Introduction
Intel® Integrated Performance Primitives (Intel® IPP) library, a component of the Intel® oneAPI Base Toolkit provides several functions for optimized ZFP compression and decompression for 3D 32-bit floating point arrays. ZFP is a loslless and lossy data compression method for various data types and data dimensions from 1 to 4. Intel® IPP functions for ZFP are single-thread functions, nevertheless their interface (API) allows using of these functions in multi-thread compression and decompression applications. This article will show you how to perform compression and decompression operations.
Starting with ZFP version 0.5.4, the original library supports parallel compression using OpenMP* functionality. Intel® IPP supports parallel execution in open-source ZFP library with source code patch file released with Intel® IPP product. However, for applications implementing direct Intel® IPP function calls there is easy ways to parallelize execution of compression and decompression operations.
Intel® IPP ZFP Functions Collection
The description of Intel® IPP functions for ZFP can be obtained from Intel® IPP developer reference guide.
Below is a simplified list of Intel® IPP ZFP functions with a short description of each function.
| Function | Description |
|---|---|
| ippsEncodeZfpGetStateSize_32f | Returns size of structure (ZFP state) where service information for encoding (compression) functions will be kept. Allocated and freed by user’s application. |
| ippsEncodeZfpInit_32f | Initializes ZFP state structure for encoding. |
| ippsEncodeZfpInitLong_32f | Initializes ZFP state structure for encoding for huge data arrays more than 2GB. |
| ippsEncodeZfpSet_32f | Sets various parameters for encoding operation. |
| ippsEncodeZfpSetAccuracy_32f | Sets accuracy for encoding. |
| ippsEncodeZfp444_32f | Compresses 4x4x4 block of 32-bit FP values and flushes compressed data into user’s buffer. |
| ippsEncodeZfpFlush_32f | Flushes remaining bits from ZFP state to user’s buffer. Should be called last in encoding sequence. |
| ippsEncodeZfpGetCompressedSize_32f | Returns size of compressed data in bytes. |
| ippsEncodeZfpGetCompressedSizeLong_32f | Returns size of compressed data for huge arrays. |
| ippsEncodeZfpGetCompressedBitSize_32f | Returns size of compressed data in bits. Helpful for parallel compression. |
| ippsDecodeZfpGetStateSize_32f | Returns size of structure (ZFP state) where service information for decoding (decompression) functions will be kept. Allocated and freed by user’s application. |
| ippsDecodeZfpInit_32f | Initializes ZFP state structure for decoding. |
| ippsDecodeZfpInitLong_32f | Initializes ZFP state structure for decodingt for huge data arrays more than 2GB. |
| ippsDecodeZfpSetAccuracy_32f | Sets accuracy for decoding. |
| ippsDecodeZfpSet_32f | Sets various parameters for decoding operation. |
| ippsDecodeZfp444_32f | Decompresses 4x4x4 block of 32-bit FP values and flushes compressed data into user’s buffer. |
| ippsDecodeZfpGetDecompressedSize_32f | Returns size of decompressed data in bytes. |
| ippsDecodeZfpGetDecompressedSizeLong_32f | Returns size of decompressed data for huge data arrays. |
In our examples in this article we will be using rather small data arrays and non-Long functions.
The source snippets below won’t be a complete application but examples of code lines. The code snippets are based on example from readme file for Intel® IPP ZFP interface. You can find the example in the product package of Intel® IPP.
The complete example of parallel compression and decompression using Intel® IPP ZFP with time measurements, please refer to the link provided at the end of this article.
Compression Modes in ZFP
In this article we will be using two compression modes from ZFP set: fixed accuracy and fixed rate. Fixed accuracy mode means that the absolute differences between source data point and decompressed data point shouldn’t be greater than a pre-set limit. Fixed rate mode means that each 4x4x4 block will be compressed into pre-set number of bits. Fixed accuracy mode allows to obtain higher compression ratio, because each compressed block will occupy different size in bits depending of block values (the least number of bits generated for block consisting of all zeros). In fixed rate mode each compressed block occupies the equal number of bits.
For parallel decompression only fixed rate mode can be used by now, because we can calculate the beginning of each compressed block in compressed data and we can use this address to start decompression with.
Fixed accuracy mode can be used in parallel compression only, the resulting compressed data buffer cannot be used for parallel decompression, because we don’t know and cannot calculate the beginning address of desired compressed block.
The enhancement of parallel ZFP decompression to modes other than fixed rate requires changes in compressed format to include some meta-data in order to proper positioning of decompression threads before processing.
Initialization of Data Arrays and Intel® IPP ZFP functionality
#include <ippdc.h>
#include <ipps.h>
int main()
{
Ipp32f *pSrcArray /* source data */, *pDstArray /* decompressed data */;
Ipp8u *pBuffer /* buffer for all threads */,
*pMergeBuffer /* final accumulating buffer */;
int nx = 200, ny = 200, nz = 200; /* data dimensions */
int numFloats = 0; /* total number of FP values in pSrcArray and pDstArray */
numFloats = nx * ny * nz;
In the next step, we need to allocate arrays and initialize source data.
pSrcArray = ippsMalloc_32f(numFloats);
pDstArray = ippsMalloc_32f(numFloats);
InitSrcArray(pSrcArray, nx, ny, nz);
Allocate compression buffers for threads and accumulating buffer. Each thread will compress its data chunk to separate buffer (separate area within pBuffer) and then we will need to merge thread buffers into final compression buffer.
int bufLen = (IppZFPMAXBITS + 7) / 8; /* Max bytes per 4x4x4 block */
bufLen *= (numFloats + 63) / 64;
pBuffer = ippsMalloc_8u(bufLen);
pMergeBuffer = ippsMalloc_8u(bufLen);
IppZFPMAXBITS is a macro definition from Intel® IPP header file.
Call the Compression Function.
Compress(threads, pSrcArray, nx, ny, nz, accuracy, ratio, pBuffer, pMergeBuffer, &comprLen);
The Compression function Compress is multi-threaded with OpenMP* and the compression mode is switched between “fixed accuracy” and “fixed rate” depending on the accuracy value (if value is greater than 0, fixed accuracy is used). The decompression function Decompress is executed in parallel or serial mode depending on chosen compression mode, the switching between decompression modes (and, thus, between parallel and serial execution) is controlled by accuracy value.The other parameters are:
- threads – number of threads to use for parallel execution.
- pSrcArray – initialized source data array.
- nx, ny, nz – dimensions of data array.
- accuracy – absolute value of precision to keep during compression
- ratio – desired compression ratio for fixed rate mode
- pBuffer – thread-related buffer (number of chunks equal to number of threads).
- pMergeBuffer – buffer to accumulate resulting compressed data.
- comprLen – integer variable to get total size of compressed data.
Call the Decompression function and get absolute error value.
Decompress(threads, pMergeBuffer, comprLen, nx, ny, nz, accuracy, ratio, pDstArray);
/* Absolute error calculation */
double maxErr = 0.;
for (i = 0; i < numFloats; i++) {
double locErr = fabs(pSrcArray[i] - pDstArray[i]);
if (locErr > maxErr) maxErr = locErr;
}
Parallel Compression Function with Intel® IPP ZFP
For proper compression in multi-thread environment, we need to do the following:
- Allocate ZFP state structures, one per thread.
- Initialize all ZFP states with proper values. This relates to calculation of partial destination addresses (initial addresses for compression by chunks).
- Split source data buffer into chunks of blocks of 4x4x4 values. The chunks must not overlap. If the final blocks of a chunk are not complete (less than 4x4x4) we need to use temporary zero-initialized 64 *xfloat buffer to compress margin blocks .
- Execute compression of chunks in parallel.
- Merge partial compression buffers into single final buffer.
Let’s look at the Compress function in features.
void Compress(int threads, const Ipp32f* pSrc, int maxX, int maxY, int maxZ, Ipp64f accuracy, double ratio, Ipp8u* pChunkBuffer, Ipp8u* pDst, int* pComprLen)
{
int encStateSize; /* Encoding ZFP state size obtained from Intel® IPP function */
Ipp8u* pEncState; /* Buffer for all ZFP states for all threads,
number of chunks = number of threads */
ippsEncodeZfpGetStateSize_32f(&encStateSize);
pEncState = (Ipp8u*)ippsMalloc_8u(encStateSize * threads);
Here we allocated buffer for all ZFP states.
const int maxBytesPerBlock = (IppZFPMAXBITS + 7) / 8;
In the above snippet the offset is in bytes to the start positions of each thread compression buffers. Number of 4x4x4 blocks for all 3 dimensions are as follows:
int bx = (maxX + 3) / 4;
int by = (maxY + 3) / 4;
int bz = (maxZ + 3) / 4;
int blocks = bx * by * bz;
Below is source code for ZFP state initialization:
int blocksPerThread = blocks / threads;
const int maxBytesPerThread = maxBytesPerBlock * blocksPerThread;
for (i = 0; i < threads; i++) {
int offset = i * maxBytesPerThread;
IppEncodeZfpState_32f* pState = (IppEncodeZfpState_32f*)(pEncState + i * encStateSize);
ippsEncodeZfpInit_32f(pChunkBuffer + offset, maxBitsPerThread, pState));
if(accuracy > 0)
ippsEncodeZfpSetAccuracy_32f(accuracy, pState);
else {
unsigned int bits = GetBitWidth(ratio);
ippsEncodeZfpSet_32f(bits, bits, IppZFPMAXPREC, IppZFPMINEXP, pState);
}
}
The beginning of partial compression buffer for thread N is equal to N * maxBytesPerThread.
The next step is compression. For simplicity let’s assume that nx, ny and nz are multiple of 4.
int yStep = maxY, zStep = maxX * maxY;
#pragma omp parallel for num_threads(threads)
for(chunk = 0; chunk < threads; chunk++)
{
int blockMin = blocksPerThread * chunk;
int blockMax = blocksPerThread * (chunk + 1);
if (chunk == (threads - 1))
blockMax += blocks % blocksPerThread;
int block;
for (block = blockMin; block < blockMax; block++) {
int x, y, z;
int b = block;
x = 4 * (b % bx); b /= bx;
y = 4 * (b % by); b /= by;
z = 4 * b;
const Ipp32f* p = pSrc + x + yStep * y + zStep * z;
ippsEncodeZfp444_32f((const Ipp32f *)p, yStep * sizeof(Ipp32f),
zStep * sizeof(Ipp32f),
(IppEncodeZfpState_32f*)(pEncState + chunk * encStateSize)));
}
}
We don’t check Intel® IPP function return status for code simplicity.
To allow seamless decompression, we need to append partial compression buffers from chunk compression into a single compression buffer pDst. Because of ZFP compression mode used – fixed accuracy – the compressed data lengths for each buffer is different, moreover, the buffer ends are not byte-aligned. Thus, we need to use bit-wise copy, i.e. bit number 0 of chunk N+1 should go right after last compressed bit of chunk N. For this we will be using bit-copy function from Intel® IPP.
int totalBits = 0, totalBytes = 0, dstBitOffset = 0, byteSize;
for (chunk = 0; chunk < threads; chunk++) {
Ipp64u bitSize;
IppEncodeZfpState_32f* pState = (IppEncodeZfpState_32f*)(pEncState + chunk * encStateSize);
ippsEncodeZfpGetCompressedBitSize_32f(pState, &bitSize));
ippsEncodeZfpFlush_32f(pState));
ippsEncodeZfpGetCompressedSize_32f(pState, &byteSize));
ippsCopyBE_1u(pChunkBuffer + chunk * maxBitsPerThread, 0,
pDst + (totalBits / 8), dstBitOffset, (int)bitSize));
totalBits += (int)bitSize;
dstBitOffset = totalBits & 7;
}
ippsFree((IppEncodeZfpState_32f*)pEncState);
/* Reset rest of bits in last byte */
totalBytes = (totalBits + 7) / 8;
pDst[totalBytes-1] &= (1 << (totalBits & 7)) - 1;
*pComprLen = totalBytes;
Note, that GetCompressedBitSize function should be called before ZfpFlush function, because flushing changes compressed size in bits. The CopyBE_1u function copies source buffer to destination buffer bit by bit.
The last three lines of code reset unused bits of the very last byte.
The parallel execution results for 600x600x600 source data block are:
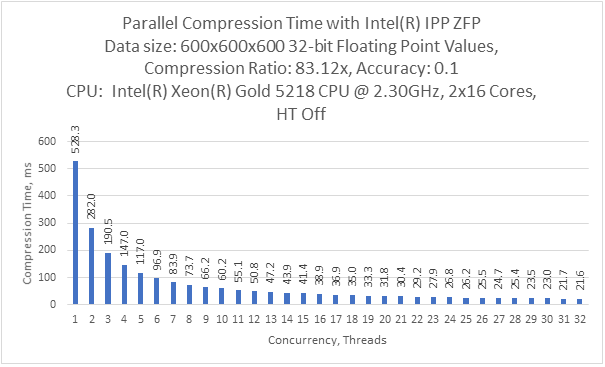
Compression performance and ratio highly depend on desired accuracy chosen. For example, the graph for accuracy 1e-6:
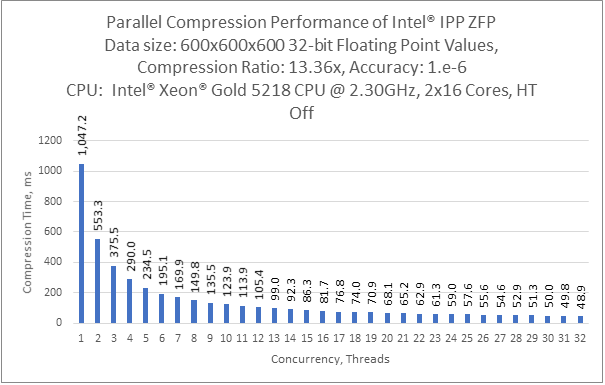
Parallel Decompression Function with Intel® IPP ZFP
For parallel decompression, each decompressing thread must know starting address of its compressed data to start decompression. Current open source ZFP implementation does not have metadata, or stream format to keep data necessary for parallel decompression. So, for now the parallel decompression is possible only if source data is compressed in a fixed rate mode. This means that each 4x4x4 block of floating-point values in compressed form consists of equal number of bits independently of block content. In practice, with fixed accuracy and fixed precision mode each block may be compressed to different number of bits which makes parallel decompression impossible.
To compress in ZFP with fixed number of bits per block we need to do the following (the code to compute a number of required bits for block is taken from Peter Lindstrom’s ZFP open source library).
ippsEncodeZfpInit_32f(pChunkBuffer + offset, maxBitsPerThread, pState));
const double REQUIRED_RATIO = 10;
const int BITS_PER_32FP_VALUE = (int)floor(32 / REQUIRED_RATIO);
unsigned int n = 1u << (2 * 3);
unsigned int bits = (unsigned int)floor(n * BITS_PER_32FP_VALUE + 0.5);
bits = MAX(bits, 1 + 8u);
ippsEncodeZfpSet_32f(bits, bits, IppZFPMAXPREC, IppZFPMINEXP, pState));
For the code above, the approximate compression ratio is about 10x. In case of fixed rate compression each compressing thread generates exactly
<number of bits per 4x4x4 block> * <number of blocks per thread>
One exception is the last compressing chunk, which may generate different number of bits, but the length of compressed data for the last chunk can be computed as
<total_number_of_compressed_bits> - <number of compressing threads – 1> * <number of bits generated by any other thread>
The source code implementing parallel decompression consists of the following.
/* Allocate ZFP decoding structures and buffer for splitted compressed data */
int decStateSize;
ippsDecodeZfpGetStateSize_32f(&decStateSize);
Ipp8u* pDecState = ippsMalloc_8u(threads * decStateSize);
int bx = (maxX + 3) / 4;
int by = (maxY + 3) / 4;
int bz = (maxZ + 3) / 4;
int blocks = bx * by * bz;
int blocksPerThread = blocks / threads;
unsigned int bitsPerBlock = GetBitWidth();
unsigned int bitsPerThread = bitsPerBlock * blocksPerThread;
Here, GetBitWidth is a function returning fixed number of bits for a 4x4x4 block. Then we need to split compressed buffers into chunks, if we know how many bits stored in each chunk, and initialize ZFP decompressing structures.
int comprChunkSize = (bitsPerThread + 7) / 8;
int comprBufferLen = comprChunkSize * (threads - 1) +
(IppZFPMAXBITS + 7) / 8 * blocksPerThread;
Ipp8u* comprChunkBuffer = ippsMalloc_8u(comprBufferLen);
/* Split compressed data and initialize each ZFP decoding state */
int chunk;
for (chunk = 0; chunk < threads; chunk++) {
IppDecodeZfpState_32f* pState = (IppDecodeZfpState_32f*)(pDecState + decStateSize *
chunk);
const Ipp8u* pCurSrc = pSrc + (bitsPerThread * chunk) / 8;
int srcOffset = (bitsPerThread * chunk) % 8;
if (chunk < threads - 1) {
ippsCopyBE_1u(pCurSrc, srcOffset, comprChunkBuffer + comprChunkSize * chunk,
0, bitsPerThread));
ippsDecodeZfpInit_32f(comprChunkBuffer + comprChunkSize * chunk,
comprChunkSize, pState));
} else {
ippsCopyBE_1u(pCurSrc, srcOffset, comprChunkBuffer + comprChunkSize * chunk,
0, srcLen * 8 - (bitsPerThread * (threads - 1))));
ippsDecodeZfpInit_32f(comprChunkBuffer + comprChunkSize * chunk,
srcLen - comprChunkSize * (threads - 1), pState));
}
ippsDecodeZfpSet_32f(bitsPerBlock, bitsPerBlock, IppZFPMAXPREC,
IppZFPMINEXP, pState));
}
Each compressed chunk has equal number of compressed bits except the last chunk. To keep the last chunk, we use (IppZFPMAXBITS + 7/8) bytes. For decompression the input bits are byte-aligned (start with bit 0), we copy bits from non-byte-aligned source position defined by srcOffset.
And the last operation is decompression itself.
/* Decode in parallel */
int x, y, z;
int yStep = maxY, zStep = maxX * maxY;
#pragma omp parallel for num_threads(threads)
for (chunk = 0; chunk < threads; chunk++) {
int blockMin = blocksPerThread * chunk;
int blockMax = blocksPerThread * (chunk + 1);
if (chunk == (threads - 1)) blockMax += blocks % blocksPerThread;
int block;
for (block = blockMin; block < blockMax; block++) {
int x, y, z;
int b = block;
x = 4 * (b % bx); b /= bx;
y = 4 * (b % by); b /= by;
z = 4 * b;
Ipp32f* p = pDst + x + yStep * y + zStep * z;
IppStatus st = ippsDecodeZfp444_32f((IppDecodeZfpState_32f*)(pDecState + chunk *
decStateSize), p, yStep * sizeof(Ipp32f), zStep * sizeof(Ipp32f));
}
}
Parallel IPP ZFP Compression/Decompression Results
All the code above was implemented as a separate benchmark, an example of performance data shown below. The CPU is the Intel® Xeon® Gold 5218 with fixed frequency of 2.30GHz, 2 sockets by 16 cores without hyper-threading. Operating system is RHEL 8, RAM 255 GB.
Generated source data array is 600 x 600 x 600 floats, compression ratio 32x, fixed number of compressed bits per 4 x 4 x 4 block is 64.
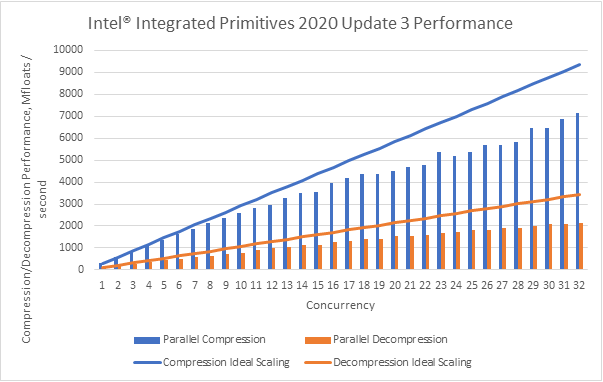
“Ideal scaling” means performance results of single-thread execution multiplied by number of executing threads. The real results usually lower than ideal because of serial parts of execution. To reduce the serialized execution and improve scalability we can remove dynamic memory allocations/releases of ZFP state structures, doing this in “main” function and passing the structure address to processing functions.
Conclusion
ZFP data compression method (along with Intel® IPP ZFP) is one of a few compressions not suffering from parallel execution due to independent processing of data elements (4x4x4 blocks in 3D case). They have no dependency from each other unlike other data compression methods, which, especially in lossless area (dictionary-based methods), rely on compression history and produce many references to already decompressed data.
Intel® IPP ZFP parallel compression and decompression execution results show good scalability, which allows significantly improve performance on modern multi-core CPUs.
The algorithm and timing code of parallel ZFP compression/decompression is summarized in a simple benchmark <link>, which can be used to investigate and experiment with parallel ZFP. The command line(s) to build the example is the following:
For Linux*
export IPPROOT=<location of deployed Intel® IPP>
cc -o zfp_parallel -O2 -fopenmp -I$IPPROOT/include zfp_parallel.c $IPPROOT/lib/intel64/libippdc.a $IPPROOT/lib/intel64/libipps.a $IPPROOT/lib/intel64/libippcore.a
For Windows*
set IPPROOT=<location of deployed Intel® IPP>
cl -O2 -openmp -I%IPPROOT%/include zfp_parallel.c %IPPROOT%\lib\intel64\ippdcmt.lib %IPPROOT%\lib\intel64\ippsmt.lib %IPPROOT%\lib\intel64\ippcoremt.lib
The command line for the sample is:
zfp_parallel [-w <time>] [-d maxX maxY maxZ] [-mt <max threads>] [-a <accuracy>] [-r <compression ratio>]
where, <time> is execution time in seconds before calculating performance values, <maxX><maxY><maxZ> are source data array dimensions, <max threads> maximum number of parallel threads to try, <accuracy> is floating point value of desired accuracy for fixed accuracy mode, <compression ratio> is floating point value of desired compression ratio for fixed rate mode. Maximum dimension values should be multiple of four and not greater than 640. Default value for maximum number of threads is number of logical cores on the computer. Maximum value of compression ratio is 32, that is each compressed 32-bit floating-point value generates 1 bit of compression output. For example:
./zfp -mt 32 -d 640 640 640 -w 0 -r 32
Threads Bits/block Ratio Compr.time.(msec) Decompr.time(msec) Max.err
----------------------------------------------------------------------------
1 64 32.0 994.5 1705.2 0.0002115
2 64 32.0 516.2 851.3 0.0002115
3 64 32.0 350.3 575.9 0.0002115
…
This command line means: execute for threads 1..32, source data array is 640x640x640, execute compression/decompression function once (wait time is 0), compression ratio should be 32x. In fact, “-a” and “-r” options are mutually exclusive. In fixed accuracy mode (“-a” option) decompression will be performed in a single thread.
For you reference, you can download the attached sample code.
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure.
Your costs and results may vary.
Intel technologies may require enabled hardware, software or service activation.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.