June 15, 2025
Introduction
The GNU* toolchain team at Intel actively collaborated with the GCC* (GNU Compiler Collection) and Binutils communities to integrate innovations and performance enhancements, particularly for x86 architectures, into GCC 15 and Binutils 2.44. This continuous effort underscores our deep and enduring commitment to open-source communities, fostering collaboration that empowers developers throughout the software ecosystem.
We enabled the GCC x86 backend to support all features for the next generation Intel® Xeon® Scalable processor (code-named Diamond Rapids), including
- Intel® Advanced Performance Extensions (Intel® APX)
- Intel® Advanced Vector Extensions 10.2 (Intel® AVX10.2)
- More features for Intel® Advanced Matrix Extensions (Intel® AMX)
- Other features on next Generation Intel® Xeon® Scalable processor (code-named Diamond Rapids)
- Please refer to GCC 15 changes for additional details.
In GCC 15, we made substantial advancements in O2 auto-vectorization, leading to notable performance improvements as evidenced by SPECrate* 2017 benchmarks. Furthermore, the -mtune=sierraforest architecture optimizations were meticulously refined, resulting in significant performance gains. In addition, we contributed numerous patches that enhanced both the quality and performance of the compiler backend.
The support for Intel® Xeon Phi™ processors was removed in GCC 15.
Support for Next Generation Intel Xeon Scalable Processors
The next generation Intel Xeon Scalable processor (code-named Diamond Rapids) introduces many new ISA features, including APX, AVX10.2, more AMX instructions, etc., to boost AI workloads and more general applications. We have supported all the ISA features of the next generation Intel Xeon Scalable processor in GCC 15.
Intel® APX
Intel® APX expands the Intel® 64 instruction set architecture with more general registers and various new features to improve general-purpose performance. The main features of Intel APX include:
- 16 additional general-purpose registers (GPRs) R16–R31, a.k.a. Extended GPRs (EGPRs);
- New data destination (NDD): Extend to three-operand instruction formats with an NDD register for many integer instructions;
- Conditional ISA improvements: Introduce new conditional load, store, and compare instructions;
- Zero-upper (ZU) SETcc: Write full register to reduce extra pre-zeroing instructions and reduce data dependency;
- No Flags (NF): Encode suppress of status flag writes of common instructions;
- Optimized register state save/restore operations: PUSH2/POP2 and PPX(Push-Pop Acceleration);
- A new 64-bit absolute direct jump instruction.
GCC 14 supported some fundamental features (EGPR, NDD, PUSH2/POP2, and PPX). In GCC 15, we enabled the full set of APX features in the next generation Intel Xeon Scalable processor. In addition, many patches were contributed to improve Intel APX codegen optimization and quality. The basic option to enable Intel APX is -mapxf, or an architecture option -march=diamondrapids can be used to enable it.
Intel® AVX10.2
Intel® AVX10.2 contains a set of new instructions delivering new AI features and performance, accelerated media processing, expanded Web Assembly, and cryptography support. It also enhances existing legacy instructions for completeness and efficiency. All of these have been enabled in GCC 15.
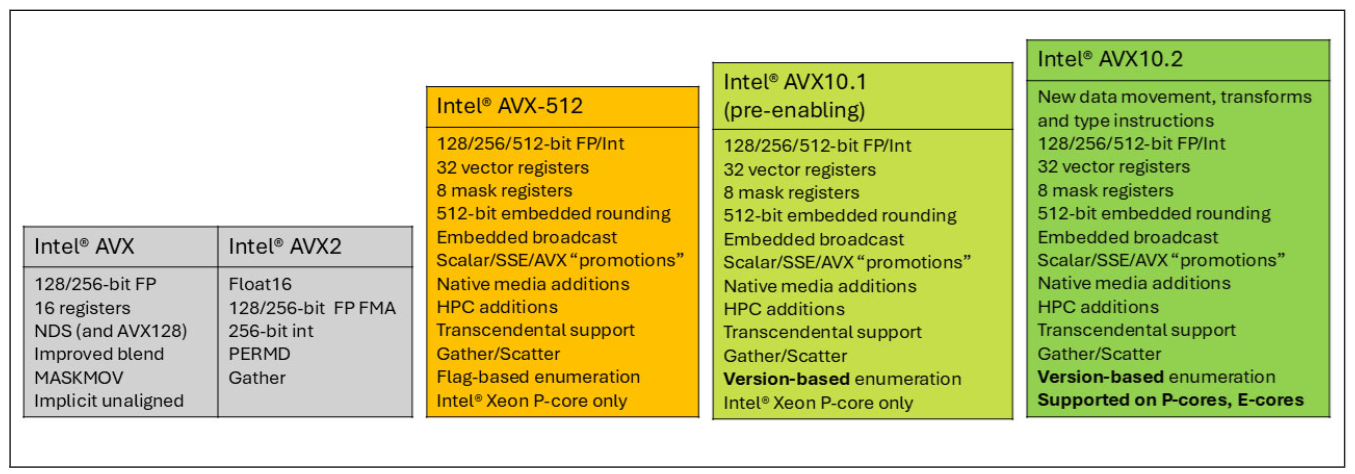
Figure 1: Intel® ISA Families and Features
Moreover, there have been some changes in AVX10 recently, in that the 256-bit mode was removed from the AVX10 architecture. In other words, there is no standalone 256bit-only AVX10 configuration in the future platforms. All AVX10 ISAs will support up to 512-bit vector size, including 256-bit and 128-bit. The details of these changes can be found in the AVX10 technical paper revision 3: "Removed references to 256-bit maximum vector register size, enumeration of vector-length support, and 256-bit instructions supporting embedded rounding".
To adapt to it, the -mavx10.2 option was added to enable AVX10.2 with 512-bit maximum vector size. The -mavx10.1 option was changed from 256-bit to 512-bit. The -mavx10.1-512 -mavx10.1-256 -mno-evxe512 options were deprecated from GCC 15.
New Intel® AMX instructions and others
The next generation Intel Xeon Scalable processor introduces dozens of Intel AMX instructions to further enrich the data types in Intel AMX and accelerate the data movement and processing. A few miscellaneous instructions were added for encryption, etc. All of those instructions have been supported in GCC 15 and Binutils 2.44, as listed below:
- AMX-AVX512
- AMX-FP8
- AMX-MOVRS
- AMX-TF32
- AMX-TRANSPOSE
- MSR_IMM
- PREFETCHRST2
- MOVRS
- SM4
The -march option for upcoming Intel® processors
GCC 15 now supports the next generation Intel Xeon Scalable processor through -march=diamondrapids. Based on the Intel® Xeon® 6 Processor with P-cores (code-named Granite Rapids), the option switch further enables all the new features above, plus some features inherited from the next generation Intel® Core™ Ultra processor (code-named Panther Lake). The new ISA features include the AMX-AVX512, AMX-FP8, AMX-MOVRS, AMX-TF32, AMX-TRANSPOSE, APX_F, AVX10.2, AVX-IFMA, AVX-NE-CONVERT, AVX-VNNI-INT16, AVX-VNNI-INT8, CMPccXADD, MOVRS, SHA512, SM3, SM4, and USER_MSR ISA extensions.
For more details of the intrinsics for those new instructions, see the Intel® Intrinsics Guide.
Generation-to-Generation Performance Improvement
O2 auto-vectorization enhancement
In the latest RHEL 10 release, Red Hat* has upgraded the x86 default ISA (Instruction Set Architecture) level to x86–64-v3 (up to AVX2), from the previous x86-64-v2 (up to SSE4.2 and SSSE3) in RHEL 9. It’s a big step ahead to unleash more vector instructions in modern x86 architectures, potentially bringing significant performance benefits to various applications, particularly in data science and numerical computing domains. In addition to raising the arch level, we need to exploit the vector instructions from compiler optimization.
As most GCC users use O2 optimization by default, we consistently focus on GCC O2 performance improvement. In GCC 12, due to code size concerns from the community, we enabled very-cheap auto-vectorization in O2 with the strict constraint of constant trip count divisible by vector size. However, many trip counts are variable and unknown at compilation time. In GCC 15, we enhanced the very-cheap cost mode into variable trip counts, accompanied by a very limited code size cost. It can produce much more vectorization in O2 optimization and improve performance significantly. SPEC FPrate* 2017 showed +11.34% improvement from GCC 14 to GCC 15, most of which came from O2 auto-vectorization enhancement, as illustrated in Figure 2.
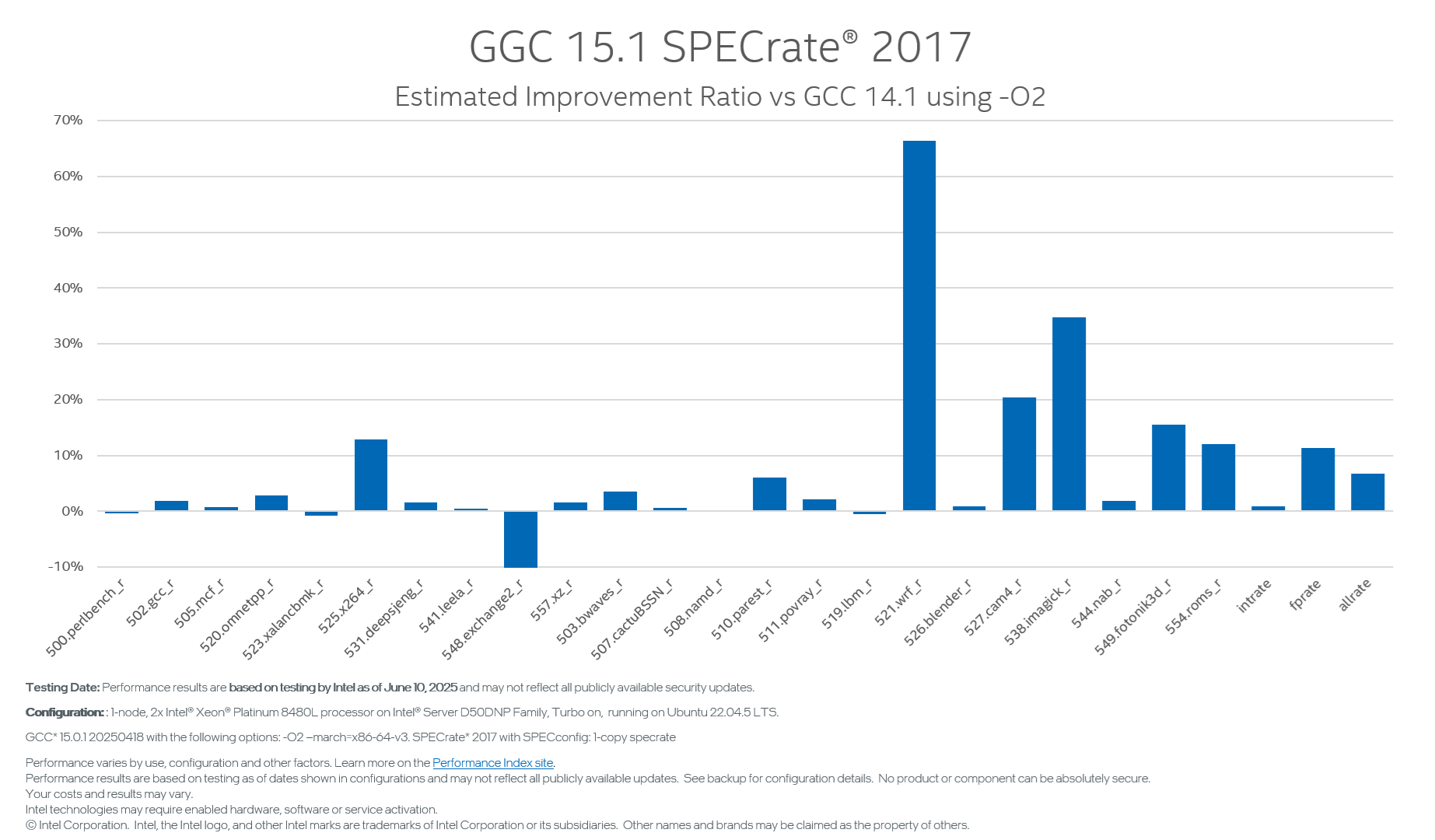
Figure 2: GCC 15.1 -O2 SPECrate* 2017 (1-core) estimated improvement ratio vs GCC 14.1 on 4th Gen Intel Xeon Processor (formerly code-named Sapphire Rapids).
Ofast performance improvement on GCC 15 vs. GCC 14
GCC 15 Ofast performance has also improved by +1.1% for SPECrate 2017. Figure 3 shows the details of the improvement.
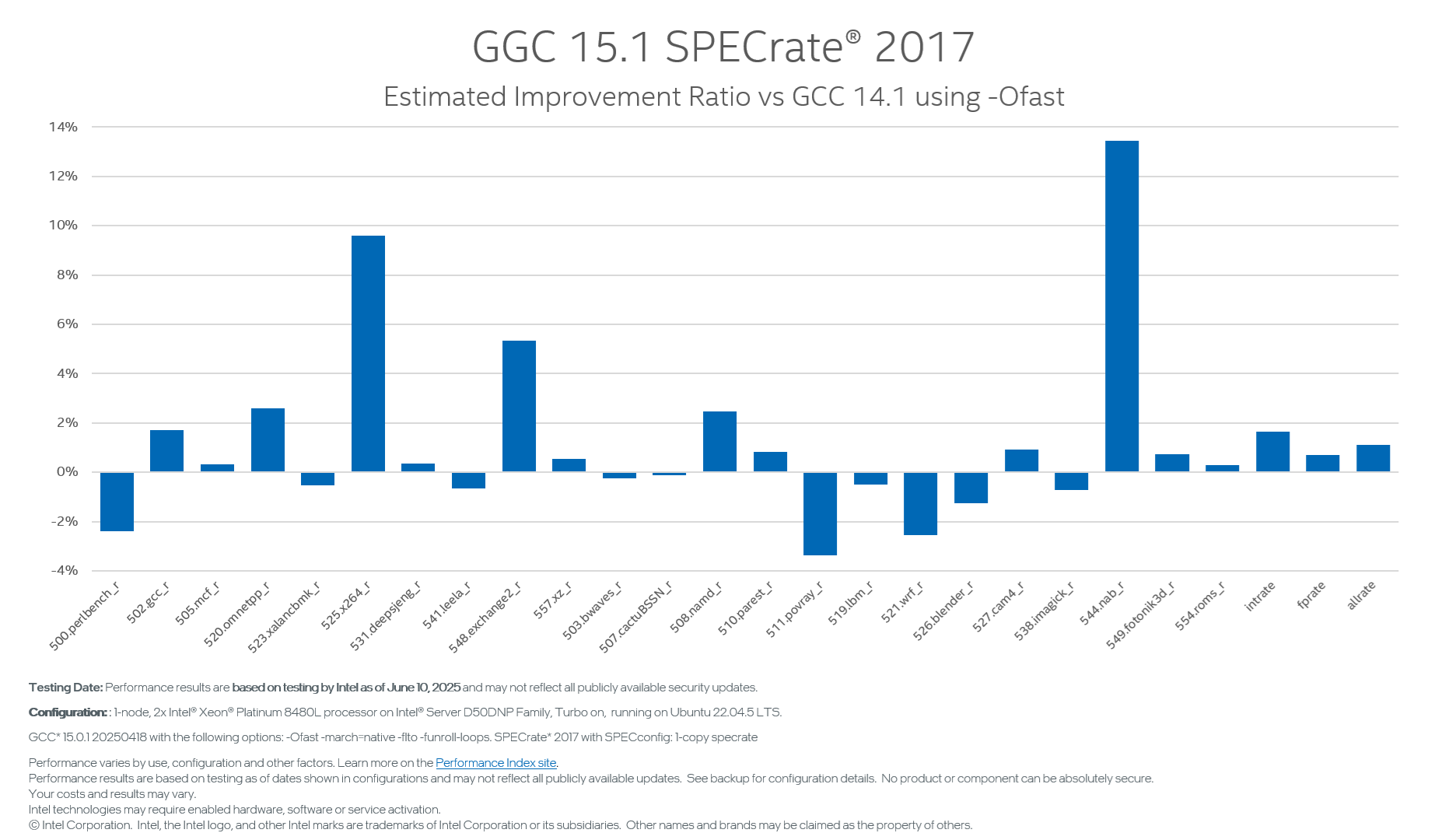
Figure 3: GCC 15.1 -Ofast SPECrate 2017 (1-core) estimated improvement ratio vs GCC 14.1 on 4th Gen Intel Xeon Processor (formerly code-named Sapphire Rapids).
Intel Xeon Processor 6 with E-Cores Tuning
There are some specific tuning chances in the Intel Xeon Processor 6 with E-Cores (code-named Sierra Forest),
- 4-operand vex blendv instruction is decoded from MSROM and slower than a 3-instruction sequence (op1 & mask) | (op2 & ~mask).
- The 256-bit cross-lane permutation instructions are slow due to resource limitations.
2 architecture tunings were added to handle the limitations. The SPEC INTrate* and FPrate 2017 achieved >3% performance gain, most of which came from the enhanced tunings.
Figure 4 shows the total improvement from GCC 14.1 to GCC 15.1
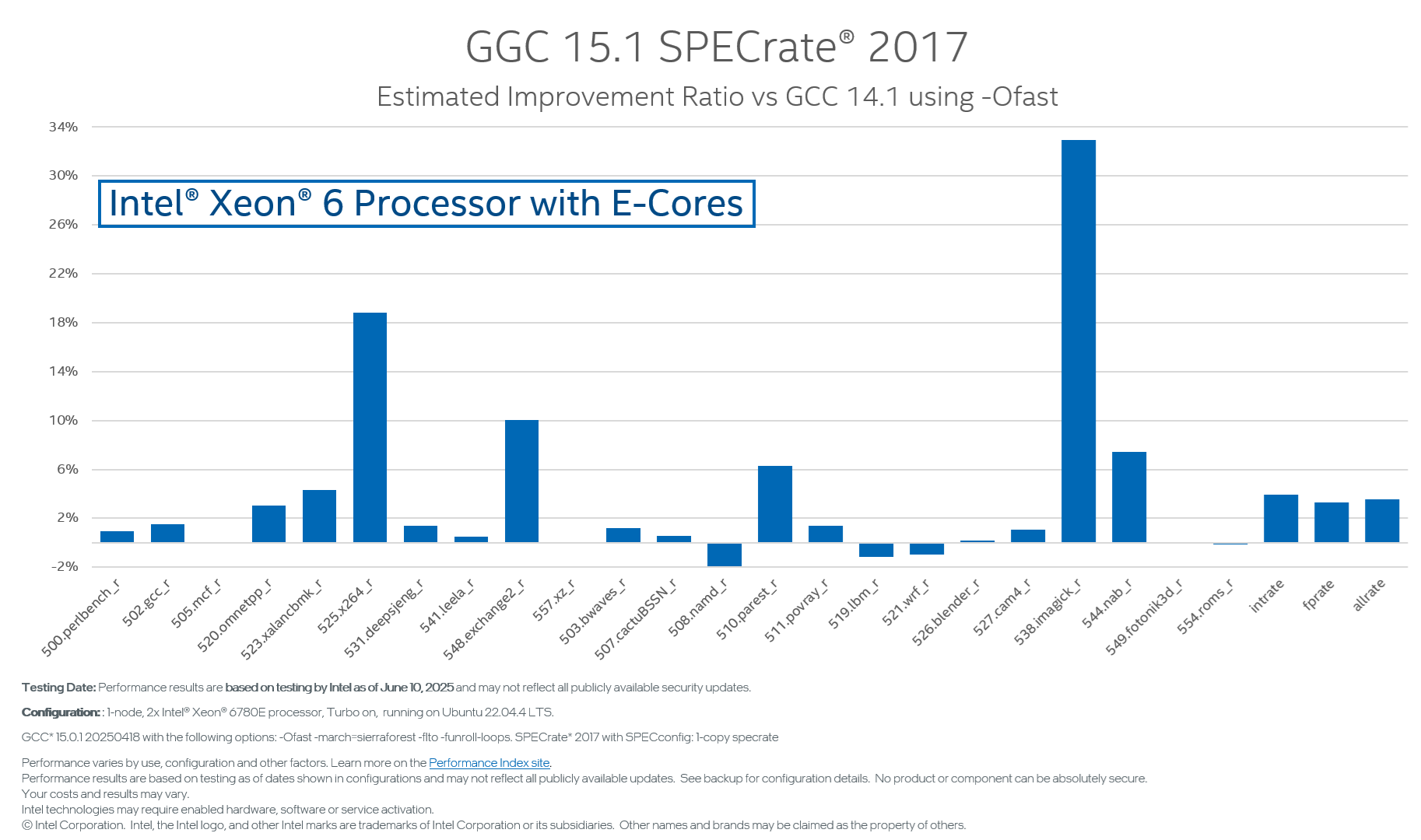
Figure 4: SPECrate 2017 is improved by 3.55% Geomean on Intel Xeon 6 Processor with E-Cores using -march=sierraforest -Ofast -funroll-loops -flto
More Code-Gen Optimization for the x86 Back End
Optimize 3-operand logical operation sequence into a single vpternlog instruction
A sequence of logical instructions with no more than 3 source operands can be optimized into a single vpternlog instruction.
typedef unsigned long long v4di __attribute((vector_size(32)));
v4di foo(v4di a, v4di b, v4di c)
{
return (a & b) | ((a ^ b) & c);
}
foo:
vpternlogq $232, %ymm2, %ymm1, %ymm0
ret
Figure 5: Optimization for AVX-512 vpternlogq (-O2 -mavx512vl)
Optimize vector shift >> 7 to vpcmpgtb for vector int8
There’s no vpsrlb instruction; the shift operation for vector int8 is implemented by extending the operand to vector int16, using vector int16 shift instructions, then truncating it back. But for some special shift counts, it can be transformed into vpcmpgtb.
typedef char v16qi __attribute__((vector_size(16)));
v16qi
__attribute__((noipa))
foo (v16qi a)
{
return a >> 7;
}
foo:
vmovdqa %xmm0, %xmm1
vpxor %xmm0, %xmm0, %xmm0
vpcmpgtb %xmm1, %xmm0, %xmm0
ret
Figure 6: Optimization for vpcmpgtb(-O2 -mavx512vl)
Generate more conditional move
In modern processors, the pipeline goes deeper, so the branch misprediction penalty becomes even larger. The cost model is adjusted to transform a long instruction sequence to cmov. This adjustment benefited one of the SPEC2017 benchmarks a lot.
Improve the Loop alignment strategy
In GCC 15, we changed the loop alignment strategy and always aligned (hot & tight) loops with ceil_log2 (loop_size). This change helps code prefetch and improves the front-end efficiency of the processor architecture.
New Intel Xeon Scalable Processor Macro-Fusions
The 6th generation Intel Xeon Scalable processor microarchitecture (code-named Granite Rapids) supports two new types of instruction macro-fusion: MOV-OP and LOAD-OP. Since moving the load instruction in front of a specific OP might not be good for hardware scheduling, only MOV-OP macro-fusion is enabled in GCC 15.
Future Work
For GCC 16, the Intel team continues to consistently implement new features and improve performance for future Intel platforms. Additionally, we focus our interest on GCC's AutoFDO (Feedback Directed Optimization) feature. We are eager to work together with the GCC community to improve its code quality, profiling accuracy, and performance gain.