![]()
I am really sad that the European Space Agency (ESA) lost their Schiaparelli lander, as we will miss out on a lot of Mars science – even though it was mostly a test for how to land on Mars. From a software engineering and testing perspective, the story of why the landing failed (see for example the ESA initial analysis, Space News, or the BBC) is rather instructive. It gets down to how software can be written and tested to deal with unexpected inputs in unexpected circumstances.
According to the ESA analysis, something went wrong in either a physical sensor or the core driving the sensor, leading to a series of “saturated” readings, which in turn made the control system believe it had already landed. While at a rather high distance above the surface. Net result: oops, crash, as it jettisoned the parachute way too early.
The ESA statement has this to say:
However, saturation – maximum measurement – of the Inertial Measurement Unit (IMU) had occurred shortly after the parachute deployment. The IMU measures the rotation rates of the vehicle. Its output was generally as predicted except for this event, which persisted for about one second – longer than would be expected.
When merged into the navigation system, the erroneous information generated an estimated altitude that was negative – that is, below ground level. This in turn successively triggered a premature release of the parachute and the backshell, a brief firing of the braking thrusters and finally activation of the on-ground systems as if Schiaparelli had already landed. In reality, the vehicle was still at an altitude of around 3.7 km.
This behavior has been clearly reproduced in computer simulations of the control system’s response to the erroneous information.
In short, what this means is that “we had what looks like a glitch and some inputs we did not predict and thus did not try in testing entered the software - and it failed”. This is not making light the achievement and professionalism of the developers working for ESA – any software engineer would recognize the phenomenon. Dealing with truly unexpected inputs in a sane way, when popping an error dialog and asking the user for help is not an option for most systems used in the real world. This kind of behavior is not OK on a public information display (where is the keyboard to press the F keys on?), and most definitely won’t cut it on Mars (observed on my way to work one morning in June 2016):
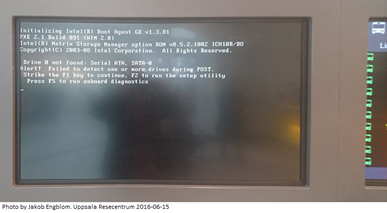
I believe that in many ways, the testing that we need for embedded systems is similar to what you do in software security research (or the other way around, considering that embedded got here first). Finding the unexpected and improperly handled nasty bad inputs is a key part of the game. In a mobile phone, nasty inputs cause exploits. In a space probe, they cause explosions.
Thus, the question becomes how to expand the set of available inputs to test both within the boundaries you imagined when creating the code – as well as how to explore outside the set of possible values. It is surprising how often “that cannot happen” turns into “how did that ever work” in programming… Unlike physical systems, you cannot rely on physical things like inertia to keep moment-to-moment changes within some range of possibilities.
Simulation as the Test Tool
What we need is a way to inject arbitrary values and subject the system to stresses that we would not see in normal testing. This applies to both physical and computer systems, and the space industry has a long history of sophisticated testing. It is basically simulation in all kinds of ways, shapes, and forms. Here is a photo from ESA showing how they test the actual physical lander in a simulated environment:
 Image Copyright ESA. Image source: http://www.esa.int/spaceinimages/Images/2013/11/ExoMars_EDM
Image Copyright ESA. Image source: http://www.esa.int/spaceinimages/Images/2013/11/ExoMars_EDM
That’s what we have to do to the software too. Put it under extreme simulated stresses in a simulator, before flying it. The statement from ESA indicates that they did apparently have a simulator available for the lander and its control system, and that given the telemetry from the lander, they could reproduce the behavior.
Such a simulator is a good thing for testing both inside and outside the boundaries. It is even better that it can also be fed with real-world inputs to analyze the behavior of the system post-facto.
Fuzzing and Intelligence
With a simulator, you can program any inputs you want. Use your imagination for some set of testing, models of likely scenarios for another bunch, and then create a random fuzzer to find the things you could not imagine. In particular, fuzzing is great in order to find the error scenarios you could not dream up.
In the Schiaparelli case, it seems we had a transient bad reading from an instrument – which could be a hardware fault, software fault, or just an extreme behavior in the physical world. That kind of upset should be possible to inject and test in simulation, in the lab, before hitting Mars.
Imagining the Unimaginable
The point here is not to point a finger at ESA for this failure – but to use the issue as an example of the importance of testing with imagination and beyond imagination. Similar things have hit other space agencies in the past, like the NASA Mars Rover Spirit where the file system got filled up during the flight to Mars. In that case, they simply did not test a full flight since it would have taken a bit too much time (which can in principle be solved by simulation).
You have to test beyond the most extreme conditions foreseen, just as well as normal conditions and within the bounds of expected conditions. This also involves doing “fault injection”, where we start to model breakdowns in the computer hardware, and not just extreme conditions in the real world.
The diagram below attempts to capture the set of possible states, and how we can think about the creation of test cases for various sets of states:
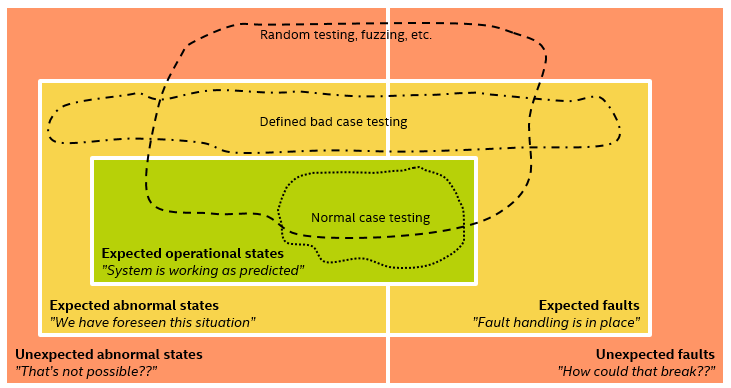
My point is that there is always going to be unexpected invalid and unexpected unusual states, and our code has to be robust against such things occurring. We also need testing to go beyond what we can imagine - by using some method that will produce new tests. Randomization and fuzzing is one way to do this. Another way is to bring in different perspectives from outsiders, which will tend to push the yellow “imaginable bad things” area out, and reducing the red “unimaginable bad things” area.
In a future blog post, I will look a bit more about how you go about stretching testing out into the extremes of all areas.
Conclusion
In conclusion, the Schiaparelli case is yet another example of how hard it is to get software right. Robust systems depend on extensive testing, as well as code that is capable of dealing with unexpected situations. And that code for unexpected situations also has to be tested in ways that somehow cause the unexpected to happen. Thus, the next time an “unexpected error” happens, at least the code will not suffer the expected failure.