Introduction
The compute power of Intel® Processor Graphics is continuously growing with each generation. Each generation builds upon the last with increasing compute capacity in both fixed function and programmable execution units (EU’s). How do developers tap into this and effectively utilize the power of the platform to run GPU workloads in the most efficient manner?
This paper will detail the implementation of out of order queues, an OpenCL™ construct that allows independent kernels to execute simultaneously whenever possible, and thus keep all GPU assets fully utilized. This paper will utilize a simple matrix multiplication kernel(s) – GEMM and cl_intel_advanced_motion_estimation extension to illustrate how the OpenCL out of order queues can boost the performance of an application that has many independent workloads.
GPU Workloads and the OpenCL™ Command Queue
Execution of an OpenCL program occurs in two parts: kernels that execute on one or more OpenCL devices and a host program that executes on the host. The host program defines the context for the kernels and manages their execution. Objects such as memory, programs and kernel are created within an OpenCL context. The host creates a data structure called a command-queue to coordinate execution of the kernels on the devices. The host places commands into the command-queue which are then scheduled onto the devices within the context.
The command-queue schedules commands for execution on a device. These execute asynchronously between the host and the device. Commands execute relative to each other in one of two modes:
In-Order Execution: Commands are launched in the order they appear in the command queue and complete in order. In other words, a prior command in the queue completes before the following command begins. This serializes the execution order of commands in a queue. For example, we have kernel A and kernel B to be executed in order.
Out-of-Order Execution: Commands in an out-of-order queue do not guarantee any order of execution. Any order constraints are enforced by the programmer through explicit synchronization commands. For example, when a command waiting for a user event is placed on an OOQ it will not execute until the event is satisfied, but other commands even the ones placed after this command will start execution if their dependencies are met.
When creating the OpenCL command queue the developer has the option of specifying the order in which the commands will be executed. The default method of operation for an OpenCL command-queue is “in-order”, which means commands will be executed in the order in which they are submitted.
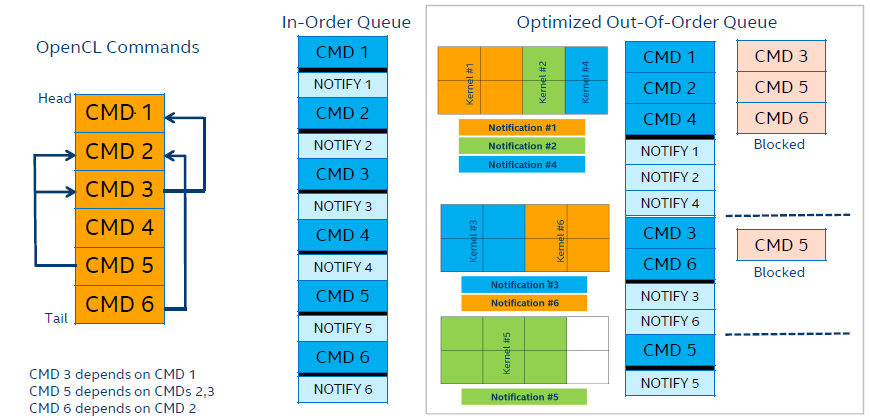
Figure 1: Out-of-order queue enables independent kernels to execute simultaneously whenever possible to keep all GPU assets busy, which does not guarantee any order of execution.
OpenCL Out-of-Order Queue
The OpenCL standard lets an application configure a command-queue to execute commands out-of-order.
In many cases multiple different kernels could potentially be ready to execute concurrently, in other words, commands placed in the work queue may begin and complete execution in any order. Therefore, it can utilize all the hardware assets to the maximum.
Applications can configure the commands enqueued to a command-queue to execute out-of-order by setting the CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE property of the command-queue. This can be specified when the command-queue is created or can be changed dynamically using clCreateCommandQueue. More details are shown in the session below.
When using the out-of-order execution mode there is no guarantee that the enqueued commands will finish execution in the order that they were queued because there is no guarantee that kernels will be executed in order, that is, based on when the clEnqueueNDRangeKernel calls are made within a command-queue. It is therefore possible that an earlier clEnqueueNDRangeKernel call to execute kernel “A” identified by event “A” may execute and/or finish later than a clEnqueueNDRangeKernel call to execute kernel “B” which was called by the application at a later point in time.
To guarantee a specific order of execution of kernels, a wait on a particular event (in this case event “A”) can be used. The wait for event “A” can be specified in the event_wait_list argument to clEnqueueNDRangeKernel for kernel “B”.
Be aware that if we took a trivial sequence of in-order queue (IOQ) work (ABC) and migrated it to OOQ (A->B->C) with explicit dependencies yielding the same sequence, the results may be worse than an IOQ alone; a future release may similarly optimize such a sequence for OOQs.
Creating an OpenCL Out of Order Command Queue
Creating an out of order queue is a straightforward process of setting the cl_command_queue_property to CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE when creating the cl command queue. If set, the commands in the command-queue are executed out-of-order. Otherwise, commands are executed in-order.
Refer to OpenCL host API clCreateCommandQueue and clCreateCommandQueueWithProperties for more details.
For example:
cl_command_queue_properties qProperties = CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLE;
cl_command_queue queue = clCreateCommandQueue(context, deviceIds[0], qProperties, &error);
Note that clCreateCommandQueue is used in OpenCL v1.2, and deprecated in favor of clCreateCommandQueueWithProperties in OpenCL v2.0 and later.
Avoid the CL_QUEUE_PROFILING_ENABLE property in production as it may severely impact performance or even make concurrent execution impossible.
OpenCL Implementation
Identify independent tasks that can run in parallel and prepare them to execute through one out-of-order command-queue:
double start_exec_time = time_stamp();
for ( cl_uint i= 0 ; i < iterations ; i++)
{
error = clEnqueueNDRangeKernel(oclobjects.queue, executable.kernel, 2, NULL,
global_size, local_size, 0, 0, NULL);
error = clEnqueueNDRangeKernel(oclobjects.queue, test_kernel_1, 2, NULL,
test_global_size, test_local_size, 0, 0,
NULL);
error = clEnqueueNDRangeKernel(oclobjects.queue, test_kernel_2, 2, NULL,
test_global_size, test_local_size, 0, 0,
NULL);
// (etc.)
}
error = clFinish(oclobjects.queue);
double exection_time = time_stamp() – start_exec_time;
Note: For each stream of commands avoid flushing or blocking operations such as clFlush, clFinish, clWaitForEvents or blocking enqueue commands and manage dependencies with event waitlists.
For example:
cl_event *nd_range_events = new cl_event[streams];
for(int s = 0; s < streams; s++)
{
error = clEnqueueNDRangeKernel(oclobjects.queue, executable.kernel, 2, NULL,
global_size, local_size, 0, 0,
&nd_range_events[s]);
clEnqueueMapBuffer(queue,
oclobjects.queue,
CL_FALSE, //non-blocking map
CL_MAP_READ,
0,
matrix_memory_size,
1, &nd_range_events[s], 0, &err);
}
error = clFinish(oclobjects.queue);
Applying Out-of-Order Command Queue to General Matrix Multiply OpenCL Kernels
A general matrix multiply (GEMM) sample demonstrates how to efficiently utilize an OpenCL device to perform general matrix multiply operation on two dense square matrices. General matrix multiply is a subroutine that performs matrix multiplication: C = alpha*A*B + beta*C, where A, B and C are dense matrices and alpha and beta are floating point scalar coefficients.
This implementation optimizes trivial matrix multiplication nested loop to utilize the memory cache more efficiently by introducing a well-known practice as tiling (or blocking), where matrices are divided into blocks and the blocks are multiplied separately to maintain better data locality. Most of the GEMM code comes from General Matrix Multiply Sample from Intel® SDK for OpenCL™ applications.
To evaluate the performance of a regular GEMM kernel, by default, we calculate C’ = alpha*A*B + beta*C, and the size of A, B, C is (256 * 256) matrix. The kernel gemm_nn deals with block multiplication, and the size of the block in each work item is (1 * 128) matrix, which results in that the global size is 256 * 2. Therefore, we can get 512 work items total, and we set the local size to be (16 * 1), which means there are 32 work groups. Only a few work-items are needed to finish one kernel execution. For example, on a 6th Generation Intel® Core™ i5-6600k processor at 3.50 GHz with Intel® HD Graphics, which contains 24 execution units and 2688 SIMD16 work-items, one execution of the kernel gemm_nn cannot occupy all the computing resources. Therefore, we can get the performance benefits from submitting kernels to the out-of-order queue when the kernel’s execution cannot fill all the EUs.
To demonstrate the effectiveness of out-of-order queues versus in-order queues, we run eight GEMM kernels in one loop in order to calculate eight different matrix multiplications. In an in-order queue eight streams/kernels are executed one by one on the GPU and therefore EUs cannot be saturated. However, in an out-of-order queue multiple executions will happen at the same time to occupy all the EUs, which significantly improves the performance. We will discuss performance in next section.
Applying Out-of-Order Command Queue with clWaitForEvents to Two GEMM Kernels
In this example, we’d like to submit two GEMM kernels with serialization. For example, we calculate C_1 = alpha*A*B + beta*C in kernel_1, and then calculate C_2 = alpha*A*B + beta*C_1 in kernel_2. Since in-order execution cannot fill all the EUs, we can also get performance benefits from submitting the GEMM kernels with serialization to the out-of-order queue. Note that, in order to get the right result C_2, kernel_2 must be executed exactly after kernel_1. We can use clWaitForEvents or blocking to enqueue commands and manage dependencies with event waitlists. The experiments are tested both in out-of-order queue and in-order queue, and performance improvement will be discussed in the next section.
Applying Out-of-Order Queue to VME and General GEMM Kernels
A real-world example of the effectiveness of out-of-order queues can be demonstrated using a common media workload. The 6th Generation Intel® Core™ i5-6600k processor at 3.50 GHz with Intel HD Graphics has dedicated hardware blocks for video motion estimation (VME) processing along with Execution Units (EUs) available for general computations. Ideally, an application’s goal should be to let applications utilize the EU’s for general purpose computations, while still using the VME engine to operate on the media content in parallel.
In our sample the VME workload and a regular OpenCL kernel will be enqueued back to back in out-of-order and in-order queues. Assuming the execution time of these two kernels is comparable, the speedup of an out-of-order queue is observed in a total execution time of these two kernels enqueued back to back and measured together. Each of the (VME+GEMM) kernels are executed 10 times.
Most of the VME code comes from ocl_motion_estimation_advanced sample from Intel® Media Sever Studio samples (Intel® Media SDK).
Performance
Demonstrated below is the performance comparison between an in-order and an out-of-order queue on a 6th Generation Intel® Core™ i5-6600k processor at 3.50 GHz with Intel® HD Graphics, which contains 24 EUs running at 1.15Hz, on a CENTOS* 7.2.1511 platform.
First, we executed eight streams of single GEMM kernel with matrix size 256x256, back to back in in-order and out-of-order queues, and used Intel® VTune™ Amplifier 2017 to measure the GPU usages, which are shown separately in Figure 2 and Figure 3.
As Figure 2 shows, in the middle of each of the kernel’s execution cycle, VTune™ Amplifier may report the GPU EU array reaching 100 percent utilization. However due to the relatively small NDRange sizes and in-order command queues, the GPU EU array usage can only reach about 96 percent at the beginning and end of each stream/kernel. Digging deeper into the analysis of EU arrays usage, we also find the percentage of EU Active is only about 57 percent, due to a high percentage of EU stalled (about 40 percent) and also EU idled (about 3 percent) existing in the beginning and end of each kernel, which means that in-order command queue leads to underutilization of the GPU.
In Figure 3, in comparison with Figure 2, notice that the average GPU usage in the out-of-order queue is higher because most of the EU idle of GPU execution (the gray lines) are eliminated, especially those between the switch of each kernel.

Figure 2: Intel® VTune™ performance analysis of in-order command queues using the GEMM sample kernel.
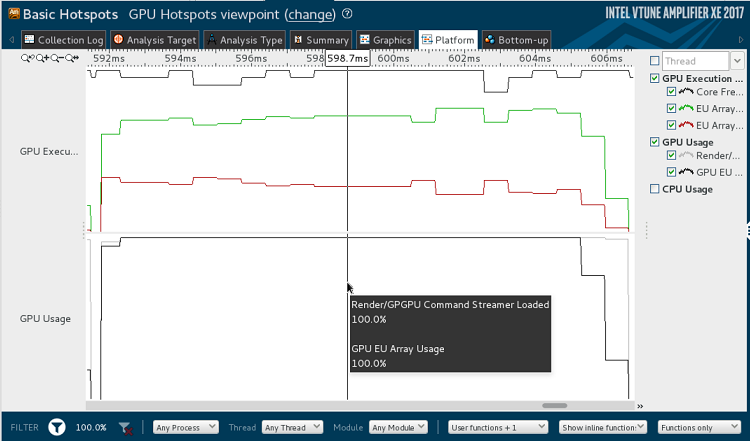
Figure 3: Intel® VTune™ performance analysis of out-of-order command queues using the GEMM sample kernel.
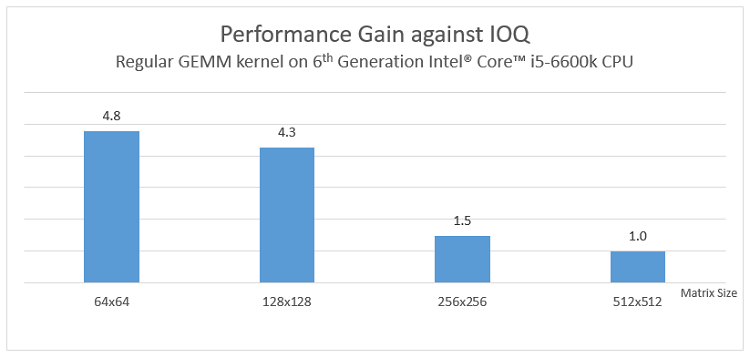
We execute GEMM kernels for different matrix sizes and performance gain of the OOQ is presented in the chart below. It shows clearly that the smaller the matrix size is, the better performance is against the IOQ, which proves that out-of-order queue can regain the lost performance in workloads that are using only a portion of the GPU assets available.
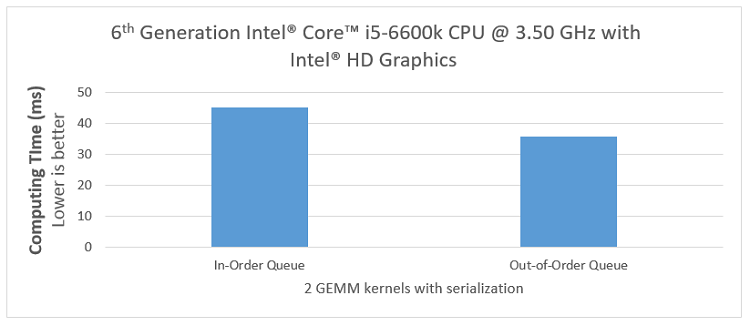
Like as before, we executed eight streams of two GEMM kernels with serialization. The experiments were tested enqueued back to back in out-of-order and in-order queues and the computing time and GFLOPS were recorded below. And as shown below, we obtained about 1.26x performance improvement.
In the application “Applying Out-of-Order Queue to VME and General GEMM Kernels”, in order to make VME and GEMM kernels comparable, the matrix size in the GEMM kernel was modified to (512 * 512). First we tested EU array and computing time of these two kernels separately, listed in the following table. Those data will be used in the analysis of out-of-order queue performance later.
| EU Array Active | Execution Time (ms) | |
| VME * 10 times | 4.2% | 85.73 |
| GEMM * 10 times | 71.1% | 141.875 |
Then we executed 10 streams of (VME + GEMM) kernels back to back in out-of-order and in-order queues. Note that VME and GEMM kernels are independent, and there is no clWaitForEvents between kernels. Their GPU usage is measured by VTune™ Amplifier. In Figure 4, the upper part is in the in-order queue and the bottom part is in the out-of-order queue.
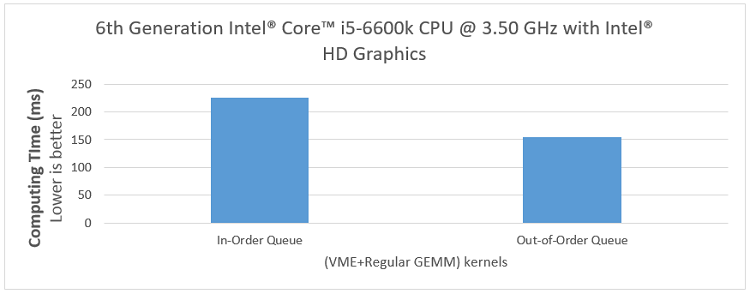
In the upper part of Figure 4, we can see that EU array active (the green line) is periodically lower and higher. That’s because VME is executed first with short execution time and low EU activity, and then GEMM is executed in-order with long execution time and high EU active. The execution time of VME + GEMM in in-order queue is about 225ms, which is almost the same as the sum of execution time of VME and GEMM.
In the bottom part of Figure 4, due to the out-of-order queue execution, we cannot see the periodic change of EU array. Instead, we measured the lowest active EU array, which is about 24 percent. And it is obvious that the lowest EU active in the in-order queue is equal to the active EU of VME, which is about 4 percent. Moreover, in GPU usage, there are fewer grooves in the out-of-order queue. Therefore, it can be proved that in the out-of-order queue, we can get a higher average active EU array and keep all GPU assets better utilized.
In conclusion, in the (VME + GEMM) kernels application, we obtain about 1.5x performance improvement.

Figure 4: Intel® VTune™ performance analysis using (VME + regular GEMM) kernels.
Caveats/Limitations
- The out-of-order queue feature is not a default property, and cl_command_queue_properties
CL_QUEUE_OUT_OF_ORDER_EXEC_MODE_ENABLEmust be specified when creating cl command queue. - Be aware of limited hardware resources (barriers, SLM) when expecting parallel execution benefits.
- When using out-of-order queues explicitly manage dependencies between enqueues through events and event_waitlists arguments as there is no in-order execution guarantee.
- Internal optimizations may result in worse performance than using in order queues when dependecies result in the serialization of kernels. When in doupt, test and implement what works best for your specific workload.
- Using events – the users must call clReleaseEvent() for every event they get back from an enqueue command, or they’ll have a memory leak.
- Speed-up is observed in the total execution time of multiple kernels when enqueued together into the same out-of-order command-queue. Particular performance gains vary and depend on a workload and a given hardware configuration characteristics.
Conclusion
In this article we demonstrated how to use OpenCL out-of-order queues to improve performance on the 6th Generation Intel® Core™ i5-6600k processor with Intel® HD Graphics. We implemented our sample using OpenCL VME and regular GEMM OpenCL kernel in out-of-order queue, and compare performance with an in-order queue. When used properly, the OpenCL out-of-order queue provides a significant performance boost.
System/Driver/Tool Version
CPU: The 6th Generation Intel® Core™ i5-6600k processor at 3.50 GHz
GPU: Intel® HD Graphics, EU Count: 24, Max EU Thread Count: 7
OpenCL: OpenCL™ 2.0
OS: CENTOS* 7.2.1511 platform
Tool: Intel® VTune™ Amplifier XE 2017
References
- clCreateCommandQueue & clCreateCommandQueueWithProperties
- Intro to Advanced Motion Estimation Extension for OpenCL™
- cl_intel_advanced_motion_estimation
- General Matrix Multiply sample
- Intel® Media SDK
- OpenCL™ Optimization Guide for Intel® Processor Graphics
About the Authors
Danyu Bi
- Software Engineer in the Intel IT Flex Services Group.
Sardella, Eric
- Software Engineer in the Intel Software and Services Group.