INTRODUCTION
Ceph* is the most popular block and object storage backend. It is an open source distributed storage software solution whose outstanding abilities and features have drawn the attention of e-commerce companies who need relational database storage for workloads such as online transactional processing (OLTP) and other transaction-oriented applications. These database workloads, which require a high-performance storage solution with high concurrency, high availability, and extremely low latency, have posed new challenges for distributed storage systems, including Ceph.
Previous work by Reddy Chagam, Tushar Gohad, Orlando Moreno, and Dan Ferber6 has demonstrated that an Intel NVMe* SSD-based Ceph cluster can be a compelling storage solution for database OLTP workloads. This white paper describes how to leverage Intel® Optane™ technology and the new Ceph backend—BlueStore—to build an All-Flash Array (AFA) reference architecture (RA) for OLTP workloads. We discuss the motivations for running OLTP workloads on Ceph and how to achieve this using Intel Optane technology with BlueStore. We also introduce several typical RAs running OLTP workloads on Ceph. One of the most popular deployments was chosen to showcase the performance of the OLTP on an AFA Ceph RA based on Intel Optane technology.
We describe in detail the architecture of the Ceph all-flash storage system reference design, including Ceph configuration, client workload Sysbench* configuration, and testing methodology. We also provide Ceph performance information for the first Intel Optane technology and Intel® SSD Data Center (DC) P3700 Series MLC NAND-based all-flash cluster, which deliver multimillion queries per second (QPS) with extremely low latency. Finally, we share our Ceph BlueStore tuning and optimization recommendations, and MySQL* best-known configurations.
Why Ceph* for OLTP?
Several motivations are driving the adoption of Ceph for OLTP database storage. E-commerce service providers face the need to deliver high performance and low latency storage systems, increasingly at cluster scale. Some enterprises have chosen to endure the high operating and maintenance costs of their traditional storage solutions rather than use easy-scaling distributed storage solutions, but many others are exploring Ceph’s potential for their database storage systems.
OLTP is a popular data processing system used in today's enterprises, with workloads based on database queries. The typical usage scenario is a large number of users accessing the database at the same time and requiring milliseconds of response time to return or update records. The most important characteristics of OLTP workloads are high concurrency, large data volumes, and fast response time. Ceph’s promising performance of multiple I/O access to multiple RADOS block device (RBD) volumes addresses the need for high concurrency, while the outstanding latency performance of Intel® Solid State Drives and Ceph’s appropriately designed architecture can help deliver fast response times. Because Ceph is a good choice for a highly scalable storage solution, providing large volumes for a big database is no longer an issue in production.
BlueStore Backend
BlueStore is a new storage backend for Ceph. While the existing FileStore backend stores objects as files in an XFS file system, BlueStore stores data on the raw block device, which avoids double-writes due to use of a file system. The metadata is managed by RocksDB, a persistent key/value database. RocksDB can store files on BlueFS, which implements file-system-like interfaces that support its journal. Data can be stored on the same block device as is stored on BlueStore.1
BlueStore requires three devices or partitions: data, DB, and (write-ahead log) WAL. Generally, we can store the DB and WAL on a fast solid-state drive (SSD) device, since the internal journaling usually journals small writes. In this case, we could make better use of the fast device and boost Ceph performance with an acceptable cost.
Intel® Optane™ Technology and 3D NAND Technology
Intel Optane technology provides an unparalleled combination of high throughput, low latency, high quality of service, and high endurance. It is a unique combination of 3D XPoint™ memory media, Intel Memory and Storage Controllers, Intel Interconnect IP and Intel® software.2 Together these building blocks deliver a revolutionary leap forward in decreasing latency and accelerating systems for workloads demanding large capacity and fast storage.
3D NAND technology improves regular two-dimensional storage by stacking storage cells to increase capacity through higher density and lower cost per gigabyte, and it offers the reliability, speed, and performance expected of solid-state memory.3 This technology offers a cost-effective replacement for traditional hard-disk drives, helping customers enhance user experience, improve the performance of apps and services across segments, and reduce IT costs.
OLTP on Ceph Reference Architecture
When building an OLTP on Ceph RA, there are two aspects to consider. The first aspect is the architecture of the OLTP runtime environment for the front-end solution. The second is the hardware setup of Ceph as the backend storage solution.
We first introduce the OLTP deployment on the client side.
Typical OLTP deployment on Ceph
When deploying OLTP workloads on Ceph, consider the following:
- Ease of deployment: Workloads are easy to deploy and manage, instances are portable and removable.
- Performance: Expect to have a positive effect on performance and as little performance loss as possible on the layers.
- Availability: The workloads won’t be forced to stop in case of a single hardware or software failure.
- Consistency: High consistency can be supported and is not limited by the runtime environment.
OLTP workloads can run directly on physical machines (bare-metal), in containers, or on virtual machines (VMs).
On bare-metal, we map RBD volumes through the kernel module rbd.ko and access them using the device node /dev/rbd. Bare metal can provide remarkable performance, because applications can access the hardware directly and resources can be fully used.
A Docker container is a lightweight virtual technology, where containers share the same OS but run applications separately. In this case, we can achieve RBD access by mapping the RBD volumes through rbd.ko and making each container bind with a unique RBD device node.
The QEMU hypervisor + KVM has been adopted as the VM solution. Each VM maintains its own guest OS to run its applications. The QEMU hypervisor handles hardware allocation and virtualization. RBD volumes are created through librbd and attached to KVMs through libvirt.
For virtualization environments such as Docker or the QEMU hypervisor, server hardware resources may not be fully used during testing, and VMs cannot access physical hardware directly. Thus, bare metal generally performs better than VMs, since the multiple emulation layers slow down the running of applications, and the emulation process itself consumes extra resources. On the other hand, the use of VMs provides easier software management and better portability, which provides great scalability that bare metal cannot provide. Furthermore, bare metal doesn’t provide an application isolation mechanism, which may cause instability issues when upgrading or rolling back the system software. KVM VMs with QEMU virtio act as a full VM solution compared to half-virtualized Docker containers. Docker containers share the same kernel but isolate user space, so there’s no overhead of running guest kernels when using containers.
Table 1. Client configurations.
|
Virtualization Environment |
RADOS Block Device Engine |
|---|---|
| Bare metal | krbd |
| Docker containers | krbd |
|
QEMU hypervisor + KVM |
librbd |

Figure 1. Ceph client topology.
On the storage server side, Intel has proposed an RA for a Ceph-based AFA.
Ceph storage system configurations
This optimized configuration provided outstanding performance (throughput and latency) with Intel Optane SSDs as journal (FileStore) and WAL device (BlueStore) for a stand-alone Ceph cluster.
- All NVMe/PCIe* SSD Ceph system
- Intel Optane SSD for FileStore Journal or BlueStore WAL
- NVMe/PCIe SSD data, Intel® Xeon® processor, Intel Wireless Network Interface Cards
- Example: 4x Intel SSD Data Center (DC) P3700 800 GB for data, 1x Intel® Optane™ SSD DC P4800X 375 GB as Journal (or WAL and database), Intel Xeon processor, Intel Wireless Network Interface Cards
Table 2. Ceph storage system configurations
| CPU | Intel Xeon processor E5 v4 family Example: Intel Xeon processor E5-2699 v4 |
| Memory | ≥ 128 GB |
| Network interface card | Dual 10Gb Ethernet Example: Intel® 82599ES 10 Gigabit Ethernet Controller |
| Storage |
≥ 4x SSDs as data storage and ≥ 1x SSD as Journal or WAL Example: Data: 4x Intel SSD Data Center (DC) P3700 800 GB, Journal or WAL: 1x Intel Optane SSD DC P4800X 375 GB |
Notes:
- Journal: Ceph supports multiple storage back ends. The most popular one is FileStore, based on a file system (for example, XFS) to store its data. In FileStore, Ceph OSDs use a journal for speed and consistency. Using an SSD as a journal device will significantly improve Ceph cluster performance.
- WAL: BlueStore is a new storage back end, which is the default and replaces FileStore from the Ceph Luminous release. It overcomes several limitations of XFS and POSIX that exist in FileStore. BlueStore consumes raw partitions directly to store the data, but the metadata comes with an OSD, which is stored in RocksDB. RocksDB uses a write-ahead log to ensure data consistency.4
- The RA is not a fixed configuration. We will continue to refresh it with the latest Intel® products.
Ceph AFA Performance with OLTP Workloads
This white paper focuses on the Docker + krbd configuration as the OLTP deployment on the client side. This section presents a performance evaluation of the Ceph AFA cluster based on Ceph BlueStore.
Ceph Storage System Configuration
The test system described in Table 3 consisted of five Ceph storage servers, each fitted with two Intel Xeon processors E5-2699 v4 CPUs and 128 GB memory, plus 1x Intel Optane SSD Data Center (DC) P4800X 375 GB as a BlueStore DB/WAL device and 4x Intel SSD DC P3700 800 GB as a data drive, and 1x Intel® Ethernet Converged Network Adapter 82599ES 10-Gigabit network interface card (NIC). Two ports were used as a separate cluster and public network for Ceph. The cluster topology is described in Figure 2. The test system also consisted of five client nodes, each fitted with two Intel Xeon processors E5-2699 v4 and 128 GB memory and 1x Intel Ethernet Converged Network Adapter 82599ES 10 Gb NIC.
Ceph 12.0.0 (Luminous dev) was used, and each Intel SSD DC P3700 drive ran four OSD daemons. The RBD pool used for the testing was configured with two replicas.
Table 3. Storage system configuration.
| CPU | Intel Xeon processor E5-2699 v4 2.20 GHz |
| Memory | 128 GB |
| Network interface card | 1x 10 G Intel Ethernet Converged Network Adapter 82599ES |
| Disks |
1x Intel SSD Data Center (DC) P4800X (375 GB) + 4x Intel SSD DC P3700 (800 GB) |
| Software configuration |
Ubuntu* 14.04, Ceph 12.0.0 |
Docker Container Configuration
On each client node, four pairs of containers were created for both SysBench and the MySQL* database. The SysBench container was linked from the MySQL container and could directly access the database by running the Sysbench OLTP test case. Each container was assigned to a limited number of CPUs and had limited memory.
Table 4. Docker container configuration.
| Number of Sysbench containers | 4 |
| Number of MySQL containers | 4 |
| Sysbench container |
6 CPUs (no dedicated memory allocated since it only consumes ~50 MB memory) |
| MySQL container | 16 CPUs, 32 GB Memory |
| Software configuration | Docker version 17.03.1-ce, build c6d412e |

Figure 2. Cluster topology.
Test Methodology
To simulate a typical usage scenario, three OLTP test patterns were selected using the Sysbench tool.5 The test patterns consisted of OLTP 100-percent read, 100-percent write, and an OLTP default mix read/write. For each pattern, the throughput (QPS or latency) was measured. The volume size was 150 GB. To get stable performance, the volumes were pre-allocated to bypass the performance impact of thin-provisioning. The OSD page cache was dropped before each run to eliminate page cache impact.
The value of MySQL innodb_buffer_pool_size was set to 21 GB, and the innodb_log_file_size to 4 GB. The total memory consisted of a full MySQL innodb buffer pool and two log binary files. The total memory size allocated was about 31 GB, which was an appropriate value compared to the 32 GB memory we preconfigured for the MySQL container. The size of the database initialized was four times the size of innodb_buffer_pool_size, which made the innodb buffers 25 percent of the data.
For each test case, Sysbench OLTP was configured with a 300-second warm-up phase and 300-second data collection phase. Sysbench test parameter details are included in the software configuration section of this article.
Performance Overview
Table 5 shows the promising performance achieved after tuning on this five-node cluster. OLTP 100 percent read throughput was 2366K QPS with 2.7 ms average latency, while 100 percent write throughput was 504K QPS with 32.4 ms average latency. In the mixed read/write test, the test case closest to a typical usage scenario, the throughput was 1245K QPS with 6.8 ms average latency.
Table 5. Performance overview.
|
Pattern |
Throughput |
Average Latency |
|---|---|---|
| 100% read | 2366K QPS | 2.7 ms |
| 100% write | 504K QPS | 32.4 ms |
|
Mixed read/write (75%/25%) |
1245K QPS | 6.8 ms |
Scalability tests
Figure 3 shows the graph of throughput to latency for OLTP read, OLTP write, and OLTP mixed read/write workloads with different Sysbench threads.
Ceph demonstrated excellent thread scale-out ability on OLTP read performance on the AFA RA. The QPS doubled as the number of threads doubled, and latency stayed below 5 ms until the thread number exceeded the container CPU number. As for OLTP write, QPS stopped scale out beyond eight threads; after that, latency increased dramatically. This behavior shows that OLTP write performance was still limited by Ceph 16K random write performance. OLTP mixed read/write behaved within expectation as its QPS also scaled out as the thread number doubled.

Figure 3. OLTP thread scaling performance.
Figures 4 and 5 show the graph of per volume throughput to latency for OLTP read and OLTP write workloads with different volume numbers. For both OLTP read and OLTP write, per volume throughput started to decrease from five volumes, and average latency started to increase from five volumes. This demonstrated that OLTP read and write performance ceased to scale linearly when volume number was above five.

Figure 4. OLTP read per volume performance.

Figure 5. OLTP write per volume performance.
Latency Improvement with Intel® Optane™ SSDs
Figure 6 shows the latency comparison for OLTP write, mixed read/write workloads with 1x Intel SSD DC P3700 Series 2.0 TB drive and 1x Intel Optane™ SSD DC P4800X Series 375 GB drive as RocksDB and WAL device, respectively. The results show that with the Intel Optane SSD DC P4800X series 375 GB drive for RocksDB and the WAL drive in Ceph BlueStore, the latency was reduced: a 25-percent reduction in 99.00-percent latency for OLTP write and a 181-percent reduction in 99.00-percent latency for OLTP mix read/write.
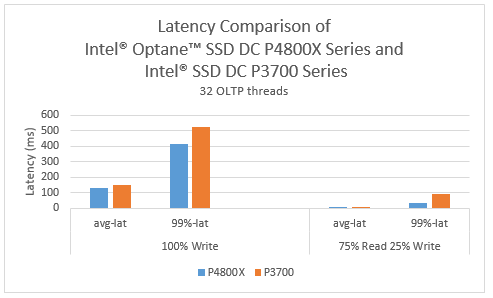
Figure 6. OLTP write and OLTP mix read/write latency comparison.
Summary
In this white paper, we first stated our motivations for deploying OLTP on Ceph. Then we introduced Intel Optane technology based OLTP on Ceph RA. Finally, we demonstrated excellent OLTP performance with several sets of the Sysbench test results and concluded that Ceph is a great cloud storage solution for OLTP systems.
Deploying Intel Optane technology as part of a Ceph BlueStore cluster boosts the OLTP performance and greatly reduces the OLTP 99-percent latency. The thread-scaling test results demonstrated that the Ceph cluster based on Intel Optane technology performed very well in the scenario of high concurrency OLTP workloads. The volume scaling test results showed that a Ceph cluster based on Intel Optane technology can provide high availability as the volume number increases and showed great stability as the disk usage increased.
To summarize, the combination of Intel Optane technology and Intel® 3D NAND SSDs provides the following benefits on Ceph:
- Better storage efficiency
- Better Quality of Service
- High IOPS and throughput
- Better performance consistency
- Best TCO on IOPS/$, TB/Rack, IOPS/TB
Next Steps
As a next step, we could leverage the client-side cache to further boost OLTP performance. To do this, we would add an extra SSD for use as a caching device between the client and storage. This feature brings a significant performance impact to the current Ceph architecture. Table 6 shows the 4K random write performance of a single node using Intel SSD DC P3700 and an Intel Optane SSD for caching, compared with Ceph Baseline, using 10 RBD volumes. As we can see, if we introduce the client-side cache feature to OLTP on the Ceph solution, we can expect greater improvement of OLTP performances.
Table 6. Performance comparison with client-side cache enabled.
|
Throughput |
Average Latency |
99.99% Latency |
|
|---|---|---|---|
| Ceph baseline | 6476 IOPS | 432.08 ms | 7756.7 ms |
|
Intel SSD DC P3700 (QD=64) |
215190 IOPS | 2.88 ms | 20.69 ms |
|
Intel Optane SSD DC P4800X (QD=16) |
345462 IOPS |
0.432 ms | 4.17 ms |
In the future, Ceph all-flash configurations will transition from the configurations described in this article to Intel® Optane™ + 3D NAND TLC SSD-based configurations, where better OLTP performances are to be expected. The transition trend diagram is shown in Figure 7.

Figure 7. Ceph all flash configuration transition trend.
About the Authors
Ning Li is a software engineer of the Cloud Storage Engineering team from Intel Asia-Pacific Research & Development Ltd. He is currently focusing on Ceph benchmarking and performance tuning based on Intel platforms and reference architectures. Ning has worked for Intel for six years and has software development and performance optimization experience in open sources technologies including Ceph, Linux kernel, and Android.
Jian Zhang is an engineering manager at Intel. He manages the cloud storage engineering team in Intel Asia-Pacific Research & Development Ltd. The team’s focus is primarily on open source cloud storage performance analysis and optimization, and building reference solutions for customers based on OpenStack Swift and Ceph. Jian Zhang is an expert on performance analysis and optimization for many open source projects, including Xen, KVM, Swift and Ceph, and benchmarking workloads like SPEC*. He has worked on performance tuning and optimization for seven years and has authored many publications related to virtualization and cloud storage.
Jack Zhang is currently a senior SSD Enterprise Architect in Intel’s NVM (non-volatile memory) solution group. He manages and leads SSD solutions and optimizations and next generation 3D XPoint solutions and enabling across various vertical segments. He also leads SSD solutions and optimizations for various open source storage solutions, including SDS, OpenStack, Ceph, and big data. Jack held several senior engineering management positions before joining Intel in 2005. He has many years’ design experience in firmware, hardware, software kernel and drivers, system architectures, as well as new technology ecosystem enabling and market developments.
Acknowledgement
Special thanks to Tushar Gohad for helping to review the test cases and test results.
Software Configuration
MySQL configuration used for testing
[client]
port = 3306
socket = /var/run/mysqld/mysqld.sock
[mysqld_safe]
socket = /var/run/mysqld/mysqld.sock
nice = 0
[mysqld]
user = mysql
pid-file = /var/run/mysqld/mysqld.pid
socket = /var/run/mysqld/mysqld.sock
port = 3306
basedir = /usr
datadir = /var/lib/mysql
tmpdir = /tmp
lc-messages-dir = /usr/share/mysql
skip-external-locking
key_buffer = 16M
max_allowed_packet = 16M
thread_stack = 192K
thread_cache_size = 8
myisam-recover = BACKUP
max_connections = 500
query_cache_limit = 1M
query_cache_size = 16M
log_error = /var/log/mysql/error.log
expire_logs_days = 10
max_binlog_size = 100M
performance_schema=off
innodb_buffer_pool_size = 21G
innodb_flush_method = O_DIRECT
innodb_log_file_size = 4G
thread_cache_size=16
innodb_file_per_table
innodb_checksums = 0
innodb_flush_log_at_trx_commit = 0
innodb_write_io_threads = 16
innodb_read_io_threads = 16
[mysqldump]
quick
quote-names
max_allowed_packet = 16M
[isamchk]
key_buffer = 16M
Sysbench commands
Read:
sysbench --mysql-host=db1 --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-engine=innodb --oltp-tables-count=30 --oltp-table-size=14000000 --test=/root/docker/sysbench-0.5/sysbench/tests/db/oltp.lua --oltp-read-only=on --oltp-range-size=0 --oltp-simple-ranges=0 --oltp-sum-ranges=0 --oltp-order-ranges=0 --oltp-distinct-ranges=0 --oltp-index-updates=0 --oltp-non-index-updates=0 --oltp-point-selects=10 --oltp-dist-type=uniform --num-threads=8 --report-interval=60 --warmup-time=300 --max-time=300 --max-requests=0 --percentile=99 run
Write:
sysbench --mysql-host=db1 --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-engine=innodb --oltp-tables-count=30 --oltp-table-size=14000000 --test=/root/docker/sysbench-0.5/sysbench/tests/db/oltp.lua --oltp-read-only=off --oltp-range-size=0 --oltp-simple-ranges=0 --oltp-sum-ranges=0 --oltp-order-ranges=0 --oltp-distinct-ranges=0 --oltp-index-updates=100 --oltp-non-index-updates=0 --oltp-point-selects=0 --oltp-dist-type=uniform --num-threads=8 --report-interval=60 --warmup-time=300 --max-time=300 --max-requests=0 --percentile=99 run
Mix RW:
sysbench --mysql-host=db1 --mysql-port=3306 --mysql-user=root --mysql-password=123456 --mysql-engine=innodb --oltp-tables-count=30 --oltp-table-size=14000000 --test=/root/docker/sysbench-0.5/sysbench/tests/db/oltp.lua --oltp-read-only=off --oltp-simple-ranges=0 --oltp-sum-ranges=0 --oltp-order-ranges=0 --oltp-distinct-ranges=0 --oltp-dist-type=uniform --num-threads=8 --report-interval=60 --warmup-time=300 --max-time=300 --max-requests=0 --percentile=99 run