This article was originally published on Medium*.

Figure 1. Image generated from Stability AI* for Stable Diffusion* 2–1 with prompt “2 chat robots AI in future on mars with nice background of black hole”.
Fine-tuning of large language models (LLM) has earned a spotlight due to the rise in interest to create applications for specific language tasks like text generation, code generation, chatbots, and retrieval augmented generation (RAG). A foundation model like OpenAI GPT-4* was trained on a massive compute cluster of around 25,000 GPUs in parallel over 100 days.† Fine-tuning a model to a downstream language task can often be accomplished on a single GPU, and sometimes even a single CPU. However, training on a single node can be slow, and thus there is often a need to use multiple nodes. In this article, I give a high-level overview of how to fine-tune nanoGPT on several CPUs in parallel on Google Cloud Platform* service. Even though the implementation here is specific to nanoGPT, CPUs, and Google Cloud Platform service, the same principles apply to fine-tuning other LLMs, multiple GPUs, and any other cloud service providers (CSP). Depending on the size of the model, memory and networking requirements must also be considered for other LLMs.
NanoGPT Model
The nanoGPT model is a 124M parameter model, and an attempt to replicate the OpenAI GPT-2* model. I am showing fine-tuning with the OpenWebText dataset in a distributed setting over three 4th gen Intel® Xeon® CPUs. The objective here is not to arrive at a ChatGPT-like AI model, but rather to understand how to set up distributed training to fine-tune to a specific language objective. The end result of training here will result in a base LLM that can generate words, or tokens, suitable for a language task after further fine-tuning.
Cloud Solution Architecture
To form the cluster, the cloud solution implements Google Cloud Platform services virtual machines from the C3 series. To enable seamless communication between the instances, each machine is connected to the same virtual network. A permissive network security group is established that allows all traffic from other nodes within the cluster. The raw dataset is downloaded from Hugging Face*, and once the model has been trained, the weights are saved to the virtual machines (see figure 2).
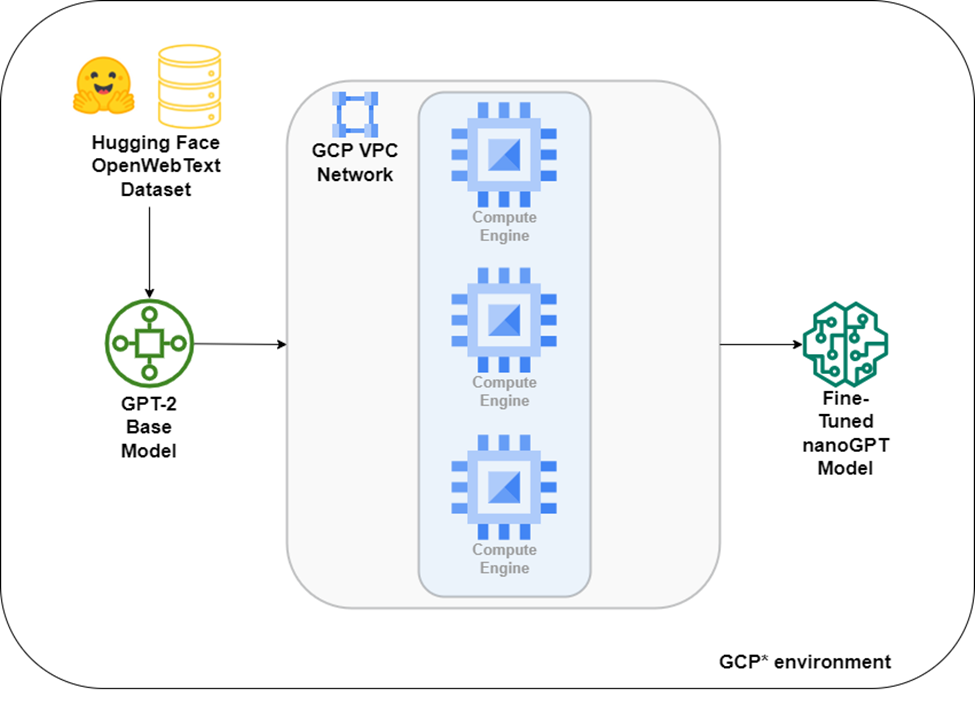
Figure 2. Reference architecture for the Intel® Optimized Cloud Module for Google Cloud Platform service: nanoGPT Distributed Training. (source: GitHub*)
Code Highlights
The Intel® Extension for PyTorch* elevates PyTorch performance on Intel hardware with the integration of the newest features and optimizations that have not yet been incorporated into open source PyTorch. This extension efficiently uses Intel hardware capabilities including Intel® Advanced Matrix Extensions (Intel® AMX). Unleashing this power is straightforward—just wrap your model and optimizer objects with ipex.optimize.
# Set up CPU autocast and bfloat16 dtype
dtype = torch.bfloat16
self.autocast_ctx_manager = torch.cpu.amp.autocast(
cache_enabled=True, dtype=dtype
)
# Wrap both PyTorch model and Optimizer
self.model, self.optimizer = ipex.optimize(
self.model, optimizer=self.optimizer,
dtype=dtype, inplace=True, level="O1",
)
The Accelerate library by Hugging Face streamlines the gradient accumulation process. This package helps to abstract away the complexity of supporting multi-CPUs and GPUs and provides an intuitive API, making gradient accumulation and clipping hassle-free during the training process.
# Initializing Accelerator object
self.accelerator = Accelerator(
gradient_accumulation_steps=gradient_accumulation_steps,
cpu=True,
)
# Gradient Accumulation
with self.accelerator.accumulate(self.model):
with self.autocast_ctx_manager:
_, loss = self.model(X, Y)
self.accelerator.backward(loss)
loss = loss.detach() / gradient_accumulation_steps
# Gradient Clipping
self.accelerator.clip_grad_norm_(
self.model.parameters(), self.trainer_config.grad_clip
)
For distributed training, I used Intel® oneAPI Collective Communications Library (oneCCL). With optimized communication patterns, oneCCL enables developers and researchers to train newer and deeper models more quickly across multiple nodes. It offers a tool called mpirun, which allows you to seamlessly launch distributed training workloads from the command line:
# Generating Multi-CPU config
accelerate config --config_file ./multi_config.yaml
# Launching Distributed Training job
mpirun -f ~/hosts -n 3 -ppn 1 -genv LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so" accelerate launch --config_file ./multi_config.yaml main.py
Conclusion
This module demonstrates how to transform a standard single-node PyTorch LLM training scenario into a high-performance distributed training scenario across multiple CPUs. To fully capitalize on Intel hardware and further optimize the fine-tuning process, this module integrates PyTorch and oneCCL. The module serves as a guide to setting up a cluster for distributed training while showcasing a complete project for fine-tuning LLMs.
We encourage you to also check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow. Learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel’s AI Software Portfolio to help you prepare, build, deploy, and scale your AI solutions.
Additional Resources
- AI Development Tools and Resources
- oneAPI Unified Programming Model
- PyTorch Optimizations from Intel
- Intel Extension for PyTorch Documentation
- Generative AI
- GitHub - Code Walk-through
- Intel®-Optimized Cloud Module Documentation
Post your model to the new Hugging Face Powered-by-Intel LLM Leaderboard and register for office hours for implementation support from Intel engineers. Join our DevHub Discord server to keep interacting with other developers.
AI Tools
Accelerate data science and AI pipelines—from preprocessing through machine learning—and provide interoperability for efficient model development.