Persistent memory technologies, such as Intel® Optane™ DC persistent memory, come with several challenges. Remote access seems to be one of the most difficult aspects of persistent memory applications because there is no ready-to-use technology that supports remote persistent memory (RPMEM). Most commonly used remote direct memory access (RDMA) for remote memory access does not consider data durability aspects.
This paper proposes solutions for accessing RPMEM based on traditional RDMA. These solutions have been implemented in the Persistent Memory Development Kit (PMDK)1 librpmem library.
Introduction
This paper contains four parts that cover the theoretical and practical aspects of RPMEM:
- Part 1 describes the theoretical realm.
- Part 2, "Remote Persistent Memory 101," depicts examples of setups and practical uses of RPMEM.
- Part 3, "RDMA Enabling for Data Replication," describes how to enable RDMA for data replication.
- Part 4, "Persistent Memory Development-Kit Based PMEM Replication," discusses PMDK-based persistent memory replication.
Before we delve into the parts, a few words about Intel Optane DC persistent memory are worth sharing.
Increasing storage performance and memory capacity requirements have led to the creation of persistent memory technologies such as Intel Optane DC persistent memory. Persistent memory allows programs to access data as memory, directly byte-addressable, while the contents are non-volatile, preserved across power cycles.
Persistent memory is an opportunity to solve existing issues by providing efficient access to large data sets. On the other hand, it comes with some new challenges for software developers. Although persistent memory can be accessible in the same way as regular volatile memory, it requires a specific treatment to leverage its non-volatility. The difficulty increases as the complexity of the application grows. The solution to this issue is the Persistent Memory Development Kit (PMDK)2, which is a collection of libraries tuned for various use cases of persistent memory.
A question that may be on a developer’s mind is, “How do I access persistent memory over the network?” To answer this question, PMDK developers created rpmem, which simplifies data replication to persistent memory.
Rpmem is in the experimental stage, which means its API may change in the future. This should be taken into consideration before using it in production.
Rpmem accesses the network interfaces through the OpenFabrics Interfaces (OFI) framework. The OFI’s libfabric library provides a unified API no matter what the underlying network hardware is. Libfabric supports various network types (providers) from which rpmem can use verbs and sockets. The verbs provider is especially useful for persistent memory solutions, as it leverages RDMA technology, which allows writing data directly to persistent memory. The use of RDMA results in high throughput, low latency networking, but it requires RDMA-capable hardware. Conversely, the sockets provider does not require special hardware and can be used on any system that supports TCP networking. Its performance is considerably less than RDMA, and it is meant for developing, testing, and debugging.
Two parties are involved in the replication process: the initiator node, which stores the data source, and the target node, which stores the replica (see Figure 1). Rpmem consists of two software parts: librpmem and rpmemd. The first one, librpmem, is a library used by an rpmem-enabled application on the initiator. The librpmem library opens a connection to the target and allows reading and writing to the target’s memory. The second one, rpmemd, is a simple application started on the target node each time librpmem opens a connection. When rpmemd is started, it waits for the connection from librpmem. When it receives a connection request from librpmem, rpmemd prepares memory according to the requested parameters. Depending on the configuration, rpmemd may or may not take part in the replication process. The rpmemd operation modes will be explained in “Two Remote Replication Methods."
Note Rpmem replication between two machines may be subject to limits established via limits.conf(5). Limits are configured on the initiator and on the target separately.
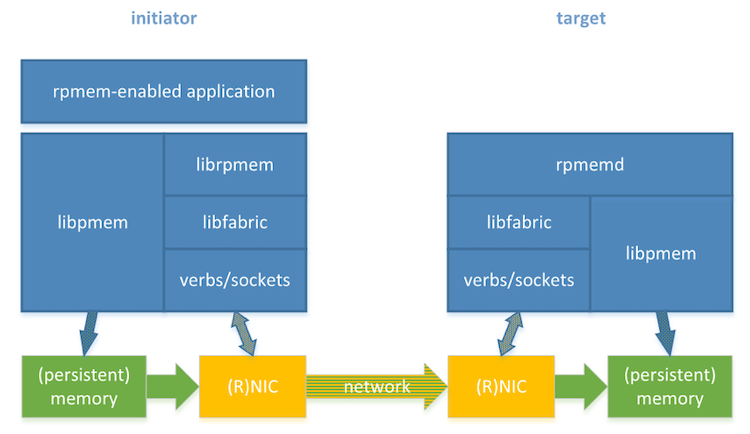
Figure 1. Rpmem software and hardware stack
Rpmem-based replication is always active-passive, which means the initiator performs writes while the target just keeps updated with the initiator. The initiator is the active part, and the target is passive.
To use rpmem replication, the first step is to set up the hardware and software components on the initiator and target, as well as the network infrastructure, to connect them. This paper aims to introduce rpmem to a wider audience by describing the necessary setup from the ground up. It describes:
- The simplest setup on a single machine using a virtual loopback network interface (no RDMA-capable hardware or persistent memory required).
- The regular rpmem setup with the replication to another machine. Both machines are linked via a regular TCP/IP network (no RDMA-capable hardware or persistent memory required).
- RDMA-capable hardware and software setup and configuration required to start using rpmem.
- How to use rpmem to replicate data over an RDMA-capable network (no persistent memory required).
- A persistent memory configuration sufficient to start using it with rpmem as a replication target.
- Leveraging RDMA capabilities to efficiently write into persistent memory on another Linux* machine (RDMA capable-network and persistent memory required).
- How to recover an application’s persistent memory contents from a replica.
Rpmem currently only supports the Linux operating system. In this paper, all the Linux administration tasks described are done using the Fedora Linux* distribution.
The following six sections describe what persistent memory is and how it can be used remotely with existing server platforms that are based on Intel® architecture and RDMA solutions.
What is Remote Persistent Memory?
Remote persistent memory (RPMEM) is largely rooted in persistent memory. Persistent memory, sometimes called storage class memory, is only recently available on modern hardware. This is due to the emergence of new technologies such as Intel Optane DC persistent memory.
Cloud and high-performance computing requires data to be moved between hundreds or thousands of physical systems. Data may be replicated across multiple nodes for redundancy and protection, or the data can be split across physical systems for performance. High-performance networking fabrics provide this interconnection between these physical systems.
The fabrics use network adapter hardware in each physical system to move the data using a point-to-point connection.
RDMA is the most acceptable technology used for remote memory access. It uses special network adapter hardware, RDMA network interface cards (RNICs), to offload the data movement from the CPU to each system’s network adapter. This improves system performance by allowing CPUs to process data, where RNICs are moving data between systems.
When moving data between physical systems, volatile DRAM memory is typically used. Once the data is written into the DRAM on a remote physical system, the system is notified that the data has been moved, and the local CPU can begin processing the new data.
Now, with Intel Optane DC persistent memory, it is possible to replace the volatile DRAM in the system with persistent memory. This allows us to use RDMA for persistent memory instead of DRAM.
RPMEM combines the advantages of two related technologies. It allows remote persistence, as was possible until now only with classical storage technologies, without losing any of properties characteristic of memory.
RDMA Basic Architecture
This section outlines the basic architecture for RDMA with Double Data Rate Dynamic Random-Access Memory (DDR DRAM) in a typical IA-based server platform.
RDMA Introduction
Remote direct memory access, or RDMA, is fundamentally an accelerated I/O delivery mechanism that provides zero-copy data placement. It allows RNICs to transfer data directly between the user memory on the Initiator and the user memory on the Target while bypassing the OS kernel stack. Bypassing the kernel saves costly context switches between kernel space and application space and improves latency. Since the direct memory access (DMA) operation is set up and performed by the RNICs' DMA engine, the data movement is offloaded from the Initiator and the Target server CPUs, freeing them up for other tasks. RDMA also bypasses the host system’s software TCP/IP stack, which improves latency and performance.
Figure 2 gives an overview of a typical system using RDMA technology. Every node is equipped with RNIC also known as Host Converged Adapter—the hardware that represents the network adapter present on the node of a point-to-point network connection. The PCIe* bus is used to exchange data between RNIC and other components in a node. That mainly is an integrated memory controller (IMC) with the support of DMA technology, but depending on the system configuration, it could also be an L3 CPU cache. Initiator node is the one that controls data transmission from its memory to the memory of the Target node. Software applications and libraries are those that produce and consume data exchanged between two nodes.
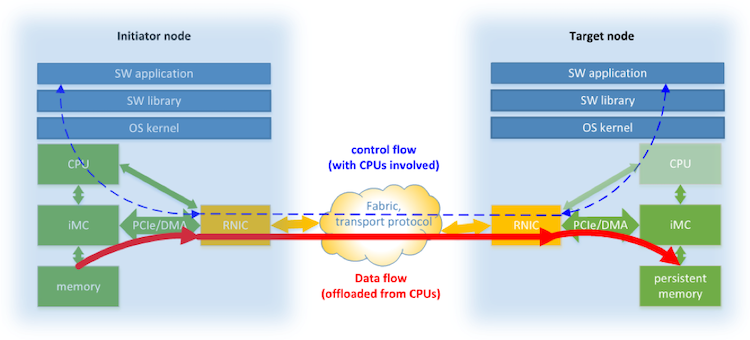
Figure 2. RDMA system elements
RDMA Two-Sided Send and Receive
The most basic RDMA messaging between an Initiator node and a Target node uses the two-sided RDMA Send/Receive message. A two-sided message is one in which both the Initiator and the Target must supply information for the data transfer to take place. The Initiator RNIC is responsible for providing the source buffer address (where data will be copied from) and the Target RNIC is responsible for providing the sink buffer address (where the data will be copied to).
RDMA One-Sided Read
The RDMA architecture supports an RDMA Read operation. This operation is considered a one-sided operation since the Initiator supplies both the source buffer address and the sink buffer address for the operation. There are two messages associated with an RDMA Read operation. The first RDMA Read message (from Initiator to Target) will contain a tag that identifies the Target node’s source buffer, where the data will be DMA’d from and a second tag that identifies the Initiator node’s sink buffer, where the data will be DMA’d to. The Target RNIC utilizes the source tag to set up the local DMA operation. The Target NIC then sends a second message (to the Initiator) that contains the data payload from the source buffer. The message header will contain the tag for the sink buffer in the Initiator node, which the Initiator RNIC uses to set up and complete the DMA operation.
RDMA One-Sided Write
RDMA Write is another operation supported by the RDMA architecture. This operation is considered a one-sided operation since the Initiator supplies both the source buffer address and the sink buffer address for the operation. There is one message associated with an RDMA Write operation. The RDMA Write message (from the Initiator to the Target) contains the data payload from the source buffer. This message is where the actual DMA operation takes place between the two RDMA NICs. The message header will contain the tag for the sink buffer in the Target node, which the Target RNIC uses to set up and complete the DMA operation.
Durability Versus Visibility
There are several Intel-specific mechanisms built into the chipset hardware that are considered when defining the way that traditional RDMA works with persistent memory.
Data Visibility Versus Data Durability Points
When working with persistent memory, software applications need to differentiate between data visibility and data durability points.
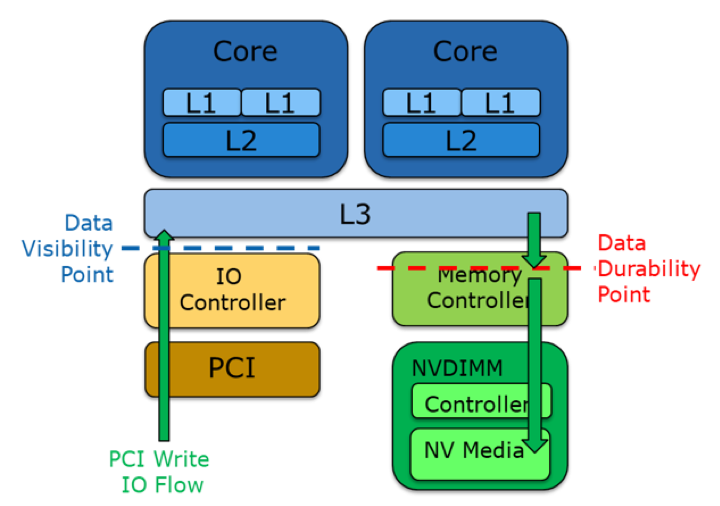
Figure 3. Data visibility versus data durability on the Target node1
The data visibility point is a software application execution point where I/O data could be directly used by a CPU while software execution and acknowledgement of the data durability point ensure that data is stored into persistent memory and will persist across a power failure.
Intel® Data Direct I/O Technology (Intel® DDIO)
To improve data visibility performance, Intel® DDIO3 has been introduced with the Intel® Xeon® E5 processor and Intel® Xeon® E7 processor v2 as a key feature of Intel® Integrated I/O. Intel created Intel DDIO to allow Intel® Ethernet controllers and adapters to communicate directly with the processor.
Intel DDIO makes the processor cache the primary destination and source of I/O data rather than main memory, helping to deliver increased bandwidth, lower latency, and reduced power consumption.
Additional hardware allows the source and/or sink buffers for any I/O operation (including PCIe/RDMA access) to be located in the last level cache (LLC/L3) of a CPU. This allows I/O Read or Write sequence to be shortened, since the data does not need to be pushed out to DRAM before starting the read operation. Likewise, the data after the Write operation does not need to be pulled into the cache before the CPU can use the data. Additionally, that I/O operation utilizes LLC with much shorter access time than system memory. This removes a significant number of clock cycles from the PCIe (RDMA) I/O path.
Intel DDIO provides significant I/O performance improvement but makes more complex the way in which the data durability point can be reached. Additional steps are needed in the software to ensure data durability. CLWB instruction combined with SCFENCE do the work from the CPU point of view by forcing cache lines to be pushed to the integrated memory controller, which is already under protection of the so-called asynchronous DRAM refresh (ADR) domain (described below).
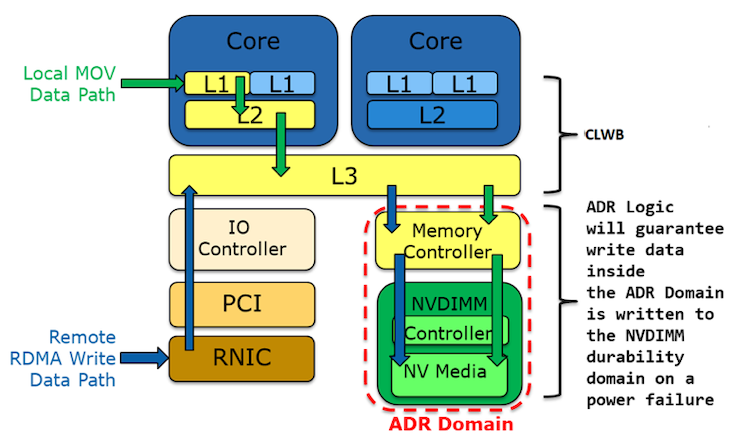
Figure 4. Pushing data to the ADR domain4
Asynchronous DRAM Refresh
Asynchronous DRAM Refresh (ADR) is a combination of hardware signal routing on the motherboard, an ADR capable power supply, and a specific set of environmental conditions. ADR provides logic to push all data within the IMC into the non-volatile dual in-line memory module (NVDIMM) before capacitive power is lost. Since the data must already be resident in the IMC, the IMC is considered the ADR domain. This feature is crucial from all durability mechanisms outlined later in this document.
Non-Allocating PCIe* Writes Requests
There is an alternative to the above-mentioned method to push I/O data directly to the ADR domain. The Intel Integrated I/O controller hardware can be placed in a mode where incoming PCIe Writes will use non-allocating buffers for the Write requests. Non-allocating Writes are guaranteed to bypass all of the CPU caches (L1, L2, and L3/LLC) and force the Write requests to flow directly to the iMC without detour. However, it should be considered that there is a performance penalty associated with the use of these types of Writes. Depending on particular hardware configuration, non-allocating PCIe Writes could be configured either on the system level (not recommended due to performance penalty affecting all PCIe devices) or on the PCIe bus level (PCIe root port).
PCIe Read Fence of Previous PCIe Writes
The PCIe write request to system memory, for example, after receiving the RDMA Write, can skip CPU caches when non-allocating Write flow is enabled on the Target node. However, Write could be still buffered due to the memory cache control mechanism (Write combined buffer) supported by Intel® 64 and IA-32 architecture. Additional steps must be executed to ensure completion of the PCIe Write request. With PCIe based I/O transactions, the Intel Integrated I/O in the Intel® hardware will flush all previous PCIe Writes to the IMC before executing the PCIe Read request. This fencing of Writes by the Read request can only be utilized when the Write requests were executed with non-allocating Writes enabled.
Note Check in the Target node Read fencing configuration as PCIe Read fencing could be disabled in a system configuration.
RDMA with Persistent Memory
The fundamental issue with RDMA and persistent memory is that RDMA does not provide any direct way of notifying the Initiator that its RDMA Write reached the ADR domain on the Target node.
Additionally, there are three general issues that must be considered regarding RPMEM over RDMA:
- Intel DDIO influence on an RDMA Write request
- Data buffering that could occur in several points of the data transport chain
- Data atomicity that is not supported by the RDMA Write operation
This section describes in detail how particular problems are resolved with the use of traditional RDMA.
Intel DDIO Influence on RDMA Write to Persistent Memory
With Intel DDIO, enabled CPU cache is the primary destination for I/O data, rather than main memory. That makes a shorter path for data delivered via RDMA to be available for the CPU to process, but does not ensure that data is stored in the ADR domain. To ensure direct RDMA data is stored in the ADR domain, either the Intel DDIO mechanism should be disabled on the Target node, or dedicated software should enforce proper execution of CLWB/SFENCE for data delivered with an RDMA Write request. A separate sequence of two RDMA Send commands is used for that purpose:
- RDMA Send from the Initiator node to the Target node with an address already modified by the RDMA Write memory region; the address is used to evict cached memory (with a sequence of CLWB/SFENCE) as it is described in “Durability Versus Visibility.”
- RDMA Send from the Target node to the Initiator node about successfully pushed data out of CPU caches to ADR domain confirms data durability.
Data Buffering
RDMA Write completion is generated on the Initiator node as soon as the source data buffer could be used for another purpose and does not guarantee anything about actual RDMA Write transmission. When completion is generated data could be copied only to local RNIC buffers, or could be stored temporarily in the Target node RNIC buffer, or could be finally buffered due to the memory cache control mechanism (see “Durability Versus Visibility”) on the Target node. The RDMA based solution should force flushing of all possible buffers before a remote Write to persistent memory could be concluded.
There are two mechanisms defined in the RDMA specification that force RNIC buffers flushing. These are RDMA Read operation or RDMA Send operation used in context of the same RDMA connection.
It is important to notice that RDMA Read also solves the problem of data buffering on a PCIe bus. RDMA Read uses PCIe Read to access persistent memory and that Read operation fences any pending PCIe Write operation.
Write Atomicity
IA server ensures 8 bytes atomicity when accessing persistent memory locally. That is not valid for the RDMA Write operation. The only way to ensure 8 bytes atomicity in case of remote Write to persistent memory is to do this via a dedicated software component in the Target node. RDMA Send service is used for that purpose. RDMA Send message delivers data to be stored together with information where they should be stored. Atomic local Write is executed (with a maximum of 8 bytes atomicity) and the operation result is sent back as a separate RDMA Send message to the Initiator node.
Two Remote Replication Methods
Two methods for writing to RPMEM have been defined when considering the latest IA server platforms and traditional RDMA solution:
- Appliance remote replication method (ARRM), formerly known as Appliance Persistency Method (APM)
- General-purpose remote replication method (GPRRM), formerly known as General Purpose Server Persistency Method (GPSPM)
In both persistency methods, 8-byte atomicity (if it is required) is guaranteed using the same mechanism. For details, see “RDMA with Persistent Memory."
Appliance Remote Replication Method
Appliance remote replication method (ARRM) is the most powerful way to access and write RPMEM with support of traditional RDMA services. It is being used only when non-allocating writes are configured on the PCIe on the Target node (see “Durability Versus Visibility”).
ARRM includes two steps: a sequence of RDMA Write operations is followed by one RDMA Read operation when the Initiator software inserts a durability point (RDMA Read address and length does not matter). The RDMA Read is sent on the same connection as all of the previous RDMA Writes.
In this method, non-allocating Writes ensure that data reach a memory controller as soon as they are pushed out from the NIC—what is ensured by RDMA Read and PCIe Read fencing mechanism.
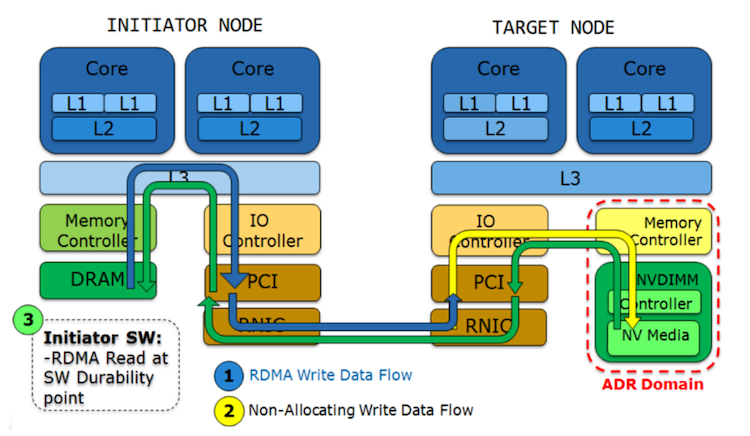
Figure 5. Appliance remote replication method4
General-Purpose Remote Replication Method
General-purpose remote replication method (GPRRM) must be utilized whenever the PCI bus of the Target node uses allocating Writes—Intel DDIO is enabled (see “Durability Versus Visibility”).
GPRRM comprises two steps: (1) a sequence of RDMA Write operations is followed by one RDMA Send message and (2) when the Initiator software inserts a durability point. This message payload includes the address and length of modified memory. The Target node evicts all modified memory from the cache and notifies the Initiator software (using another RDMA Send) that data has been successfully stored in persistent memory. The RDMA Send message must be sent on the same connection as all of the previous RDMA Write(s).
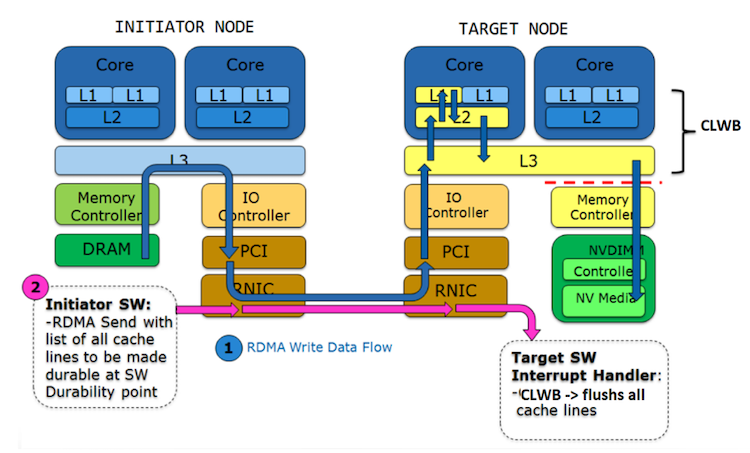
Figure 6. General-purpose remote replication method4
librpmem Architecture Overview
ARRM and GPRRM are implemented as part of the PMDK. That includes the librpmem library that handles the Initiator side control and data flow, and the rpmemd utility running on the Target node.
The librpmem provides low-level support for remote access to persistent memory utilizing RDMA-capable RNICs. The library is used to replicate, remotely, a memory region over RDMA protocol. It utilizes an appropriate persistency mechanism based on the remote node’s platform capabilities. The librpmem utilizes the ssh client to authenticate a user on the remote node and for encryption of the connection’s out-of-band configuration data. The librpmem library is based on libfabric library API.
The rpmemd process is executed on the Target node by the librpmem library over ssh and facilitates access to persistent memory over RDMA. The rpmemd dynamically chooses the appropriate persistency method—ARRM or GPRRM. It supervises the target persistency memory area by blocking other process access to the selected memory mapped file, and additionally executes cache flushing in case of GPRRM.
Proceed to Part 2, "Remote Persistent Memory 101," which depicts examples of setups and practical uses of RPMEM.
Other Articles in This Series
Part 3, "RDMA Enabling for Replication," describes how to enable RDMA for data replication.
Part 4, "PMDK-Based Persistent Memory Replication," describes how to create and configure an application that can replicate persistent memory over an RDMA-capable network.
Footnotes
1. "Persistent Memory Development Kit," [Online]. Available: https://github.com/pmem/pmdk.
2. "Persistent Memory Programming," [Online]. Available: http://pmem.io.
3. Intel Corporation, "Data Direct I/O FAQ," [Online]. Available: https://www.intel.com/content/dam/www/public/us/en/documents/faqs/data-direct-i-o-faq.pdf.
4. C. Douglas, "RDMA with PMEM: Software mechanisms for enabling access to remote persistent memory," in Storage Developer Conference, 2015.