Abstract
With the arrival of non-volatile RAM devices, many applications are now enhanced by utilizing this memory as an intermediate level of data cache. Scaling up front end applications using Redis* and Memcached* is possible by using Intel’s DSRS containers, but developers must be aware of the technical aspects of using persistent memory before designing their software architecture. In this document I will explain some of the ideas behind persistent memory perks and how to benefit from them by choosing DSRS containers to increase the performance of end user applications and reduce hardware costs.
A Trade Off Between Memory and Performance
Imagine you have a web application for managing a company’s product inventory, and this application has the web server and the database running in different instances in the cloud. In a bad design situation, every page that requests information from a specific table would trigger the same query to the database which would result in bad performance as every request would add the network latency and the disk read latency to the amount of bytes transferred from the database to the client. These types of problems are solved by implementing memory caching.
In a memory caching design, you would want to have some amount of data closer to the client, which would increase the performance of the application but would create two other problems that we need to solve: What type of data should be cached? And how much of that data should be cached?
First let's talk about what type of data should be cached. This data is also called “hot data,” as its opposite, “cold data” is data we would not cache. There are several algorithms that determine how the data is being cached, these algorithms are also called “cache replacement policies” or “eviction algorithms.” Two of the most common are: LRU (least recently used) and LFU (least frequently used). These policies can be selected depending on the behavior of the users using the system: if the user requests data that is trendy but the trend might change over time, then LRU would be a good option, as the current trending data will be cached; if the user requests data that is always trendy, then LFU would be a better option, as the cached data tends to be the same. There are many other eviction algorithms, but it is important to know these two because they are used by the applications described later.
Next, to know how much data should be cached we need to look at the cost-capacity-speed analysis of different types of storage and memory devices. Roughly, the memory closest to the CPU is the more expensive, because it has less latency and less capacity; RAM, which has a greater capacity at a lower cost, adds latency to the data transmission; and finally we have the disk devices where we can find the cheapest storage at bigger capacities but at the lowest speeds.
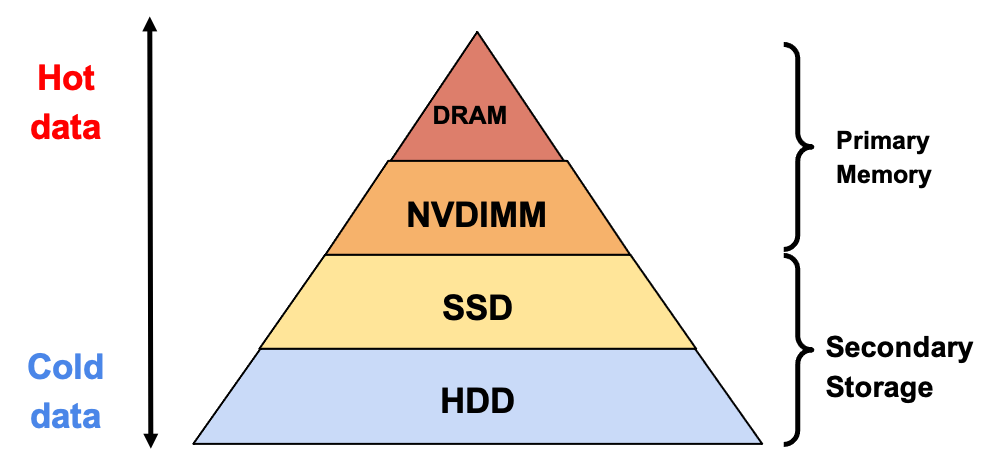
Figure 1: Comparison of storage options.
As seen in Figure 1, Intel® Optane™ DC persistent memory (PMem) modules with the DRAM form factor also known as non-volatile DIMM (NVDIMM) were developed to fill the gaps between memory speed and storage capacity. This is an affordable expansion to the traditional RAM capacity and adds low-latency access to persistent storage data.
The increased capacity of PMem allows greater storage capacity for database caches, that increased cache size results in more hot data reads which in turn will result in better performance for high demand applications.
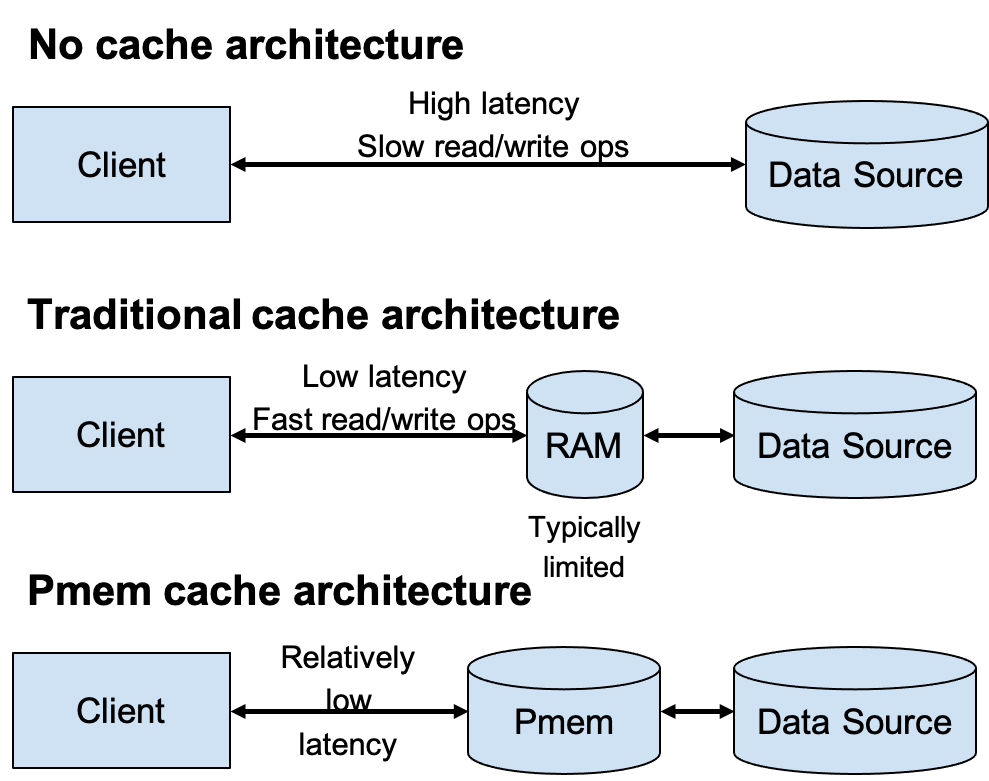
Figure 2: Cache architecture comparison
PMem Configurations
PMem memory devices are supported by the Linux* kernel since version 4.9, and can be configured in the following two different ways.
Memory Mode
In this mode, the PMem device extends the RAM available to the operating system, and access to the PMem space is transparent to the running processes, and performance would be very similar to RAM-only platforms but with a lower cost due to the increased capacity of PMem modules.
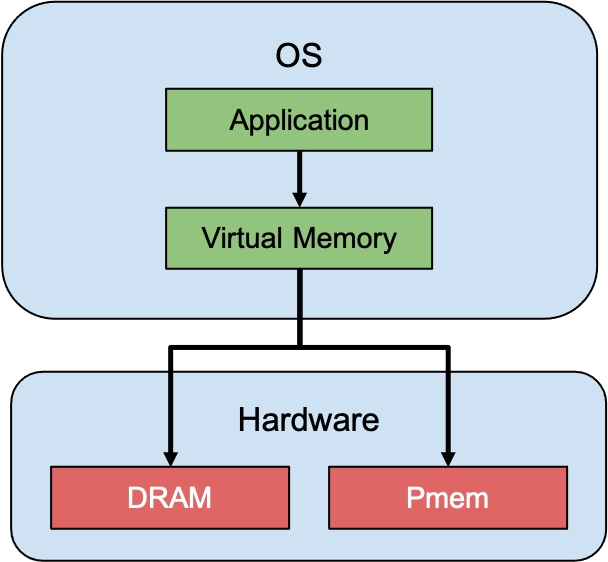
Figure 3: Memory mode
App Direct Mode
In this mode, the PMem is accessed by the operating system as a storage device, which in turn can be configured in two different modes:
Raw block device
In this mode, the PMem acts like any other storage block device, and the process will access this space using the standard file API.
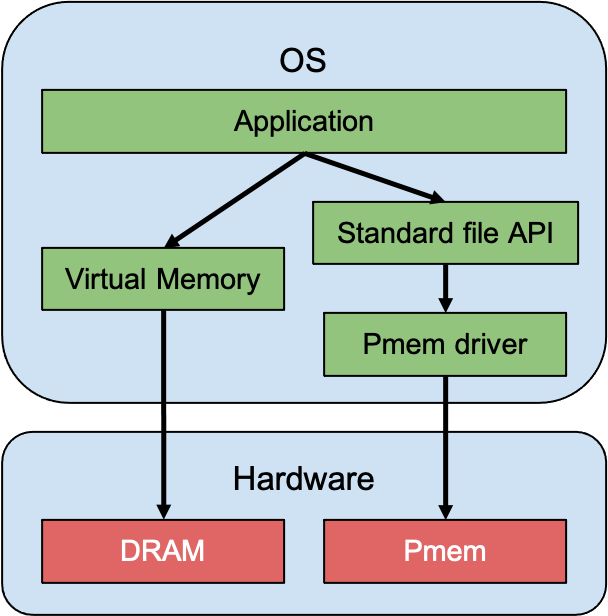
Figure 4: Raw block device mode
Direct access (DAX)
In this mode the application source code must be modified to access PMem using the libraries provided by the PMem development kit. These namespaces can be provisioned using the ndctl tool, where by default, a namespace is created in fsdax mode which creates a block device (/dev/pmemX[.Y]) that supports the DAX capabilities of Linux filesystems (xfs and ext4). But the namespace can also be created in devdax mode that emits a single character device file (/dev/daxX.Y).
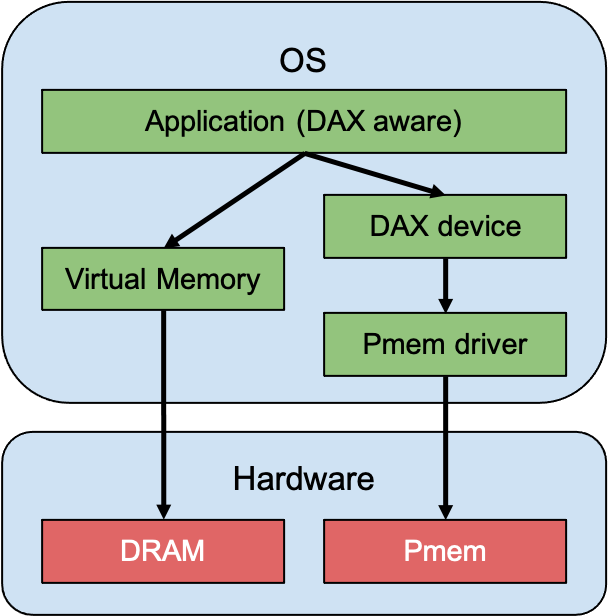
Figure 5: Direct access mode
Some source code changes to support DAX follow.
PMem Implementations for Caching Applications
There can be data caching at multiple levels, but since I’m focusing on database applications in this document, I will refer to the cache at a very high level: the cache used at RAM level for HDD or SSD storage systems. Two applications that manage this data are Redis and memcached which serve as key-value stores, meaning that they work by mapping a string, or sequence of characters (value) with an identifier (key), which is also a string. This map resides in RAM and the read-write access is seemingly faster than traditional storage. Both applications are integrated with end-to-end database applications to improve performance, and work with databases such as MySQL, Postgres, Aurora, Oracle, SQL Server, DynamoDB, and more.
While Redis adds additional features which include different data structure support and high availability clustering, memcached targets simplicity and multithreading. The choice between Redis and memcached comes down to what fits best for the end user application.
Redis approach to Using PMem
The Intel PMem team forked the source code of Redis 4.0 to include support for PMem devices only in fsdax namespaces. The main idea of this feature is to increase the storage capacity available for Redis. Traditionally Redis stores the key and its value in RAM, however the PMem implementation stores the keys in RAM and the larger values in the PMem device.
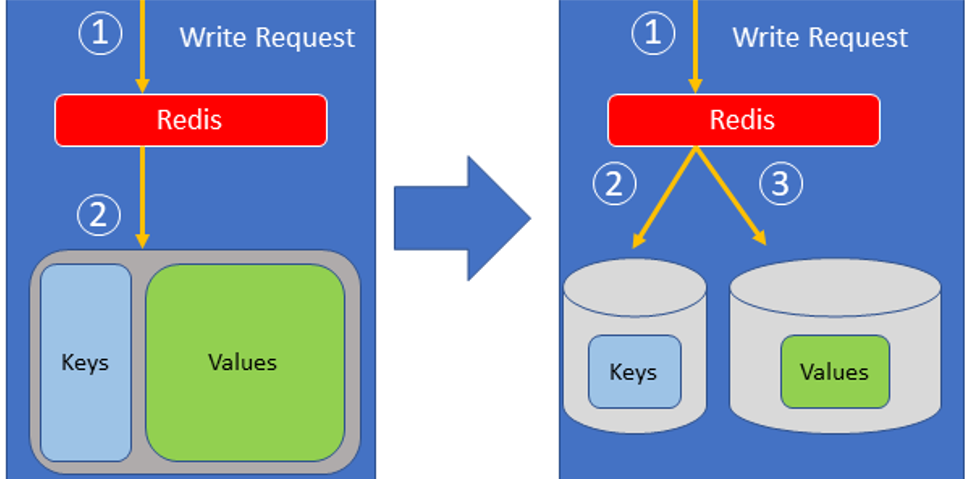
Figure 6: Comparing Redis storage architectures
The limit size used to send a value to the PMem is configurable and will depend on how much performance you will be trading off for capacity. A big threshold will fill RAM faster, but a smaller threshold will cause the application to have more latency. By default, this threshold is 64 bytes, so you need to consider the size of the values intended to be stored. If the values are small, then you will need to decrease the threshold limit, otherwise the PMem won’t be used at all.
Redis also is configurable to set a no-eviction policy (remember we described eviction policies above) meaning that it will keep all the data in memory until it is full, at which point every upcoming write request will be dropped. What eviction policy should be set for a PMem enabled Redis instance? It depends on the use case. If the PMem storage is not expected to be filled or if targeted data perfectly fits into PMem storage, then a no-eviction policy would be fine, and this will keep performance at its best.
Redis also supports snapshots of the database and appends operations to a log file. This will reduce performance but will keep data persistence. However, as PMem uses a different architecture for storing the data, data persistence mode is not supported when using PMem storage, which means that PMEM enabled Redis is intended to work as a cache system, not as a database.
Memcached Approach to PMem
One of the benefits of PMem is to actually persist data in memory after a shutdown. However, in the case of Redis’s design this is not possible since the keys are stored in RAM and they will be lost after a shutdown. This is how memcached’s approach is different.
Since version 1.5.18, memcached has included support for PMem storage in fsdax namespaces. Essentially, this feature will restore data from a file in the memory device, in what is called a “restartable cache.” To avoid data loss, the process should be stopped using a SIGUSR1 signal, so that the data remaining in memory will be flushed to the memory file on the memory disk.
DSRS Features
In September 2019, Intel’s System Stacks Team released a new containerized data services product consisting of multiple database and data analytics applications, including Redis and memcached. These are Docker* images with support for Kubernetes* environments and PMem platforms. The PMem team also created a driver to interface kubernetes with the PMem storage that can be found in pmem-csi github repository.
All the information with regard to DSRS can be found on the Intel oneContainer portal pages: DSRS Redis and DSRS memcached.
Let’s talk first about DSRS with Redis. Traditionally, a high availability Redis cluster consists of one main node with two replicas and three sentinel nodes working as the discovery system. The client first needs to query one sentinel to get the main node location in order to write to the store, then a read request can be executed in any of the store nodes.
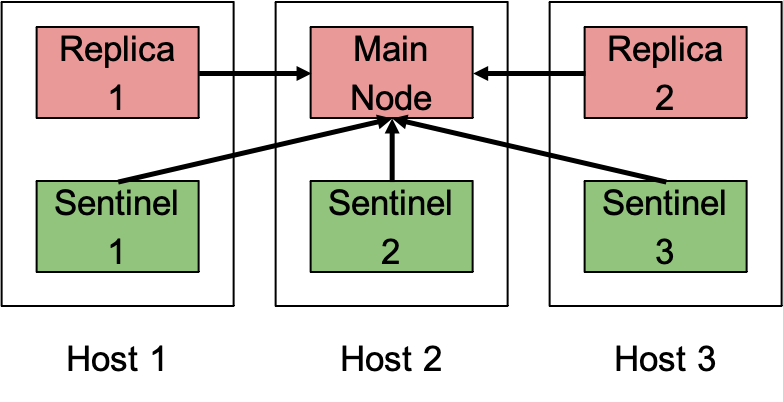
Figure 7: High availability Redis cluster example
Memcached has a simpler design and doesn’t support clustering natively, meaning that any failover techniques need to be implemented using other tools. Besides this, in order to avoid data loss in PMem, processes need to be terminated gracefully, as Kubernetes pods are usually ephemeral, and deployments, shutdowns and restarts can be very often, this means that a prestop hook must be implemented to stop the memcached service to ensure data has been flushed to the PMem storage device.
Designing PMem Cache for Databases
Now that you have a broader background in PMem implementations, the decision to use Redis or Memcached and how to configure them to use PMem will come down to how the user experience can be improved, depending on the use case of the final application.
For example, if the infrastructure where the application lives consists of resources that are constantly reallocated then the memcached feature to keep data persistence might be a good choice. On the other hand, if the infrastructure has a high tenancy demand, then the Redis feature to keep RAM usage low might be a better choice, as more Redis processes can live in fewer servers, keeping costs lower than traditional RAM-only servers.
Bottomline, why choose DSRS containers? Because they have been integrated to support PMem devices and are ready to be deployed in Docker or Kubernetes managed clouds in single node or multi node infrastructures. The DSRS Redis use of PMem devices is intended to increase cache capacity, where keeping high capacities for cache would be more beneficial to overall performance: more cache hits implies less access to secondary storage, reducing overall latency by optimizing use of the available resources. The DSRS memcached use of PMem devices is intended to replace RAM use, maintaining lower costs as PMem devices have greater storage capacity at lower cost. DSRS offers both Redis and memcached, streamlining your ability to add these applications to your stack.
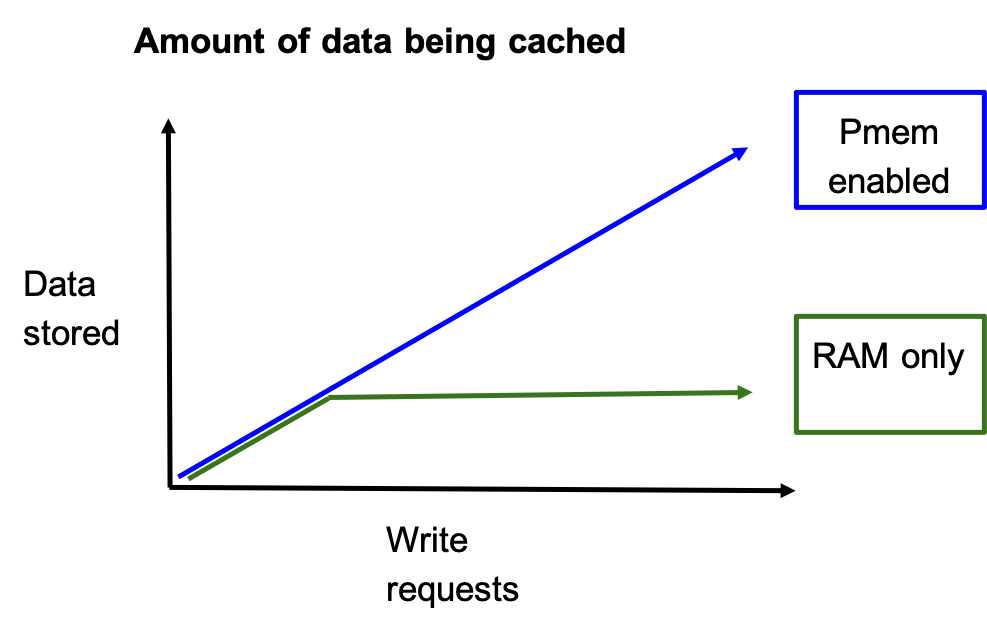
Figure 8: PMem enabled systems vs. RAM only systems
References
A study of replacement algorithms for a virtual-storage computer
Intel® Optane™ Persistent Memory
Redis
Persistent Memory is Revolutionary
Pmem-redis
Persistent Memory