GEMM functions are the most commonly used and performance-critical Intel® oneAPI Math Kernel Library (oneMKL) functions. oneMKL 2024 extends earlier optimizations for small problem sizes (MKL Direct Call, Batch API, Compact API) by introducing JIT code generation for the SGEMM and DGEMM functions on Intel® Advanced Vector Extensions 2 (Intel® AVX2) and Intel® Advanced Vector Extensions 512 (Intel® AVX-512) architectures. The JIT feature generates optimized GEMM kernels at runtime, tailored to the inputs you provide.
oneMKL 2024 has JIT functionality to significantly accelerate small matrix multiplications. It supports JIT kernel generation for:
- Real precisions (SGEMM and DGEMM)
- m, n, k ≤ 16, any alpha and beta, and transposition of the A and B matrices
- Intel AVX2 and Intel AVX-512 architectures
oneMKL extends the previous functionality, supporting JIT kernel generation for:
- Real and complex precisions: SGEMM, DGEMM, CGEMM, and ZGEMM
- Any matrix sizes (as long as one of m, n, and k is less than 128), any alpha and beta, and transposition of the A and B matrices
- Intel AVX, Intel AVX2, and Intel AVX-512 architectures
Note Applications using oneMKL JIT functionality run on all architectures. In case JIT is not supported for the current architecture or problem size, oneMKL transparently falls back on standard GEMM routines.
oneMKL provides two interfaces you to access the JIT functionality. The first is completely transparent, and is activated through an extension of the existing MKL_DIRECT_CALL interface. For more information, see the MKL_DIRECT_CALL documentation.
The second interface includes dedicated APIs for advanced users who are willing to change their code and provides the ability to extract even more performance by removing most of the associated call overhead.
The following sections describe how to use these features in more detail in C/C++. The new JIT functionality may also be accessed from Fortran 90 using a similar interface. For more information on using JIT GEMM in Fortran 90, see the examples bundled with oneMKL or the Fortran documentation.
Use JIT without Changing Your Code
The simplest way to take advantage of the JIT GEMM capabilities in oneMKLis to define the preprocessor macro MKL_DIRECT_CALL_JIT. No other changes are required. (If you are using oneMKL in sequential mode, define MKL_DIRECT_CALL_SEQ_JIT instead.)
When MKL_DIRECT_CALL_JIT is active and you call GEMM, oneMKL decides whether JIT code generation could be beneficial for the GEMM. If so, oneMKL generates size and architecture-specific kernels tailored to the given parameters (layout, transa, transb, m, n, k, alpha, lda, ldb, beta, and ldc). These kernels are then cached and reused every time GEMM is called with the same set of parameters. If oneMKL decides JIT is not beneficial, the standard GEMM routine is called as usual.
The MKL_DIRECT_CALL_JIT and MKL_DIRECT_CALL_SEQ_JIT preprocessor macros allow you to quickly evaluate whether the JIT feature provides performance benefits to your applications, particularly those that call GEMM many times for small problem sizes.
Example
The following loop calls DGEMM repeatedly with different A, B, and C matrices but the same parameters layout, transa, transb, m, n, k, alpha, lda, ldb, beta, and ldc.
for (it = 0; it < nb; it++) {
…
cblas_dgemm(CblasColMajor, CblasNoTrans, CblasTrans, 5, 3, 12, 1.0, a[it], 8, b[it], 8, 0.0, c[it], 8);
…
}
Let’s assume that this code is extracted from a file named bench.c, which is compiled using the following command line in Linux*:
$ icc bench.c –o bench -DMKL_ILP64 -I${MKLROOT}/include -L${MKLROOT}/lib/intel64 -lmkl_intel_ilp64 -lmkl_sequential -lmkl_core -lpthread -lm –ldl –DMKL_DIRECT_CALL_SEQ_JIT
When running the generated executable bench on an Intel AVX2 or Intel AVX-512 system, the first loop iteration generates a dedicated size and architecture-specific GEMM kernel and stores it. Subsequent loop iterations retrieve the stored kernel and reuse it.
Performance
The following chart illustrates the performance benefits of the MKL_DIRECT_CALL_JIT feature on an Intel® Xeon® Platinum 8180 processor for some small square matrix multiplications. The performance shown in this chart does not include the kernel generation time; we are assuming here that the kernel generation cost is amortized by a large number of SGEMM calls using the same input parameters, but different matrices. The performance of conventional SGEMM and SGEMM with MKL_DIRECT_CALL are provided for comparison. Data on other precisions can be found in the next section of this article.
These tests were conducted with alpha = beta = 1, lda = m, ldb = k, ldc = 16, and both A and B nontranspose.
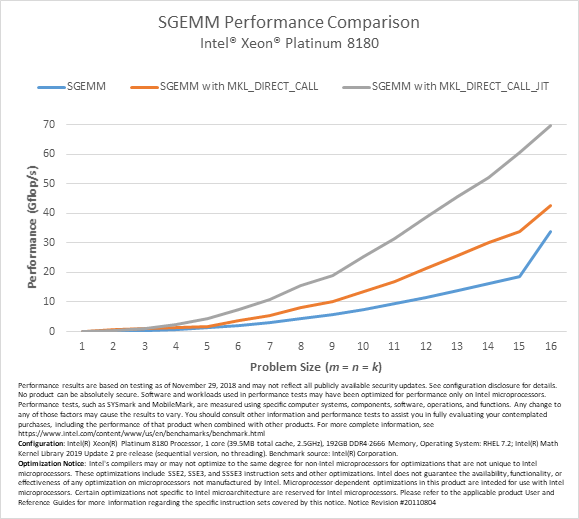
To conclude, MKL_DIRECT_CALL_JIT allows you to speed up small matrix multiplies with no code modifications. However, caching kernels and looking them up at runtime does incur some overhead. For best performance, see the oneMKL dedicated JIT API in the next section.
Explicitly Use the JIT GEMM API for Maximum Performance
For best performance, you can explicitly create optimized GEMM kernels generated for specific problem sizes and call them using function pointers. The new API consists of three groups of functions:
- mkl_jit_create_{s,d,c,z}gemm – creates a JIT kernel
- mkl_jit_get_{s,d,c,z}gemm_ptr – gets a pointer to the kernel function
- mkl_jit_destroy – destroys a JIT kernel
The real versions were introduced in oneMKL 2019. The complex versions were introduced in oneMKL 2019, update 3. These functions and their associated data types are defined in mkl.h.
The GEMM JIT kernel and the required runtime code generator are generated and stored by calling mkl_jit_create_{s,d,c,z}gemm, which takes as inputs the standard GEMM input parameters (except the pointers to matrices A, B, and C) and a pointer where a handle to the code generator (an opaque pointer) is stored. The mkl_jit_create_{s,d,c,z}gemm function returns a status code of type mkl_jit_status_t, whose value may be one of the following:
- MKL_JIT_SUCCESS – A GEMM kernel was generated.
- MKL_NO_JIT – A GEMM kernel was not generated and standard GEMM is used instead.
- MKL_JIT_ERROR – An error occurred due to lack of memory.
There are several reasons MKL_NO_JIT may be returned:
- JIT is unavailable for the current instruction set architecture.
- Before oneMKL 2019, update 3, the matrices were larger than the maximum supported size.
- For oneMKL 2019, update 3, the matrices are large enough that JIT may not be beneficial.
After creating the code generator, call mkl_jit_get_{s,d,c,z}gemm_ptr to retrieve a function pointer to the generated GEMM kernel. This function pointer performs the requested GEMM operation, taking four parameters: a handle to the code generator and pointers to the A, B, and C matrices.
Note A valid pointer is returned even when mkl_jit_create_{s,d,c,z}gemm returns MKL_NO_JIT. In this case, standard GEMM is used rather than a JIT-generated kernel.
Finally, when the kernel is no longer needed, the mkl_jit_destroy function frees memory associated to the code generator and GEMM kernel.
Example
The following code samples illustrate how the loop in the previous example can be rewritten to use calls to the mkl_jit_create_dgemm, mkl_jit_get_dgemm_ptr and mkl_jit_destroy functions.
// declare a handle on the code generator
void* jitter;
// create the code generator and generate the tailored GEMM kernel
// the first parameter is the address of the code generator handle
mkl_jit_status_t status = mkl_jit_create_dgemm(&jitter, CblasColMajor, CblasNoTrans, CblasTrans, 5, 3, 12, 1.0, 8, 8, 0.0, 8);
// check if the code generator has been successfully created
if (MKL_JIT_ERROR == status) {
fprintf(stderr, “Error: insufficient memory to JIT and store the DGEMM kernel\n”);
return 1;
}
// retrieve the function pointer to the DGEMM kernel
// void my_dgemm(void*, double*, double*, double*)
// it is safe to call mkl_jit_get_dgemm_ptr only if status != MKL_JIT_ERROR
dgemm_jit_kernel_t my_dgemm = mkl_jit_get_dgemm_ptr(jitter);
for (it = 0; it < nb; it++) {
…
// replace cblas_dgemm calls by calls to the generated DGEMM kernel
// the first parameter is the handle on the code generator
// followed by the three matrices
my_dgemm(jitter, a[it], b[it], c[it]);
…
}
// when the DGEMM kernel is not needed, free the memory.
// the DGEMM kernel and the code generator are deleted
mkl_jit_destroy(jitter);
/* mkl.h is required for dsecnd and SGEMM */
#include <iostream>
#include <mkl.h>
int main(int argc, char** argv)
{
/* initialization code is skipped for brevity (do a dummy dsecnd() call to improve accuracy of timing) */
const long long m = 8;
const long long n = 8;
const long long k = 6;
float alpha = 1.0, beta = 1.0;
float *A, *B, *C;
const int MKL_MEM_ALIGNMENT = 64;
/* first call which does the thread/buffer initialization */
//float A[m * k] = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f,
// 6.0f, 7.0f, 8.0f, 9.0f, 10.0f,
// 11.0f, 12.0f, 13.0f, 14.0f, 15.0f};
//float B[k * n] = {1.0f, 2.0f, 3.0f, 4.0f,
// 5.0f, 6.0f, 7.0f, 8.0f,
// 9.0f, 10.0f, 11.0f, 12.0f,
// 13.0f, 14.0f, 15.0f, 16.0f,
// 17.0f, 18.0f, 19.0f, 20.0f};
//float C[m * n] = {0.0f};
/* Memory aligned initialization (Not necessary but improves performance)*/
A = (float *) mkl_malloc(sizeof(float)*m*k, MKL_MEM_ALIGNMENT);
B = (float *) mkl_malloc(sizeof(float)*k*n, MKL_MEM_ALIGNMENT);
C = (float *) mkl_malloc(sizeof(float)*m*n, MKL_MEM_ALIGNMENT);
for (std::size_t i = 0; i < (m*k); i++) {
A[i] = (float)(i+1);
}
for (std::size_t i = 0; i < (k*n); i++) {
B[i] = (float)(-i-1);
}
for (std::size_t i = 0; i < (m*n); i++) {
C[i] = 0.0;
}
void* gemm_kernel;
mkl_jit_status_t status = mkl_jit_create_sgemm(&gemm_kernel, MKL_ROW_MAJOR, MKL_NOTRANS, MKL_NOTRANS,
m, n, k, alpha, k, n, beta, n );
if (status != MKL_JIT_SUCCESS) {
std::cerr << "Error creating GEMM kernel: " << status << std::endl;
return 1;
}
sgemm_jit_kernel_t my_sgemm = mkl_jit_get_sgemm_ptr(gemm_kernel);
/* start timing after the first GEMM call */
double time_st = dsecnd();
std::size_t LOOP_COUNT = 100;
for (std::size_t i=0; i<LOOP_COUNT; ++i)
{
my_sgemm(gemm_kernel,A,B,C);
}
double time_end = dsecnd();
double time_avg = (time_end - time_st)/LOOP_COUNT;
double gflop = (2.0*m*n*k)*1E-9;
std::cout << "Average time: " << time_avg << "sec" << std::endl;
std::cout << "GFlop: " << gflop << std::endl;
std::cout << "GFlop/sec " << gflop/time_avg << std::endl;
mkl_jit_status_t status_d = mkl_jit_destroy(gemm_kernel);
if (status_d != MKL_JIT_SUCCESS) {
std::cerr << "Pointer can not be freed" << status_d << std::endl;
}
}
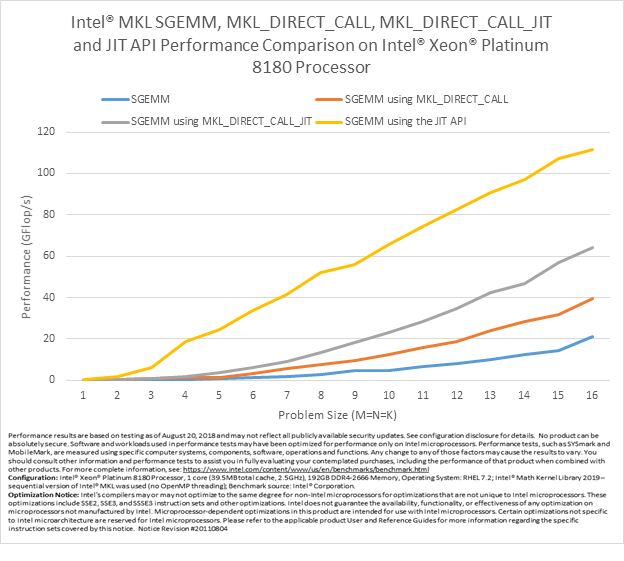
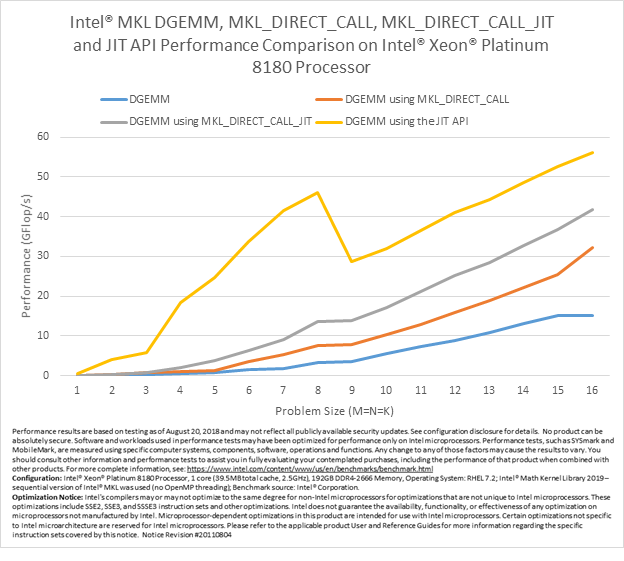
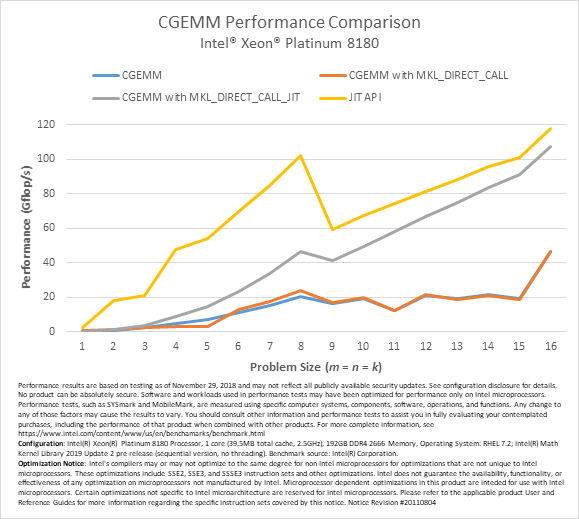
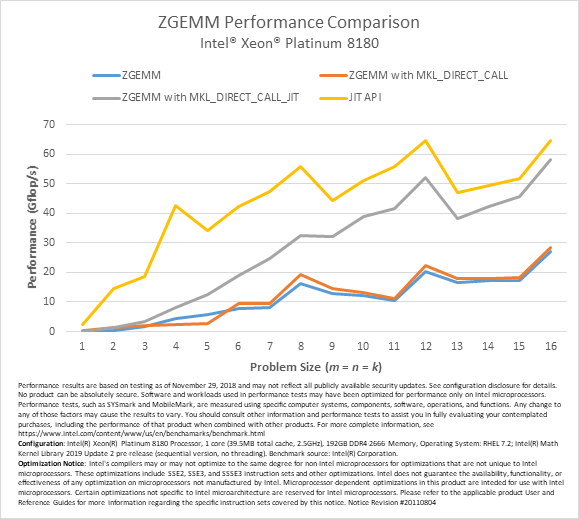
Performance
The following charts illustrate the performance benefits of the new JIT APIs on Intel Xeon Platinum 8180 processor. The performance shown in the charts assumes that the kernel generation cost can be completely amortized by a large number of SGEMM and DGEMM calls using the same input parameters (except matrices). The performance of the MKL_DIRECT_CALL feature, conventional SGEMM and DGEMM calls, and the MKL_DIRECT_CALL_JIT feature described earlier for various m, n, and k parameters are provided for comparison.
All tests were conducted with alpha = beta = 1, lda = m, ldb = k, ldc = 16, and both A and B nontranspose.
Decide When to Use JIT
Following are some guidelines on when to use JIT and which API to use:
- If m, n, and k are all small (≤ 32), JIT is likely to be beneficial if your code reuses the generated kernel at least 100 to 1,000 times. The JIT API is recommended for best performance, due to overheads in MKL_DIRECT_CALL_JIT.
- If one or two of m, n, and k are small (≤ 32) and the others are larger, MKL_DIRECT_CALL_JIT does not introduce much overhead and can be used to quickly determine whether JIT is useful. If so, you may also consider refactoring your code to use the JIT API for extra performance gains.
- If m, n, and k are all larger (> 32), JIT may provide little to moderate speedup, depending on the exact problem. Try using MKL_DIRECT_CALL_JIT to gauge whether JIT is appropriate for your application.
- MKL_DIRECT_CALL_JIT and the JIT API both use heuristics to determine whether or not to generate a JIT GEMM kernel. MKL_DIRECT_CALL_JIT is more conservative; it generates kernels only when JIT is predicted to increase performance. However, the JIT API does not generate kernels if JIT does not increase performance. In oneMKL 2019, update 3, the JIT API will not generate kernels if m, n, and k are all at least 128.
Currently, all JIT GEMM kernels are single-threaded. However, it is safe to create, call, and destroy kernels from multithreaded code. If you have a GEMM problem where one of m, n, and k is very large, and the other two test cases that use the GEMM library are small, it may be worthwhile to divide the problem between multiple threads and use JIT on the subproblems.
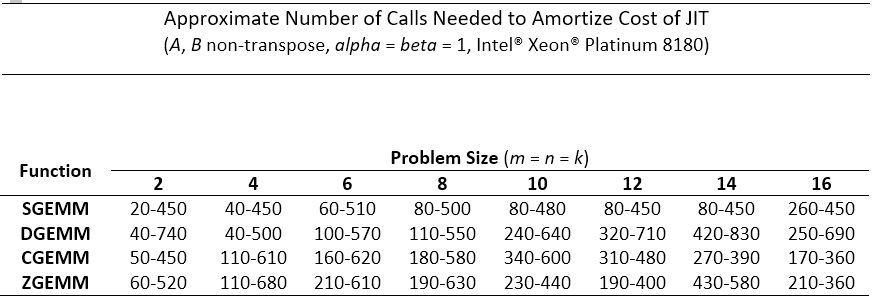
Amortize Code Generation Time
Because generating JIT kernels requires some time, it is typically advisable to use JIT only when you can reuse the generated kernels many times. As a guideline, hundreds of times or more. (Remember that the performance charts in this article assume that the cost of JIT kernel generation is amortized across a large number of calls to the same GEMM kernel.)
Code generation time is only a significant issue for smaller problems where a single GEMM call is hundreds of times faster than generating a JIT kernel. As the input matrices become larger, a single GEMM call requires more time, and code generation time becomes less important.
The following tables provide estimates for the number of function calls required to justify the up-front kernel generation costs of JIT for some small problems rather than using conventional oneMKL GEMM. A range is given for each problem. The upper number in the range represents a program generating only one GEMM kernel. The lower number represents a program generating multiple GEMM kernels. In the tests, all leading dimensions were aligned to multiples of 64 bytes.
Tips for Best Performance
- As with other BLAS routines, align your data to a multiple of 64 bytes (the cache line width) for best performance, if possible. Aligning leading dimensions, especially ldc, to a multiple of 64 bytes may further improve performance.
- If m is very small (approximately m ≤ 16, depending on precision and ISA) and k is moderate to large, storing matrix A transposed can improve performance due to increased vectorization efficiency.
Summary
The JIT capabilities in oneMKL significantly accelerate small matrix multiplication by generating GEMM kernels tailored to the inputs you provide. Two interfaces allow you to use JIT in your own applications. The MKL_DIRECT_CALL_JIT extension transparently enables JIT when it may be beneficial, allowing you to quickly gauge whether JIT can accelerate your application. Or, for best performance, a new dedicated JIT API gives you direct access to generated kernels. For more information, see the oneMKL Developer Reference.