s, the WRF model has been continually updated and now engages a worldwide community of over 30,000 registered users spanning more than 150 countries.
The WRF model relies on systems of partial differential equations, based on the laws of physics, fluid dynamics, and chemistry, and divides the planet into a three-dimensional grid. This lets the system model the interaction of atmospheric conditions ranging in size from tens of meters to thousands of kilometers.
The nature of the problem domain makes numerical weather prediction an ideal candidate for code modernization through parallelization and other advanced techniques. Here we highlight how Intel technology enables the most common modernization approaches as applied to the WRF model, and also illustrate how software developers can use a comparable methodology to similarly optimize a wide range of software applications.
Identifying Potential Optimizations
Modern high-performance processors feature a combination of resources that include multi-core architectures, vector-processing capabilities, high-speed caches, and high-bandwidth I/O communications. Building software that takes best advantage of these features can let applications operate more efficiently and therefore process larger data sets. This can enable operations and analyses that might previously have been prohibitive, or even impossible.
The Intel five-stage code modernization framework recommends that developers:
- Use advanced optimization tools to profile code and identify vectorization and threading opportunities. After locating potential hotspots, use state-of-the-art compilers and optimized libraries to produce the most efficient code.
- Optimize scalar and serial operations by making sure that the code uses sufficient precision, employs type constants, and uses optimal configuration settings.
- Employ vectorization where possible by using single instruction multiple data (SIMD) features in the processor architecture.
- Perform thread parallelization and profile thread scaling to identify thread synchronization issues or inefficient memory access.
- Scale the application from multi-core to many core, using distributed memory rank parallelism, especially if the application lends itself to a highly-parallel implementation.
Note: For detailed information about this five-stage framework, see What is Code Modernization?
Profiling an Application
The first step in code modernization involves profiling the workload to identify candidate locations for code optimization. Using the Intel® VTune™ Amplifier, you can gain insight into CPU performance, threading performance, bandwidth utilization, caching effectiveness, and more. The tool presents information using higher-level threading models, making it easier to interpret results.
When you are ready to focus specifically on vectorization and threading opportunities, Intel® Advisor XE helps identify specific loops that deserve priority attention. Research shows that code that is vectorized and threaded can achieve performance gains of 175X or more when compared to conventional code, and about 7X performance over code that is only threaded or vectorized.
Intel Advisor XE also helps identify memory access patterns that can affect vectorization, as well as loops that have dependencies that prevent vectorization.
The modular architecture of the WRF aided in the initial high-level analysis and profiling, providing natural boundaries to help identify sections of code that were more significant than others. Manual inspection of the source code, assembly code, and compiler reports further allowed developers to locate specific segments that could not be automatically vectorized and might benefit from updates to the original instructions.
Leveraging Vectorization
After profiling your application, the next step in code modernization involves vectorizing your code. When code is vectorized, single computational instructions can operate simultaneously on one-dimensional arrays of data, known as vectors. These scalar data objects typically include integers and single- and double-precision floating-point values.
Vector computing is particularly well-suited in cases when an application needs to perform uniform operations on large data sets. This can offer significant performance gains on Intel® Many Integrated Core Architecture processors, such as the Intel® Xeon Phi™ Coprocessor. In the case of the WRF model, vectorization allows identical instructions to be simultaneously applied to multiple data elements, essential to dealing with evolving atmospheric conditions in a stepwise fashion over time.
Loops are a natural place to begin vectorization, and Intel compilers do a good job of inner loop vectorization automatically. However, you can also instruct the compiler to generate vectorization reports. These help identify locations in the application where the compiler is unable to automatically vectorize. At that point, compiler pragmas and directives are available to assist the compiler with vectorization.
As part of the process, you also need to ensure that the control flow within your application does not diverge unnecessarily. Controlling data alignment is important to optimize both data access and SIMD processing.
For example, consider the following code segment from the WRF model:
#pragma simd
DO i=i_start, i_end
ph_low = ...
flux_out = max(0.,fqx (i+1,k,j))-min(0.,fqx (i ,k,j)) )...
IF( flux_out .gt. ph_low ) THEN
scale = max(0.,ph_low/(flux_out+eps))
IF( fqx (i+1,k,j) .gt. 0.) fqx(i+1,k,j) = scale*fqx(i+1,k,j)
IF( fqx (i ,k,j) .lt. 0.) fqx(i ,k,j) = scale*fqx(i ,k,j)
END IF
ENDDO
In this case, the loop suggests flow and output dependence that inhibits automatic vectorization. Since it is a straightforward exercise to prove that, in fact, the IF condition implies no dependence, adding the simd pragma allows the compiler to vectorize the loop, thereby improving vectorization performance.
The WRF model further employed the following optimizations:
| Optimization | Summary |
|---|---|
| runscripts | Affinitization optimizations on Xeon Phi, which greatly improved load balance and allowed for the dramatic shrinking of the number of ranks. |
| advect_scalar_pd ysu2d | Improved vectorization performance by adding SIMD pragma and aligned directives. |
| w_damp | Enabled improved vectorization, removing some of the information in the abnormal case while still flagging the abnormal case. It is possible to get even better vectorization by loop un-switching. |
| WSM5 | Copied into and out of statically-sized thread-local tile arrays around calls to WSM5, and organized so that the values are aligned and in SIMD-width (16 word) chunks. Additionally, restructured loops that do not vectorize due to conditionals. |
| Pragmas | Many loops in the WRF code benefited from SIMD/IVDEP and other pragmas. |
The following shows the tuned profile for the Xeon Phi, before and after the optimized code:
| Intel® Xeon Phi™ Coprocessor (Before Optimizations) | |
|---|---|
| Function | App % |
| OMPTB::TreeBarrierNGO::exitBarrier | 0.00% |
| advect_scalar_pd_ | 21.43% |
| w_damp_ | 13.04% |
| ysu2d_ | 5.18% |
| nislfv_rain_plm_ | 5.15% |
| advance_uv_ | 3.84% |
| wsm52d_ | 3.62% |
| advect_scalar_ | 3.29% |
| set_physical_bc3d_ | 3.19% |
| advance_w_ | 2.91% |
| advance_mu_t_ | 2.37% |
| advect_w_ | 2.02% |
| OMPTB::TreeBarrier::enterBarrier | 0.00% |
| pbl_driver_ | 1.81% |
| rk_update_scalar_ | 1.55% |
| horizontal_pressure_gradient_ | 1.46% |
| rrtm_ | 1.44% |
| cal_deform_and_div_ | 1.27% |
| Intel® Xeon Phi™ Coprocessor (After Optimizations) | |
|---|---|
| Function | App % |
| OMPTB::TreeBarrierNGO::exitBarrier | 0.00% |
| advect_scalar_pd | 7.73% |
| advance_uv | 5.81% |
| advect_scalar | 5.40% |
| advance_w | 4.50% |
| ysu2d | 4.03% |
| advance_mu_t | 3.64% |
| nislfv_rain_plm | 3.14% |
| rk_update_scalar | 2.97% |
| zero_tend | 2.63% |
| calc_p_rho | 2.35% |
| Rtrn | 2.32% |
| wsm52d | 2.29% |
| pbl_driver | 2.28% |
| cal_deform_and_div | 2.27% |
| [vmlinux] | 0.00% |
| small_step_prep | 2.18% |
| phy_prep | 2.15% |
Optimizing Through Thread Parallelism
The WRF model consists of multiple modules, functions, and routines, each focused on different aspects of weather prediction–including wind, heat transfer, solar radiation, relative humidity, and surface hydrology, among others. This introduces an additional potential level of optimization known as thread parallelism, whereby cooperating threads work on a specific task within a single process, communicating through shared memory.
Because of Amdahl’s law–which states that the speedup of parallel programs is limited by the sequential portions of the code–thread parallelism works best at the outermost level. This means that each thread should do as much work as possible. It also means that you should match the degree of thread parallelism against the core count of the target hardware–introducing too much or too little parallelism can negate performance improvements because of overhead.
For the WRF model, OpenMP* (Open Multi-Processing) offered an effective approach. OpenMP is an application programming interface (API) that supports multi-platform, shared memory multiprocessing using FORTRAN* and other languages. OpenMP works by having a primary thread fork a series of secondary threads, which then run concurrently and independently on multiple processors.
OpenMP consists of a set of compiler directives, library routines, and environment variables. In the WRF model, sections of code that are meant to run in parallel are identified using a preprocessor directive. After the parallelized code completes, the threads join back into the primary thread, which continues running as usual. Using the OpenMP model, the WRF model achieves both task and data parallelism with minimum overhead.
The WRF model also uses Message Passing Interface (MPI)/ OpenMP* decomposition, operating on two levels: patches and tiles. For the patches, Conus12 has a domain of 425x300, and is broken into rectangular pieces that are assigned to MPI processes. Patches are further divided into tiles, which are assigned to shared memory threads (OpenMP) within the process. Tiles extend across the entire X dimension with the Y dimension subdivided. For example, in cases with 80 x 50 grid points per patch, X is 80 and Y is 50. For 3 OpenMP per rank, the patch would then be subdivided into 3 tiles: 80x17, 80x17, 80x16.
Tiles can be specified in the namelist.inut as “numtiles” or using environment variables (WRF_NUM_TIMES, WRF_NUM_TILES_X, and WRF_NUM_TILES_Y). The following shows the WRF model decomposition:
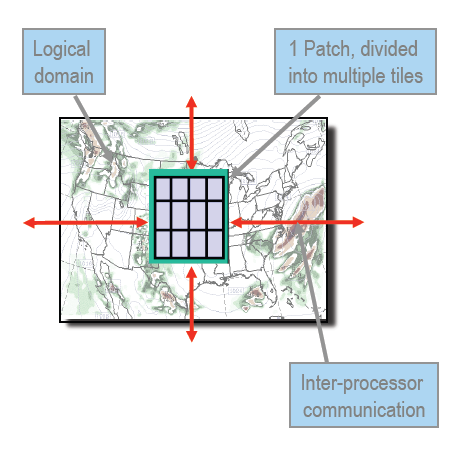
This leads the following WRF.conus12km layout on Intel® Xeon Phi™ / Intel® Xeon®:


The OpenMP overhead–the runtime spent performing tasks for OpenMP–could be ignored for the WRF model, because of the following:
- Approximately 20k fork-joins, with no other OpenMP usage
- Approximately 50k clocks (high) per fork-join
- Approximately 10e8 clocks total less than 1 second, which is less than 1%
Note that this could become more significant with additional MPI ranks, which translates to smaller workloads per rank.
Another parallel optimization focused on the surface_driver. Consider the following init code:
! 3d arrays
v_phytmp = 0.
u_phytmp = 0.
! Some 2d arrays
This code was parallelized to the following:
!$OMP PARALLEL DO &
!$OMP PRIVATE (ij, i, j, k)
DO ij = 1,num_tiles
do j = j_start(ij),j_end(ij)
do k = kms,kme
do i = i_start(ij),i_end(ij)
v_phytmp(i, k, j) = 0
u_phytmp(i, k, j) = 0
Implementing these changes reduced serial time to below the sampling resolution (effectively zero).
Data Bandwidth Considerations
With data-intensive problems such as the WRF model, systems can become bandwidth-bound if the application tries to use more memory bandwidth than is available. This is less of a consideration when using high-bandwidth processors such as the Intel Xeon Phi Coprocessor, but it remains an important factor that deserves developer attention.
Another consideration involves ensuring that data is organized to fit in the L2 cache of the processor, minimizing the need to access main memory, which imposes significant performance penalties. This might require you to use cache-blocking techniques, loading a subset of the larger data-set into cache and capitalizing on any data reuse inherent in the application.
Configuring for Optimal Performance
The need to correctly set relevant configuration files and environment variables is often overlooked, but is essential for optimal application performance. It can include sourcing the environment for Intel® MPI Library and the Intel® Compiler, turning on large file I/O support, and setting the Intel® Xeon Phi™ Coprocessor stack size to a sufficiently large value to prevent a segmentation fault.
Setting the correct compiler options is also critical to application performance. Building the WRF model for Intel Xeon processors and Intel Xeon Phi Coprocessors, for example, included the following options:
- -mmic: Build the application to run natively on Intel Xeon Phi Coprocessors
- –openmp: Enable the compiler to generate multi-threaded code based on the OpenMP directives (same as -fopenmp)
- -O3: Enable aggressive compiler optimizations
- -opt-streaming-stores always: Generate streaming stores
- -fimf-precision=low: Use low precision for higher performance
- -fimf-domain-exclusion=15: Generate lowest precision sequences for single precision and double precision
- -opt-streaming-cache-evict=0: Turn off all cache line evicts
Intel uncovered further optimizations with the Intel Xeon Phi coprocessor through the following run-time parameters:
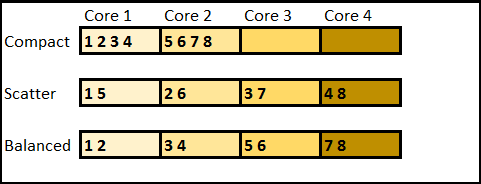
- Balanced affinity on Intel Xeon Phi coprocessor was determined to be best.
- The best tiling is by Y axis per core and X axis per thread.
- Keeping the X dimension on core improved cache hits.
- Use of new environment variables such as WRF_NUM_TILES_X (threads per core) and WRF_NUM_TILES_Y (cores). For example, 60 cores with 3 threads per core: X=3, Y=60.
The following shows the difference between compact, scatter, and balanced affinity on Intel Xeon Phi cores:
Conclusion
State-of-the-art, high-performance processors, such as the Intel Xeon and Intel Xeon Phi Coprocessor, provide a wealth of features to support code modernization for multi-level parallelism. This offers developers numerous options to deliver outstanding application performance that is both scalable and robust.
As demonstrated by the WRF model, carefully profiling your application and addressing key areas related to vectorization, threading parallelism, and data bandwidth using a stepwise methodology ensures the best results for today and the future.
For More Information
Learn more about the Weather Research and Forecasting Model at: www.wrf-model.org
Review the article What is Code Modernization? at: software.intel.com/content/www/us/en/develop/articles/what-is-code-modernization.html
Read more about Vectorization Essentials at: software.intel.com/content/www/us/en/develop/articles/vectorization-essential.html
Learn more from WRF Conus12km on Intel® Xeon Phi™ Coprocessors and Intel® Xeon® Processors at software.intel.com/en-us/articles/wrf-conus12km-on-intel-xeon-phi-coprocessors-and-intel-xeon-processors
Learn more from WRF Conus2.5km on Intel® Xeon Phi™ Coprocessors and Intel® Xeon® Processors in Symmetric Mode at: software.intel.com/en-us/articles/wrf-conus25km-on-intel-xeon-phi-coprocessors-and-intel-xeon-processors-in-symmetric-mode
For more about the Intel® VTune™ Amplifier see: software.intel.com/en-us/intel-vtune-amplifier-xe
For more about the Intel® Advisor XE see: software.intel.com/en-us/intel-advisor-xe
*Other names and brands may be claimed as the property of others.