The Load Value Injection (LVI) technical documentation describes how LVI methods against Intel® Software Guard Extensions (Intel® SGX) enclaves can be mitigated by inserting an LFENCE instruction after each load to serialize its execution. Rather than individually mitigating all load instructions, it is possible to instead consider all Load+Transmit gadgets, which are pairs of instructions that consist of a load and a subsequent instruction that may transmit the loaded value via a covert channel. All Load+Transmit gadgets are mitigated against LVI if the following property is satisfied:
For all Load+Transmit gadgets in each procedure/function, every path in the control flow graph (CFG) from Load to Transmit is “cut” by at least one LFENCE instruction.
Intel has collaborated with industry partners to develop a patch to LLVM/clang that optimally satisfies this property. The patch analyzes the CFG to find all Load+Transmit gadgets, and then uses this information to build a condensed CFG that characterizes the control-flow relationships between the gadgets. An example of a condensed CFG is depicted in Figure 1.
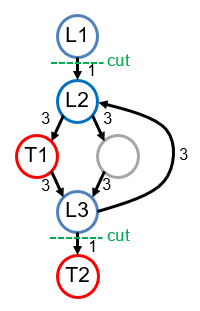
Figure 1. Condensed Control Flow Graph (CFG)
The value loaded by instruction L1 can be transmitted by the instruction denoted as T1, and likewise for L2 and T2. Load L3 has no corresponding transmitter. The edges (black arrows) indicate control flow, and the annotation for each edge is a positive integer that estimates the cost of inserting an LFENCE instruction along that edge. Intuitively, inserting an LFENCE into a loop is more expensive than inserting it outside of a loop, because any LFENCE inside of a loop is likely to be executed more than once.
The cost of inserting LFENCE instructions can then be estimated as:
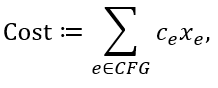
where for each edge e, the constant ce represents the cost of inserting an LFENCE along e, and xe is 1 if the edge receives an LFENCE instruction, and 0 otherwise. Recall that the desired security property requires at least one LFENCE instruction along every CFG path from each load to each of its corresponding transmits. Hence the next step for the analysis is to find, for each Load+Transmit gadget, all paths in the condensed CFG from the load instruction to the transmit instruction. Once all paths have been found, the requirement that each path must be “cut” by at least one LFENCE instruction can be formalized as:
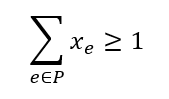
for all condensed CFG paths P from Li to Ti, and for all k gadgets (i.e., ∀i, 1 ≤ i ≤ k). The cost function together with the constraints on the variables xe constitute an integer programming optimization problem (specifically, the minimum multi-cut problem), the objective of which is to minimize the cost for the LFENCE insertion. For example, this algorithm would make two cuts on the condensed CFG in Figure 1, depicted as green dashed lines. These cuts represent the cheapest solution that suffices to cut all CFG paths from L1 to T1 and from L2 to T2; the cuts indicate the optimal locations to insert LFENCE instructions.
The LLVM tool uses the SYMPHONY solver1 to obtain the optimal solution, and then inserts LFENCE instructions accordingly. A similar approach has been employed for optimal insertion of fences in the context of high-performance concurrent programming.2
Obtaining the Mitigation Tools
The mitigations have been merged into the LLVM trunk, available on GitHub*; the first LLVM release that will contain the mitigations is LLVM 11. By default, the load-hardening mitigation uses a greedy heuristic that approximates the optimal minimum multi-cut. The SYMPHONY multi-cut optimization is performed by a separate plugin provided by Intel.
Footnotes
- T. Ralphs, A. Mahajan, S. Vigerske, mgalati13, LouHafer, jpfasano, A. Bulut and anhhz, "coin-or/SYMPHONY: Version 5.6.17," February 2019. [Online].
- J. Bender, M. Lesani and J. Palsberg, "Declarative Fence Insertion," in Proceedings of the 2015 ACM SIGPLAN International Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA 2015), Pittsburgh, PA, USA, 2015.
Software Security Guidance Home | Advisory Guidance | Technical Documentation | Best Practices | Resources