Introduction
Vertex AI* is a fully managed AI service on Google Cloud* platform service that provides MLOps tools for automating, standardizing, and managing machine learning projects. It provides tooling to simplify the entire development lifecycle of machine learning models from training to deployment and scaling. Vertex AI also offers a range of ready-to-use models trained by Google and select third-party providers, as well as support for deploying custom models.
In addition to these services, Vertex AI offers a range of hardware to choose from. While accelerators like GPUs are seen as the go-to hardware solution for AI workloads, not all use cases require them. In this blog, we introduce the C3 virtual machine (VM) instance type that is now generally available on Vertex AI. The C3 family of VM instances uses 4th generation Intel® Xeon® Scalable processors with Intel® Advanced Matrix Extensions (Intel® AMX). Intel AMX is an integrated accelerator for deep learning workloads and consists of two-dimensional registers that store large chunks of data and the Tile Matrix Multiplication (TMUL) accelerator engine that performs the computations. Intel AMX enables AI workloads to run on the CPU rather than offloading them to a discrete accelerator and allows for more efficient and cost-effective inferencing compared to previous generations of Intel processors. This blog gives a tutorial on how to prepare and deploy a model to a C3 instance on Vertex AI and showcases the performance benefits that it can bring.
Tutorial
This tutorial assumes a familiarity with the Google Cloud platform service and requires a Linux*-based development environment with the following software installed:
This tutorial shows you how to:
- Prepare a model for Intel AMX.
- Prepare a TorchServe and Intel® Extension for PyTorch* container for deployment on Vertex AI.
- Deploy to a C3 instance on Vertex AI.
- Verify Intel AMX use.
Prepare a Model for Intel AMX
Set Up a Virtual Environment
Before preparing the model, we need to create our development environment. This tutorial requires Python 3.8 or later to be installed on your system. We are using the BERT-Large model from Hugging Face*. This requires the Hugging Face Transformers library and PyTorch. We will also need the Torch Model Archiver to package our model for serving with TorchServe, the Intel Extension for PyTorch to apply optimizations to our model, and the Vertex AI SDK for Python to create an end point and deploy our model.
# create virtual environment
python -m venv bert-env
source bert-env/bin/activate
# Vertex AI SDK
pip install --upgrade google-cloud-aiplatform
# PyTorch and IPEX
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip install intel-extension-for-pytorch
pip install oneccl_bind_pt --extra-index-url https://pytorch-extension.intel.com/release-whl/stable/cpu/us/
pip install torch-model-archiver
pip install transformers
Intel Extension for PyTorch needs to match the major release version of your PyTorch installation. If you are already working with an older version of PyTorch, follow the installation instructions for your specific version in the documentation.
Download the Model and Convert to bfloat16
With our virtual environment ready to go, we can begin preparing our model for accelerated performance on C3. In this example, we use the BERT-large model from Hugging Face.
import torch
import intel_extension_for_pytorch as ipex
import os
from transformers import AutoTokenizer, AutoModel, AutoConfig
model_name = "bert-large-uncased"
dtype = torch.bfloat16
output_dir = "model_artifacts"
output_model_path = os.path.join(output_dir, "bert_large_bf16.pt")
# Load bert-large model and tokenizer from Huggingface
config = AutoConfig.from_pretrained(model_name, torchscript=True)
config.save_pretrained(output_dir)
tokenizer = AutoTokenizer.from_pretrained(model_name, config=config)
tokenizer.save_pretrained(output_dir)
model = AutoModel.from_pretrained(model_name, config=config)
model.eval()
After downloading the model, we apply Intel Extension for PyTorch optimizations with just a single line of code.
# Apply IPEX optimizations
model = ipex.optimize(model,
conv_bn_folding=False,
dtype=dtype)
Intel AMX supports bfloat16 and int8 data types. Models are usually available in float32 format but we can simply convert our model to the bfloat16 data type with Torch Auto Mixed Precision (AMP). We also convert the eager mode model to a graph mode model with TorchScript as it generally yields better performance. For simplicity, we are using a batch size of 1 and the max sequence length for BERT-Large.
# Create sample input for jit tracing
vocab_size = model.config.vocab_size
batch_size = 1
seq_length = 512
sample_input = {"input_ids": torch.randint(vocab_size, size=[batch_size, seq_length]),
"token_type_ids": torch.zeros(size=[batch_size, seq_length],
dtype=torch.int),
"attention_mask": torch.randint(1, size=[batch_size, seq_length])}
# cast to BF16 and convert to torchscript
with torch.no_grad(), torch.amp.autocast('cpu',
cache_enabled=False,
dtype=dtype):
model = torch.jit.trace(model, example_kwarg_inputs=sample_input, strict=False)
model = torch.jit.freeze(model)
torch.jit.save(model, output_model_path)
Copy this code into a script called prepare_model.py and run it. It will create a directory called model_artifacts that contains a serialized model file, bert_large_bf16.pt, along with a few other configuration files needed by the BERT-Large tokenizer.
From here, the process is the same as preparing any other PyTorch model for TorchServe. TorchServe requires a model to be packaged using the Torch Model Archiver, which requires the following model artifacts:
- A serialized model file
- A model handler file
- Any extra files the model needs to run
TorchServe provides a few ways to define a model handler. In this example, we define an entry point function that first initializes the model and then handles incoming requests by parsing the JSON encoded text, tokenizing the text, and passing the tokenized input to our model.
Copy the following code into a file called model_handler.py in the model_artifacts folder.
import os
import torch
from transformers import AutoTokenizer
import intel_extension_for_pytorch
model = None
tokenizer = None
def bert_large_entry_point(data, context):
"""
Model handler that creates a model object or processes inference requests.
:param data: Input data for prediction
:param context: context contains model server system properties
:return: prediction output
"""
global model
global tokenizer
if not data:
manifest = context.manifest
properties = context.system_properties
model_dir = properties.get("model_dir")
#Read model serialize/pt file
serialized_file = manifest['model']['serializedFile']
model_pt_path = os.path.join(model_dir, serialized_file)
if not os.path.isfile(model_pt_path):
raise RuntimeError("Missing the model.pt file")
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = torch.jit.load(model_pt_path)
model.eval()
else:
#infer and return result
text = data[0].get("data")
tokenized_text = tokenizer(text, padding=True, truncation=True, return_tensors='pt')
embedding = model(**tokenized_text)[1].tolist()
return embedding
With all our model artifacts in place, we can use the Torch Model Archiver to package our model. We supply the model archiver with our serialized BERT-Large model file, the model handler we just defined, and an --extra-files parameter that includes files necessary to load the BERT-Large tokenizer. Run the following commands within the model_artifacts directory.
EXTRA_FILES="special_tokens_map.json,tokenizer_config.json,tokenizer.json,vocab.txt"
torch-model-archiver --model-name bert_large --version 1.0 --serialized-file bert_large_bf16.pt --handler model_handler:bert_large_entry_point --extra-files $EXTRA_FILES --export-path .
After running the previous commands, you should have a packaged model file called bert_large.mar in your model_artifacts directory.
Prepare a Container for Deployment on Vertex AI
TorchServe can be configured using a config.properties file. Customize your model server by specifying addresses for the inference, management, and metrics APIs as well as the number of model workers you want to run. To fully use Intel Extension for PyTorch, there are a few other parameters you need to set. Make sure to set ipex_enable=true and cpu_launcher_enable=true. Details on what this does and the appropriate cpu_launcher_args to use for different applications can be found on GitHub*.
Following is an example that can be saved to the model_artifacts directory:
service_envelope=json
inference_address=http://0.0.0.0:8080
management_address=http://0.0.0.0:8081
model_store=/home/model-server/model-store
load_models=bert_large.mar
default_workers_per_model=1
disable_token_authorization=true
ipex_enable=true
cpu_launcher_enable=true
cpu_launcher_args=--throughput-mode
Now that we have our model packaged for use with TorchServe, we can start building our serving container for Vertex AI. We are using the Intel Extension for PyTorch serving container as our base image. The following Dockerfile simply adds the transformers library and the numactl library, which can bring further performance improvements by pinning model workers to specific cores and memory nodes. After that, it simply copies our packaged model, exposes the ports that will be used by TorchServe, and specifies the TorchServe command to use on startup.
FROM intel/intel-extension-for-pytorch:2.4.0-serving-cpu AS base
USER root
# install numactl and transformers
RUN apt-get update && \
yes | apt install numactl && \
pip install transformers
USER model-server
WORKDIR /home/model-server
# copy packaged model file and TorchServe config
COPY ./config.properties /home/model-server/config.properties
COPY ./bert_large.mar /home/model-server/model-store/bert_large.mar
# expose ports for TorchServe inference and management API
EXPOSE 8080
EXPOSE 8081
# Launch TorchServe on start up
CMD ["torchserve", "--start", "--ts-config=/home/model-server/config.properties", "--models", "bert_large=bert_large.mar", "--model-store", "/home/model-server/model-store"]
Using the previous Dockerfile, we can build our container and push it to a Google Cloud project. This requires signing in to your Google Cloud project and configuring Docker authentication with Google Container Engine* service registry.
To authenticate with user credentials, run the following commands:
gcloud auth login
gcloud auth configure-docker
For more details, see the complete authentication documentation.
Run the following commands to build and push the container. Make sure to edit {PROJECT_ID} with your Google Cloud project ID.
GCLOUD_IMAGE_URI="gcr.io/{PROJECT_ID}/bert_large_c3"
docker build --network=host -f Dockerfile . --tag=$GCLOUD_IMAGE_URI
docker push $GCLOUD_IMAGE_URI
Run the container locally using the following command.
docker run --rm --cap-add SYS_NICE -p 8080:8080 --name=bert $GCLOUD_IMAGE_URI
Deploy to a C3 Instance on Vertex AI
With our model container in the Google Container Engine service registry, we are now ready to deploy it to Vertex AI. The first step is to upload the container to the Vertex AI Model Registry. This can be done using the Vertex AI SDK for Python that we installed as part of our virtual environment. In this step, we define the health and prediction routes along with the container ports that we want to expose.
from google.cloud import aiplatform
GCLOUD_IMAGE_URI="gcr.io/{PROJECT_ID}/bert_large_c3"
model_display_name = "bert_large_c3"
model_description = "BERT-Large with IPEX TorchServe container"
MODEL_NAME = "bert_large"
health_route = "/ping"
predict_route = f"/predictions/{MODEL_NAME}"
serving_container_ports = [8080]
# upload the model to Vertex AI
model = aiplatform.Model.upload(
display_name=model_display_name,
description=model_description,
serving_container_image_uri=GCLOUD_IMAGE_URI,
serving_container_predict_route=predict_route,
serving_container_health_route=health_route,
serving_container_ports=serving_container_ports,
)
model.wait()
print(model.display_name)
print(model.resource_name)
The model is now visible in the Vertex AI Model Registry dashboard as shown in the following image.

After uploading our model, we can create a Vertex AI end point and deploy it to a C3 instance. In this example, we use a c3-standard-44 instance.
# Create a Vertex AI endpoint
endpoint_display_name = f"{model_display_name}-endpoint"
endpoint = aiplatform.Endpoint.create(display_name=endpoint_display_name)
traffic_percentage = 100
machine_type ="c3-standard-44"
deployed_model_display_name = model_display_name
sync = True
# Deploy the model to the endpoint using a C3 instance
model.deploy(
endpoint=endpoint,
deployed_model_display_name=deployed_model_display_name,
machine_type=machine_type,
traffic_percentage=traffic_percentage,
sync=sync,
)
model.wait()
The end point and deployed model now appears under the Online Prediction tab in Vertex AI.
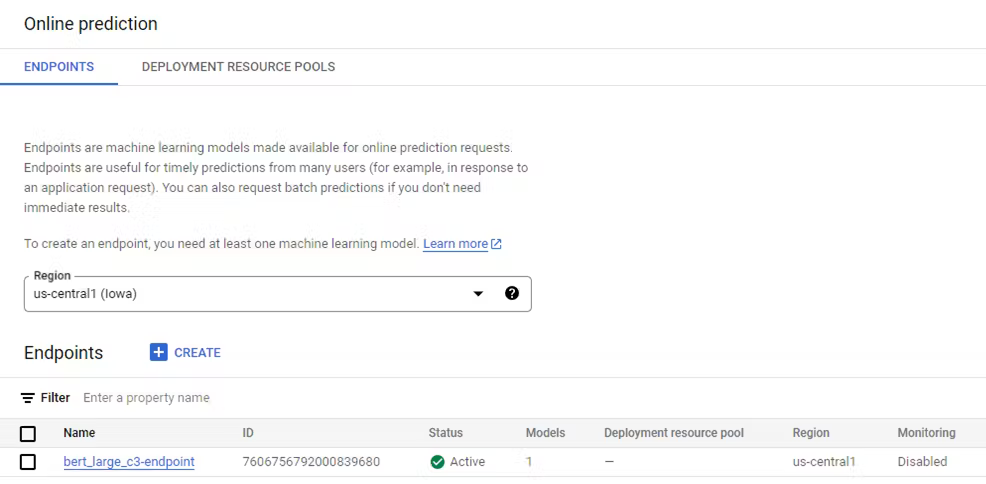
Test your end point using the following code:
from google.cloud import aiplatform
instance = [ { "data": "This is a test." } ]
endpoint = aiplatform.Endpoint('{ENDPOINT_RESOURCE_NAME}')
prediction = endpoint.predict(instances=instance) print(f"Prediction response: \n\t{prediction}")
The end point resource name can be found in the previous script's output or through the Vertex AI dashboard.

Verify Intel AMX Use
The DNNL_VERBOSE flag enables tracing the running of underlying primitive operations. This can be set in the model upload command as shown below.
model = aiplatform.Model.upload(
display_name=model_display_name,
description=model_description,
serving_container_image_uri=GCLOUD_IMAGE_URI,
serving_container_predict_route=predict_route,
serving_container_health_route=health_route,
serving_container_ports=serving_container_ports,
serving_container_environment_variables={"DNNL_VERBOSE": "1"}
)
If your model is using Intel AMX, the end point logs show a similar output to the following image:

Performance Gains from Intel AMX
This process can be used to prepare and deploy virtually any model for accelerated inference performance on C3. This example shows just over a 3x decrease in latency with batch size set to 1 compared to a float32 model on an N2 instance of similar size.

While not yet available on Vertex AI, C4 and N4 instances with 5th generation Intel Xeon Scalable processors are now generally available on Google Compute Engine* service and Google Kubernetes Engine (GKE). Intel AMX is also available on C4 and N4 and can be used in the same way. The N4 instance family allows for flexibility through custom vCPU shapes up to 80 vCPUs. While not as flexible as N4, C4 offers up to 192 vCPUs with better performance per vCPU. The C4 instance family is meant for your most demanding workloads such as AI. This same model shows a 3.8x inference speedup on C4 compared to N2 instances.

Intel AMX Is Readily Available on Google Cloud* Platform Service
Whether you are taking advantage of the ease of use facilitated by Vertex AI or opting for a more customizable solution with GKE, you can take advantage of Intel AMX through the readily available C3, N4, and C4 instance families. Intel AMX is not limited to transformer models. Along with large vCPU sizing options, Intel AMX allows for accelerated performance for a wide range of deep learning workloads from recommender models like DLRM to generative AI solutions like Stable Diffusion*.
Intel is leading the way for end-to-end open source AI software as a contributor to the Open Platform for Enterprise AI (OPEA). Check out OPEA at https://opea.dev/ for building your generative AI solutions.