The Intel® Distribution of OpenVINO™ toolkit release 2020 r1 includes a new demo for speech recognition.
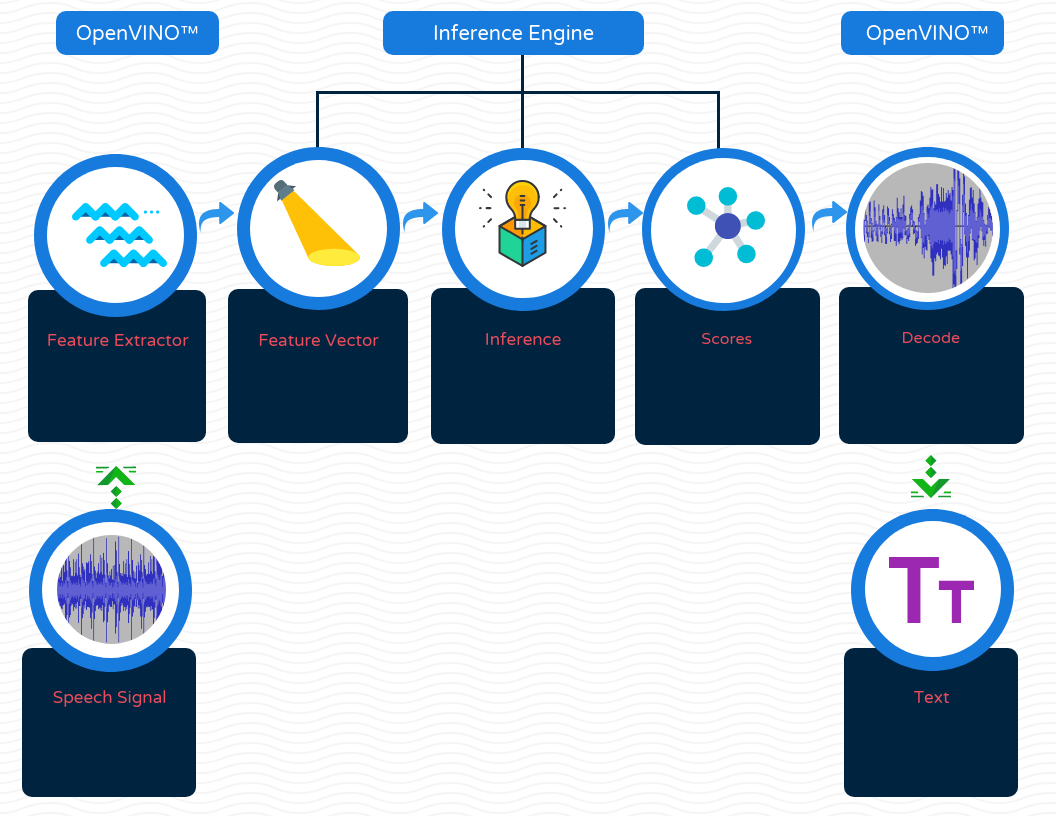
This release provides a set of libraries and demos to demonstrate end-to-end speech recognition. OpenVINO™ also provides new acoustic and language models to work with these demos. A full end-to-end speech processing scenario is covered and demonstrated by libraries and tools distributed with OpenVINO™.
The Speech Library wraps all of the processing blocks and exposes a simple API. The library takes care of proper initialization and data passing between all the components in the pipeline.
Speech Library contains:
- Two core binary libraries, Intel® Feature Extraction library and Intel® Speech Decoder (in lib dir),
- Speech library source code (in the src dir),
- Speech library header files (in the include dir). The library API is in the file speech_library.h. To compile the libraries, please run a script (.sh file) in the root directory of the speech libraries and demos, or run the demonstration script (<INSTALL_DIR>/deployment_tools/demo/speech_recogintion.sh).
There is a demo in the following directory:
/opt/intel/openvino/deployment_tools/
This name of the demo is to run is:
demo_speech_recognition.sh
This demo runs the following:
- Initializes the environment
- Downloads speech models (approximately 10 minutes depending on your network)
- Models and size
The demo calls on the speech recognition models set built using Kaldi* s5 NNET1 recipe. The files are located at:
/opt/intel/openvino/data_processing/audio/speech_recognition/
This article offers guidance to run the speech demo available in 2020 r1 of Intel® Distribution of OpenVINO™ toolkit.
Prerequisites
- Intel® Distribution of OpenVINO™ toolkit 2020 r1 installed
- Ubuntu* 18.04 (kernel 5+)
- Audio capabilities
- Familiarity with Linux* commands
Models
Speech recognition models set is built using Kaldi s5 NNET1 recipe.
Run the demo
Change Directory
To run the demo change directory to the demo directory by running the command:
cd /opt/intel/openvino/deployment_tools/demo
Run Script
Run the script for the speech recognition demo:
./demo_speech_recognition.sh
Results
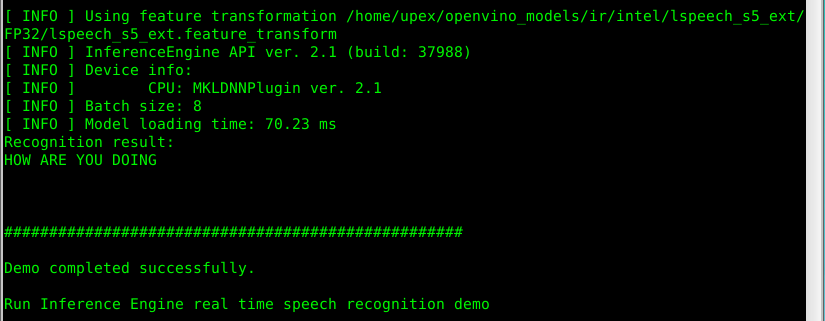
Python run results
After the demo completed successfully, some python scripts ran and this tool displayed for use.
More information about the models used for speech recognition
Find the following information in the lspeech_s5_ext.yaml file.
name: lspeech_s5_ext description: >- This is a speech recognition models set built using Kaldi s5 NNET1 recipe. output: intel/lspeech_s5_ext task_type: detection files: topologies: - name: lspeech_s5_ext description: >- This is a speech recognition models set built using Kaldi s5 NNET1 recipe. output: intel/lspeech_s5_ext task_type: detection files: - name: FP32/speech_recognition_config.template size: 1267 sha256: 6cd4897386b939e571a8c9b9720f21101b3b8aff9dd9796e81f49cd898d14543 source: https://download.01.org/opencv/2020/openvinotoolkit/2020.1/models_contrib/speech/kaldi/librispeech_s5/OV/speech_recognition_config.template - name: FP32/lspeech_s5_ext.feature_transform size: 3056 sha256: 074925603942d662f95ce9d5a1eb29b8b933d3dd98371285b1af9437da4c46b2 source: https://download.01.org/opencv/2020/openvinotoolkit/2020.1/models_contrib/speech/kaldi/librispeech_s5/OV/lspeech_s5_ext.feature_transform - name: FP32/lspeech_s5_ext.xml size: 5329 sha256: a97ed9f37dd9ad75b9ce86e95742117535b0f6493c4df6d3c616cfbb862e5300 source: https://download.01.org/opencv/2020/openvinotoolkit/2020.1/models_contrib/speech/kaldi/librispeech_s5/OV/lspeech_s5_ext.xml - name: FP32/lspeech_s5_ext.bin size: 26764224 sha256: bf35171ceb79c0c15484d236be6778492056fd1c1dbf4a27bbbf6902a839294a source: https://download.01.org/opencv/2020/openvinotoolkit/2020.1/models_contrib/speech/kaldi/librispeech_s5/OV/lspeech_s5_ext.bin - name: FP32/hclg.fst size: 946851404 sha256: 140f4b07482809d3dfcb6c5009b99af7f4f4b2ca0d1093e7a758142472fe9091 source: https://download.01.org/opencv/2020/openvinotoolkit/2020.1/models_contrib/speech/kaldi/librispeech_s5/OV/hclg.fst - name: FP32/labels.bin size: 2537784 sha256: de101e4e7926cfa3fb84469cb3f9c92d8230876321995a7aa662c555126f250c source: https://download.01.org/opencv/2020/openvinotoolkit/2020.1/models_contrib/speech/kaldi/librispeech_s5/OV/labels.bin framework: dldt license: https://raw.githubusercontent.com/opencv/open_model_zoo/master/LICENSE
Learn More
Speech Library and Speech Recognition Demos
Speech Sample