Machine Learning (ML) is transforming everything from scientific research to stock market predictions. ML framework TensorFlow is a flexible, high-performance serving system for machine- learning models designed for production environments.
However, from a security perspective, there are numerous issues, including how to:
- Guarantee the data and model security both in use and at rest.
- Avoid man-in-the-middle attacks.
- Verify security of the runtime hardware environment, a major concern when users deploy the TensorFlow Serving in an untrusted machine, such as a public cloud instance.
This solution presents a framework for an end-to-end PPML (Privacy-Preserving Machine Learning) solution based on Intel® Software Guard Extensions (SGX) technology.
It utilizes LibOS Gramine* to run TensorFlow Serving into Intel® SGX Enclave and provides the secure capability of protecting the confidentiality and integrity of the model at reset, establishing a secure communication link from end-user to TensorFlow Serving with mutual Transport Layer Security (TLS) authentication, providing a way for Intel® SGX platform to attest itself to the remote user. It also provides the Kubernetes* service and NGINX* for automatic load balancing, deployment, scaling, and management of containerized TensorFlow Serving so that cloud providers can easily set up the environment. Serving so that cloud providers can easily set up the environment.
Intel® SGX is Intel’s Trusted Execution Environment (TEE), which offers hardware-based memory encryption that helps isolate specific application code and data in memory. Intel® SGX allows user-level code to allocate private regions of memory, called enclaves, which are designed to be protected from processes running at higher privilege levels. Intel SGX helps protect against software attacks even if operating system, drivers, basic input/output system, virtual machine manager (VMM) or System Management Model (SMM) are compromised and helps increase protections for secrets (data, keys, etc.) even when an attacker has taken full control of the platform.
Framework
In this solution, TensorFlow Serving runs inside an Intel® SGX Enclave, with no source code changes, by integrating with LibOS Gramine. For ease of deployment, the workload is built into a Docker image. Kubernetes manages the containerized services with NGINX to provide load balance.
This solution also relies on the ECDSA/DCAP remote attestation scheme developed by Intel for untrusted cloud environments.
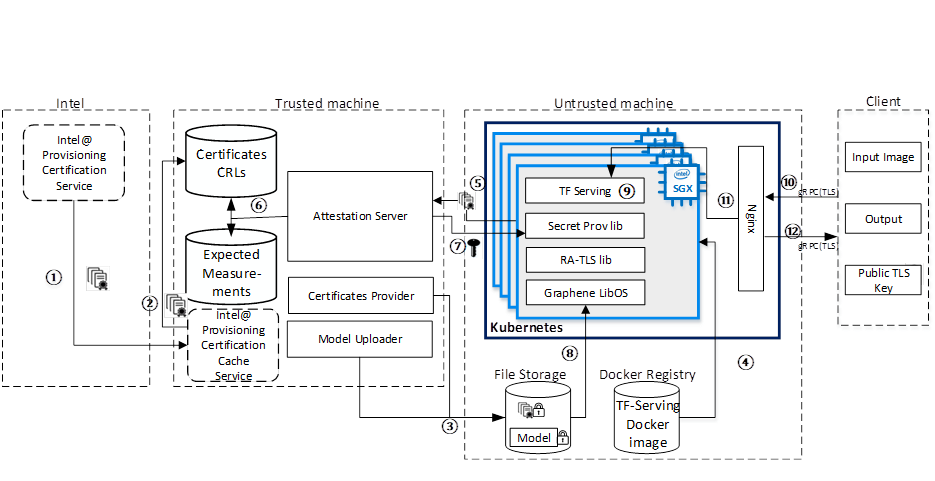
1. Remote Attestation for Intel® SGX Enclave
To verify the untrusted runtime hardware environment, the solution uses the Remote Attestation of Intel® SGX technology to verify the Intel® SGX Enclave, where the applications are running. The attesting Intel® SGX Enclave collects attestation evidence in the form of an Intel SGX Quote using the Quoting Enclave. This form of attestation is used to send the attestation evidence to a remote party.
In the solution, the form will be sent to Attestation Server ⑤ shown in Figure1. The Attestation Server then calls the library of Intel® SGX DCAP Quote verification to check the report and measurements in Intel® SGX Quote.
Before running the TensorFlow Serving application on an Intel® SGX platform, we need to set up one important module to support Remote Attestation - Provisioning Certificate Caching Service. As ① shown in Figure1, the user must retrieve the corresponding Intel® SGX certificate from the Intel® SGX Data Center Attestation Primitives (Intel® SGX DCAP), along with Certificate Revocation Lists (CRLs) and other Intel® SGX-identifying information.
2. Model Protection
To keep models out-of-enclave at-rest safe, this solution encrypts models with cryptographic (wrap) key and sends these protected files to the remote storage accessible from the Intel® SGX platform as shown ③ in Figure1.
It also uses Protected-File mode in LibOS Gramine to help guarantee the integrity of the model file by metadata checking method. Any changes of the model will have a different hash code, which will be denied by Gramine.
3. Data in-transition Protection and Secure Communication
To keep data in-transition safe, this solution establishes a secure channel by using a private key and certificate generated from the client to support avoidance of illegal access. It also encrypts the key and certificate with a wrap key to avoid any man-in-the-middle attacks and put them in TensorFlow Serving shown as ⑧ in Figure1.
4. Elastic Deployment
For automating deployment, scaling, management of containerized TensorFlow Serving and load balancing, this solution adopts Kubernetes and Ingress service. We build the TensorFlow Serving into Docker images, and the untrusted remote platform uses Kubernetes to start TensorFlow Serving inside of the Intel® SGX Enclave ⑨ shown in Figure1. Meanwhile, the user launches the Attestation Server on their own machine.
The user verifies that the untrusted remote platform has a genuine up-to-date Intel SGX processor, and that the application runs in a genuine Intel® SGX Enclave then provisions the cryptographic wrap key to this untrusted remote platform ⑦shown in Figure1.
After the cryptographic wrap key is provisioned, the untrusted remote platform may start executing the application. Gramine uses Protected FS to transparently decrypt the model files using the provisioned key when the TensorFlow Serving application starts. TensorFlow Serving then proceeds with execution on plaintext files. The client and the TensorFlow Serving will establish a transport layer security (TLS) connection using gRPC TLS with the key and certificate to do a mutual TLS authentication shown as ⑩ in Figure1.
The NGINX load balancer monitors the requests from the client and forwards external requests to TensorFlow Serving shown as ⑪ in Figure1. Once TensorFlow Serving completes the inference, it sends back the result to the client through gRPC TLS as shown in ⑫.
Conclusion
You can recreate this environment with many cloud service providers (Azure*, Google Cloud, IBM Cloud ®) or on a server that has Intel® Xeon® third generation (Ice Lake) with Intel® SGX capability.
This solution has been successfully validated on an Alibaba Cloud Elastic Compute Service (ECS) instance and a Tencent cloud instance. Alibaba cloud also called it a best practice, publishing details about it in Chinese, and you can read more about it on confidential computing zoo (CCZoo) community.
If you want to play with the code, download it on GitHub.
Acknowledgements
This post reflects the work of many people at Intel including Wu Yuan, Bu Jianlin, Hui Siyuan, Huang Xiaojun, Hu Albert, Song Edmund, Shen Cathy and our partners at the Alibaba Cloud Security team.