When used in machine learning, images function as data to train neural networks. The more images a machine classifies, the better the learning and eventual inference. Convolutional neural networks (CNNs) classify images or elements of an image into categories. Some of the major applications of machine learning, such as object recognition, object detection, and image classification, require intensive parallel computation across large layers of convolution and classification in a neural network.
Typically, a large-scale CNN requires over a billion operations to process one input. General-purpose CPUs, sequential systems with limited computational resources, execute too inefficiently for use in CNN-based compute-intensive applications. Graphics processing units (GPUs) widely serve as hardware accelerators for training deep neural networks. However, GPUs demand too much energy for use in embedded applications.
The FPGA accelerator PipeCNN increases the computation of CNNs while performing with high-energy efficiency. Designed using large-scale CNNs, such as AlexNet* and VGGNet*, PipeCNN achieves real-time image classification and facial recognition on the Terasic DE10-Nano Kit, powered by Cyclone® V SoC FPGA. Support for OpenCL™ kernels enables users to employ high-level synthesis (HLS) tools without the expertise of programming in a hardware description language (HDL). The design takes advantage of trained neural network benchmarks along with the digital signal processing (DSP) blocks in Cyclone V SoC FPGA architecture to optimize memory usage and increase throughput.
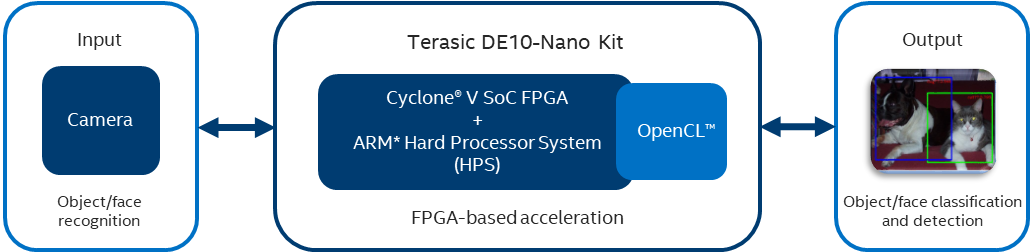
Figure 1. PipeCNN Process Flow
| Hardware |
Software |
|
|
Table 1. Terasic DE10-Nano Kit Core Components
The kernels used in the design are shown in Figure 2 and include:
- MemRD – Data-mapping kernel for reads. Reads data from the external memory.
- Conv. – Convolution kernel. Performs Multiply-Accumulate (MAC) computations of the input data.
- Pooling – Sub-sampling kernel. Progressively reduces the size of images and compute more on the output data stream from the Conv. kernel.
- MemWR – Data-mapping kernel for writes. Writes data to the external memory.
- LRN – Local response normalization kernel. Normalizes the image parameters from global memory to enhance mapping.
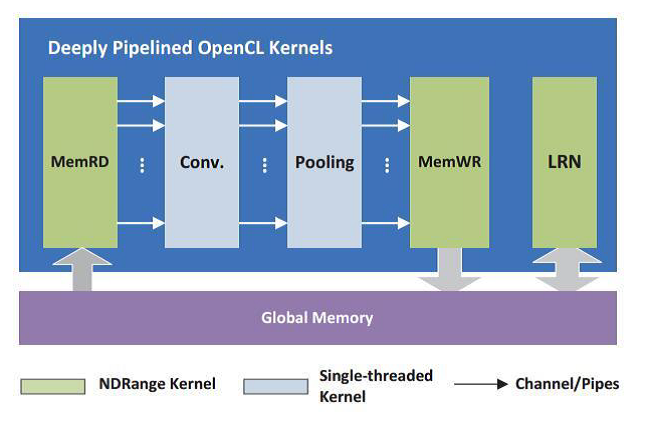
Figure 2. Pipelined OpenCL™ Kernels
Intel® FPGAs and PipeCNN in Action
Intel® FPGAs running PipeCNN provide flexible high-performance options for data scientists and other software developers.
Increase Efficiency
The PipeCNN accelerator model requires intensive parallel computing operations on the CNN to perform object and face recognition in real time. The design takes advantage of the Cyclone V SoC FPGA architecture by deeply pipelining and cascading the kernels to increase the processing of DSP blocks using the channel extension feature of the Intel® FPGA SDK. The deeply pipelined kernels in OpenCL reduce time to prototype the concept as the user does not require any expertise of an HDL to implement this model.
Boost System Performance
The design offloads computation from the ARM* processor to the Cyclone V SoC FPGA to boost the system performance. The custom kernels optimize bandwidth and maximize the DSP utilization while consuming only a small portion of the logic and on-chip memory resources. This lead to an overwhelming performance improvement on Cyclone V SoC FPGA over start-of-the-art software accelerators on mobile GPUs.
Analyze the World through Intel FPGAs
As neural networks evolve from academic research purposes to enterprise use cases, power reduction along with improvement of the technologies present hurdles. Intel FPGAs provide platforms to meet these technical challenges.
Learn more about the Terasic DE10-Nano kit.
To get started, check out the source code on GitHub* and project details.