More hardware acceleration for your neural networks
The Intel® Neural Compute Stick 2 (Intel® NCS 2) is Intel’s newest deep learning inference development kit. Packed in an affordable USB-stick form factor, the Intel® NCS 2 is powered by our latest VPU (vision processing unit) – the Intel® Movidius™ Myriad X, which includes an on-chip neural network accelerator called the Neural Compute Engine. With 16 SHAVE cores and a dedicated hardware neural network accelerator, the NCS 2 offers up to 8x performance improvement+ over the previous generation.
Software tools to accelerate deep learning inference
The Intel® Distribution of OpenVINO™ toolkit is the default software development kit¹ to optimize performance, integrate deep learning inference and run deep neural networks (DNN) on Intel® Movidius™ Vision Processing Units (VPU). (For the previous generation, developers used the Intel® Movidius NCS SDK). This toolkit supports a broad set of neural networks and streamlines deployment across not only NCS 2 hardware, but the full range of Intel vision accelerator solutions2. At the time of writing this article, this toolkit supports more than 20 pre-trained models3 covering image classification, object detection and image segmentation.
Develop on one platform, deploy across multiple
That's the mantra and simple elegance of the Intel Distribution of OpenVINO toolkit. Thanks to an intermediate representation (IR) format, you can develop and test a neural network on one type of processor such as a CPU, and deploy the same model on a range of processing units such as Intel® processors (CPU, GPU/Intel® Processor Graphics, VPU, FPGA) or even deploy heterogeneously (splitting the model) across two processors4. The IR concept allows you to run models built using multiple frameworks5 such as TensorFlow™, Caffe*, and MXNet*, and other exchange formats like ONNX*. This flexibility of supporting multiple frameworks, exchange formats and hardware accelerators is made possible due to the toolkit’s modular architecture. Below is a simplified graphical representation of the toolkit’s software components.

Intel® Distribution of OpenVINO™ Toolkit
Streamlined and easy development workflow
The toolkit has a simple development workflow, and it only takes three steps to develop and deploy a neural network on any of the supported processors and accelerators.
- Train a model on your preferred training hardware using one of the supported frameworks5.
- You can choose to use one of the many pre-trained models3 shipped with the toolkit.
- Convert the trained model into a IR file using the toolkit’s model optimizer.
- Offload the IR model onto one of the supported hardware accelerators6 to perform inference.
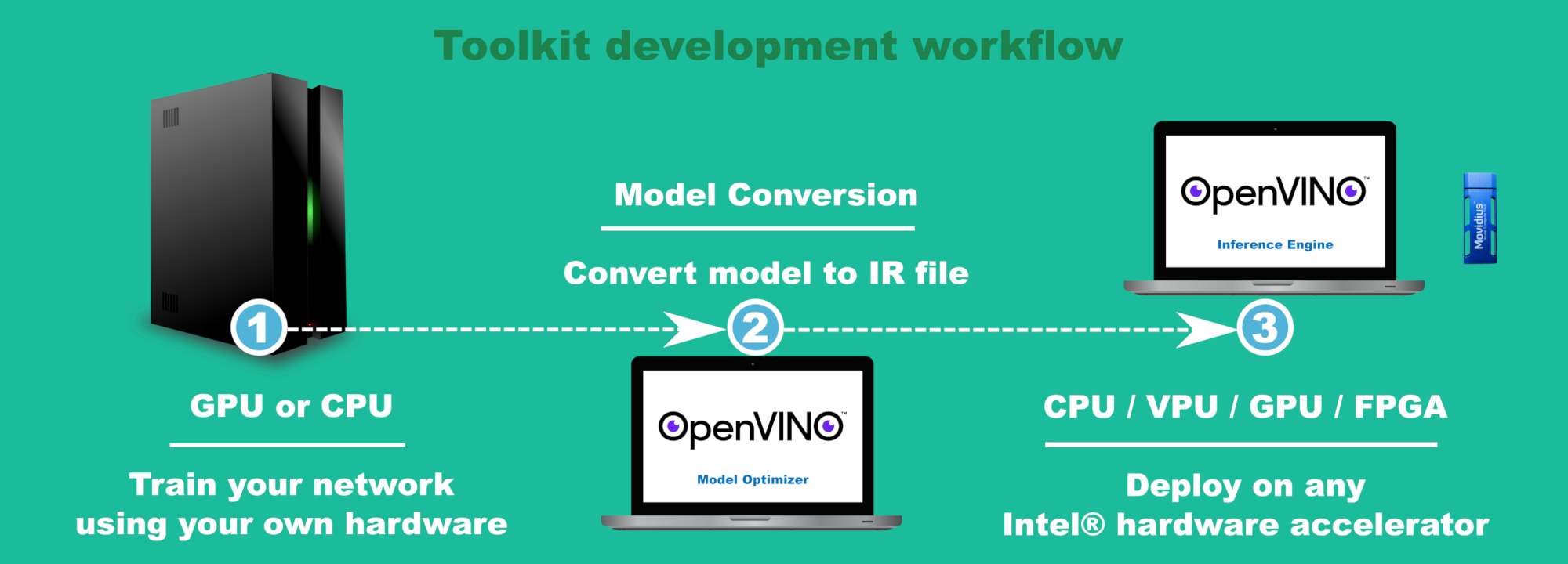
Toolkit Workflow
This article walks you through the process of building your first artificial intelligence (AI) app using pre-trained neural networks, Intel Distribution of OpenVINO toolkit, and the Intel NCS 2.
Practical Learning!
You will build...
A set of AI apps that can perform image classification7, object detection8 and image segmentation9 on Intel NCS 2.
You will learn...
- How to install and configure Intel Distribution of OpenVINO toolkit to support Intel NCS 2
- How to deploy a pre-trained neural network on Intel NCS 2
You will need...
- An Intel® Neural Compute Stick 2 - Where to buy
- An x86_64 laptop/desktop running Ubuntu 16.04 ("Development machine")
If not already done so, follow the instructions on Intel NCS 2 getting started guide to install the toolkit and Intel NCS 2 plugins on your development machine.
Let's build!
Running the toolkit's pre-trained models on Intel NCS 2
If you followed the Intel NCS 2 getting started guide, you have already run some of the pre-trained models on the Intel NCS 2. This confirms that your development machine is fully set up to convert pre-trained models to IR files, and deploy these IR files onto Intel NCS 2 using the toolkit’s inference engine API. You probably ran one example each for image classification, object detection and image segmentation.
Running publicly available pre-trained models on Intel NCS 2
The really cool thing about the deep learning community is that they have published several pre-trained models for free. Let's do our part in preventing global warming by not duplicating their efforts in re-training the same network on the same dataset that would consume power for a week or two. The below steps walk you through the toolkit's development workflow of converting publicly available pre-trained neural net models to IR files and then running them on Intel NCS 2.
Run the following commands in a terminal window
On most Linux machines, hitting `ctrl+alt+t` will open a terminal window.
Step 1: Download publicly available models that are known to work with the toolkit
cd ~/intel/computer_vision_sdk/deployment_tools/model_downloader
# List public models that are known to work with OpenVINO
python3 downloader.py --print_all
# Download a specific model, say GoogLeNet V2
python3 downloader.py --name googlenet-v2
You can run downloader.py without the --name option to download all models, but it'll take quite a while.
If the script ran fine, you should see `googlenet-v2.caffemodel` and `googlenet-v2.prototxt` in `model_downloader/classification/googlenet/v2/caffe` folder.
Step 2: Convert the downloaded pre-trained model into IR files
cd ~/intel/computer_vision_sdk/deployment_tools/model_downloader/classification/googlenet/v2/caffe
# Ensure that the OpenVINO environment is initialized
source ~/intel/computer_vision_sdk/bin/setupvars.sh
# Use model optimizer to convert googlenet.caffemodel to IR
mo.py --data_type FP16 --input_model googlenet-v2.caffemodel --input_proto googlenet-v2.prototxt
If the script ran fine, you should see `googlenet-v2.bin`, `googlenet-v2.mapping` and `googlenet-v2.xml` in `model_downloader/classification/googlenet/v2/caffe` folder.
Step 3: Deploy the converted IR model onto Intel NCS 2 using the toolkit's IE API
cd ~/intel/computer_vision_sdk/deployment_tools/inference_engine/samples/python_samples
# Download a test image from the internet
wget -N https://upload.wikimedia.org/wikipedia/commons/b/b6/Felis_catus-cat_on_snow.jpg
# Ensure that the OpenVINO environment is initialized
source ~/intel/computer_vision_sdk/bin/setupvars.sh
# Run an inference on this image using a built-in sample code
python3 classification_sample.py -m ~/intel/computer_vision_sdk/deployment_tools/model_downloader/classification/googlenet/v2/caffe/googlenet-v2.xml -i Felis_catus-cat_on_snow.jpg -d MYRIAD
If everything ran fine, you should see the below message in the terminal window. Class #173 corresponds to the 'tabby cat' class/category. Try downloading other images of tabby cat and rerunning the example.
Image Felis_catus-cat_on_snow.jpg
0.3881836 label #173
0.3193359 label #54
0.2410889 label #7
0.0361328 label #200
0.0037460 label #84
0.0025158 label #66
0.0021381 label #10
0.0016766 label #473
0.0013685 label #198
0.0007257 label #152
Congratulations! You have successfully installed and configured Intel Distribution of OpenVINO Toolkit to develop smart apps for Intel® Neural Compute Stick 2.
Further Experiments
- Okay, you just ran what I call 'the blinky code' (or 'Hello World!') example, now what? How about a 'my-first-openvino-app'? Try writing your own application using the Inference Engine API.
- At the time of writing this blog, the toolkit did not ship with a labels file which could be used to display a sensible inference result as against a class ID like #173. Try using the `--labels` flag with `classification_sample.py` to print out actual names of the inference results.
- Reference: See "BEST REPLY" in this community forum post.
Further Reading
- If you like to migrate your Intel Neural Compute SDK apps to Intel Distribution of OpenVINO Toolkit, check out this migration document.
- The Intel NCS 2 is powered by Intel Movidius MyriadX VPU which has an on-chip neural network accelerator. This hardware neural network accelerator significantly improves performance by running certain layers directly on the hardware as against splitting them into operations that run on the SHAVE DSPs. This article shows you how to optimize your Neural Networks to efficiently run on MyriadX's Neural Compute Engine.
Related links
- Intel OpenVINO toolkit site
- Intel vision accelerator solutions announcement - Oct. 10, 2018
- OpenVINO pre-trained models
- OpenVINO heterogeneous computing
- OpenVINO supported frameworks (see latest release notes)
- OpenVINO supported hardware accelerators (see 'Supported Samples' table in this document)
- Image classification sample code
- Object detection sample code
- Image segmentation sample code
+ Testing by Intel as of October 12, 2018
Deep Learning Workload Configuration. Comparing Intel® Movidius™ Neural Compute Stick based on Intel® Movidius™ Myriad™ 2 VPU vs. Intel® Neural Compute Stick 2 based on the Intel® Movidius™ Myriad™ X VPU with Asynchronous Plug-in enabled for (2xNCE engines). As measured by images per second across GoogleNetV1 and YoloTiny v1. Base System Configuration: Intel® Core™ I7-8700K 95W TDP (6C12T at 3.7GHz base freq and 4.7GHz max turbo freq), Graphics: Intel® UHD Graphics 630 Total Memory 65830088 kB Storage: INTEL SSDSC2BB24 (240GB), Ubuntu 16.04.5 Linux- 4.15.0-36-generic-x86_64-with - Ubuntu -16.04-xenial, deeplearning_deploymenttoolkit_2018.0.14348.0, API version 1.2, Build 14348, myriadPlugin, FP16, Batch Size = 1
Software and workloads used in performance tests may have been optimized for performance only on Intel® microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Performance results are based on testing as of October 12, 2018 and may not reflect all publicly available security updates. See configuration disclosure for details. No product can be absolutely secure.
*Other names and brands may be claimed as the property of others.