Multi-channel Face Detection C++ Demo
In this article, a complex demo involving multiple video inputs is presented. In this demo, you are going to learn to run the Multi-channel Face Detection C++ Demo included in the Intel® Distribution of OpenVINO™ toolkit.
Video or camera streams of up to 16 streams at the same time is supported by this demo.
Example: Below is an example of 16 video streams running.

Follow the steps for running the sample on a Linux target developer kit.
- Open Source videos are downloaded from GitHub*.
- Step 3 includes instruction to download the pre-trained model for face detection.
- Step 4 instructs you to run the demo on the target machine.
- Step 5 offers guidance to use accelerators with this demo
Prerequisites
- Intel® Distribution of OpenVINO™ toolkit 2019 r3
- Ubuntu* 18.04 or Ubuntu 16.04
- Familiarity with Linux* commands
Step 1: Compile the demo
Before running the Multi-channel Face Detection demo in the Intel® Distribution of OpenVINO™ toolkit, the demo needs to be complied. There is an automated script to compile all the demos for r3 located in:
/opt/intel/openvino/deployment_tools/open_model_zoo/demos
Note: If CMake* is not installed, install cmake, and then build the demos. To install cmake, run the following command in a terminal: sudo apt install cmake
Run this command in the terminal to change to the demos directory.
cd /opt/intel/openvino/deployment_tools/inference_engine/demos
Build all the demos by running the script.
./build_demos.sh
The demo binaries are built in:
~/omz_demos_build/intel64/Release
Step 2: Target - Clone the Sample-Videos Repository
Sample videos required to run this demo are located in this public GitHub repository. The videos need to be present on the target system for the demo to work.
Run these commands on developer kit.
Clone the sample videos to the home folder of your developer kit.
cd ~
git clone https://github.com/intel-iot-devkit/sample-videos.git
Step 3: Download the Face Detection Model
The model for this demo,face-detection-retail-0004, is not included in the Intel® Distribution of OpenVINO™ download, so you will download this using the model_downloader or wget the model.
On the target system, as root, run the downloader.py to get the model.
Note: You can use any of the following flag with downloader.py to specify which directory to store the downloads: --output_dir
cd /opt/intel/openvino/deployment_tools/tools/model_downloader
Run the following command in the terminal.
sudo ./downloader.py --name face-detection-retail-0004
Verify the model download per the directory indicated during the download.
There should be a .bin. and .xml in this directory.
Example:
========= Downloading /opt/intel/openvino_2019.2.242/deployment_tools/open_model_zoo/tools/downloader/Retail/object_detection/face/sqnet1.0modif-ssd/0004/dldt/FP16/face-detection-retail-0004.xml
... 100%, 46 KB, 15518 KB/s, 0 seconds passed
========= Downloading /opt/intel/openvino_2019.2.242/deployment_tools/open_model_zoo/tools/downloader/Retail/object_detection/face/sqnet1.0modif-ssd/0004/dldt/FP16/face-detection-retail-0004.bin
... 100%, 1148 KB, 9068 KB/s, 0 seconds passed
Step 4: Run the Multi-channel Demo on the CPU and GPU
You are now ready to run the demo on the target system.
From the target system, first run help file for the multi-channel sample. Then, we will run this on the CPU.
Change to the directory with the built binaries. By default this directory is omz_demos_build:
cd ~/omz_demos_build/intel64/Release
Initialize the openvino environment.
. /opt/intel/openvino/bin/setupvars.sh
To see the available parameters/flags, type -h.
./multi-channel-face-detection-demo -h
Flags
| -m | path to .xml file with a trained model | required |
| -l | absolute path to shared library with kernels implementation | required for CPU custom layers |
| -c | absolute path to .xml file with kernels descriptions | required for GPU custom layers |
| -d | device | optional |
| -i | full path to input files | optional |
Run the command:
./multi-channel-face-detection-demo -m /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/Retail/object_detection/face/sqnet1.0modif-ssd/0004/dldt/FP16/face-detection-retail-0004.xml -d CPU -i ~/sample-videos/head-pose-face-detection-female-and-male.mp4 -i ~/sample-videos/head-pose-face-detection-female.mp4 -i ~/sample-videos/head-pose-face-detection-male.mp4 -i ~/sample-videos/people-detection.mp4 -i ~/sample-videos/face-demographics-walking-and-pause.mp4 -i ~/sample-videos/face-demographics-walking.mp4
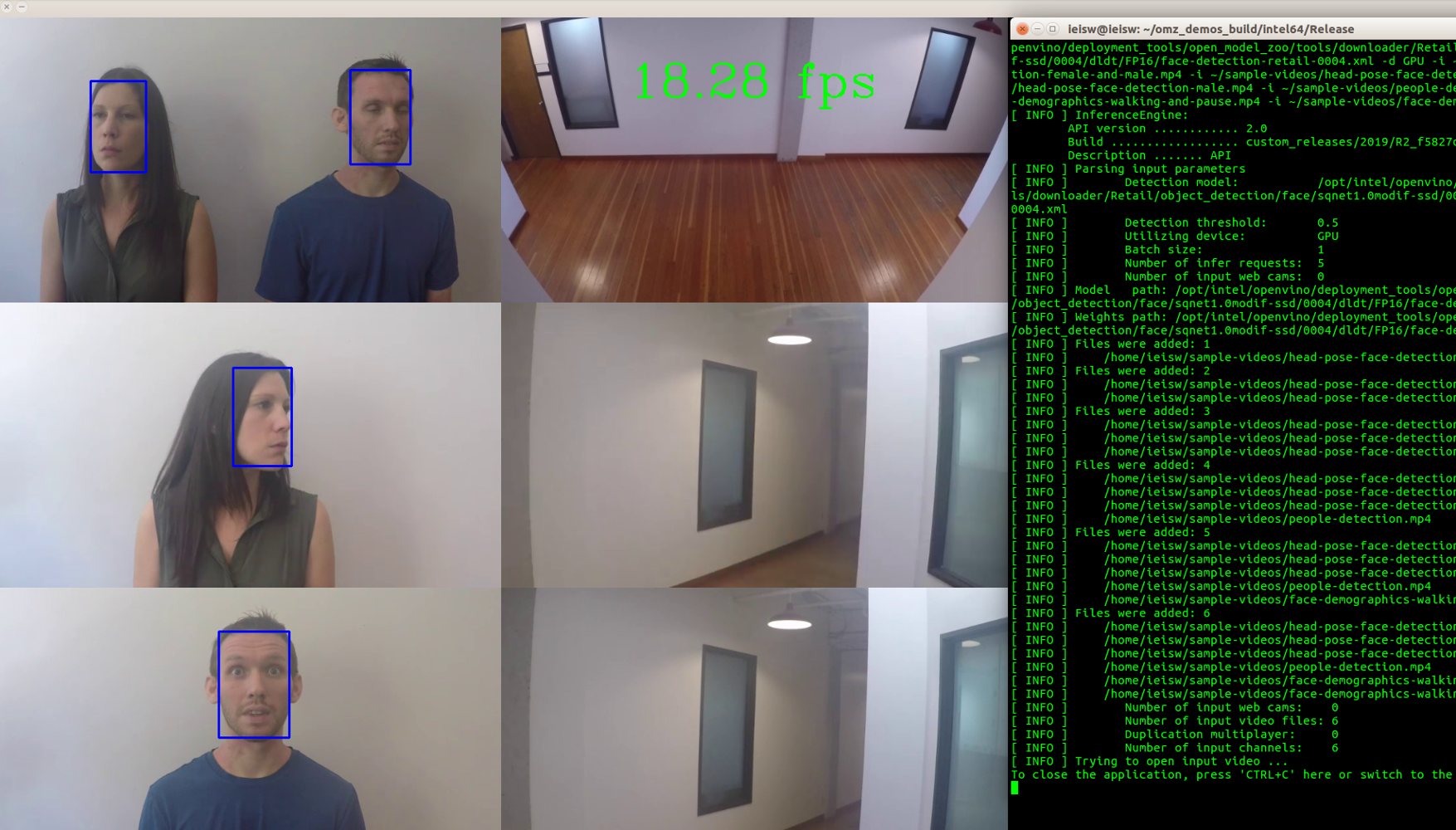
You should see an output similar to the one below, with 6 videos running at the same time all doing face detection. If you want to run more than 6, simply add more inputs to the command used to run the demo:
-i <path to video file>
Now, you can run the multi-channel demo on the GPU with the following command:
./multi-channel-face-detection-demo -m /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/Retail/object_detection/face/sqnet1.0modif-ssd/0004/dldt/FP16/face-detection-retail-0004.xml -d GPU -i ~/sample-videos/head-pose-face-detection-female-and-male.mp4 -i ~/sample-videos/head-pose-face-detection-female.mp4 -i ~/sample-videos/head-pose-face-detection-male.mp4 -i ~/sample-videos/people-detection.mp4 -i ~/sample-videos/face-demographics-walking-and-pause.mp4 -i ~/sample-videos/face-demographics-walking.mp4
You will see a similar output as before, though likely with different frames per second (fps).
Conclusion
The mulit-channel face detection demo supports up to 16 input streams. This article used only 6 input streams on CPU and GPU.
The input streams can be sequentially noted in the command as:
./multi-channel-face-detection-demo -m /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/Retail/object_detection/face/sqnet1.0modif-ssd/0004/dldt/FP16/face-detection-retail-0004.xml -d GPU -i ~/sample-videos/head-pose-face-detection-female-and-male.mp4 ~/sample-videos/head-pose-face-detection-female.mp4 ~/sample-videos/head-pose-face-detection-male.mp4 ~/sample-videos/people-detection.mp4 ~/sample-videos/face-demographics-walking-and-pause.mp4 ~/sample-videos/face-demographics-walking.mp4
GNA and MYRIAD are also supported. For more information about the multi-channel face detection demo, refer to the documentation for Multi-Channel Face Detection.