Unleash the Full Power of Modern CPUs
Jameson Nash and Jeff Bezanson, Julia Computing, Inc.*, and
Kiran Pamnany, California Institute of Technology (Caltech)
@IntelDevTools
Get the Latest on All Things CODE
Sign Up
Taking advantage of multicore processors is a crucial capability for any modern programming language. Programmers need the best possible throughput for their applications, so we're going to show how the new multithreading runtime in Julia* v1.3 unleashes the full power of a modern CPU with minimal hassle.
One of our key considerations is reducing the programmer’s burden. Julia provides a range of modern primitives designed to compose effectively. We discuss some of the tradeoffs to try to simplify the mental model for the programmer. One important design principle of Julia is to make common tasks easy and difficult tasks possible. This is demonstrated in multiple aspects of the language. For example:
- Automatic memory management
- Combined functions, objects, and templates into a single dispatch mechanism
- Optional type inference for performance
We now extend this to parallelism. By building on the language’s existing concurrency mechanism, we've added parallel capabilities that preserve the (relative) simplicity of single-threaded running for existing code, while allowing new code to benefit from multithreaded running. This work was inspired by parallel programming systems such as oneAPI Threading Building Blocks.
In this paradigm, any piece of a program can be marked for parallel running, and a task starts to automatically run that piece of code on an available thread. A dynamic scheduler determines when and where to launch tasks. This model of parallelism has many helpful properties. It's somewhat similar to garbage collection: You freely allocate objects without worrying about when and how they're freed. With task parallelism, you freely spawn tasks―potentially millions of them―without worrying about when and where they eventually run.
The model is portable and free from low-level details. The programmer doesn’t need to manage threads, or even know how many processors or threads are available. The model can be nested and composed. Parallel tasks can be started that call library functions that themselves start parallel tasks and everything works correctly. This property is crucial for a high-level language where library functions do a lot of work. The programmer can write serial or parallel code without worrying about how the underlying libraries are implemented. This model isn’t limited to Julia libraries either. We've shown that it can be extended to native libraries such as Fastest Fourier Transform in the West (FFTW), and we are working on extending it to OpenBLAS.
Run Julia with Threads
Let's look at some examples using Julia v1.3 launched with multiple threads. To follow along on your own machine:
- Get the latest Julia release from Downloads.
- Do one of the following:
- Run ./julia with the environment variable JULIA_NUM_THREADS set to the number of threads to use.
OR - Install the Juno IDE* by following the steps at Installation. It automatically sets the number of threads based on available processor cores. It also provides a graphical interface for changing the number of threads.
- Run ./julia with the environment variable JULIA_NUM_THREADS set to the number of threads to use.
We can verify that threading is working by querying the number of threads and the ID of the current thread:

Figure 1
Tasks and Threads
To demonstrate that threads are working, you can watch the scheduler picking up work in semirandom, interleaving orders. Previous versions of Julia already had a @threads for macro that split a range and ran a portion on each thread with a static schedule. So in the following range:
- Thread 1 runs items 1 and 2.
- Thread 2 runs items 3 and 4.
And so on.

Figure 2
It’s now possible to run the same program with a completely dynamic schedule. Use the new @spawn macro with the existing @sync macro to delineate the work items.

Figure 3
Now, let's look at some more practical examples.
Parallel Merge Sort
The classic merge sort algorithm shows a nice performance benefit from using multiple threads. This function creates O(n) subtasks that sort independent portions of the array before merging them into a final sorted copy of the input. We use the ability of each task to return a value via fetch.

Figure 4
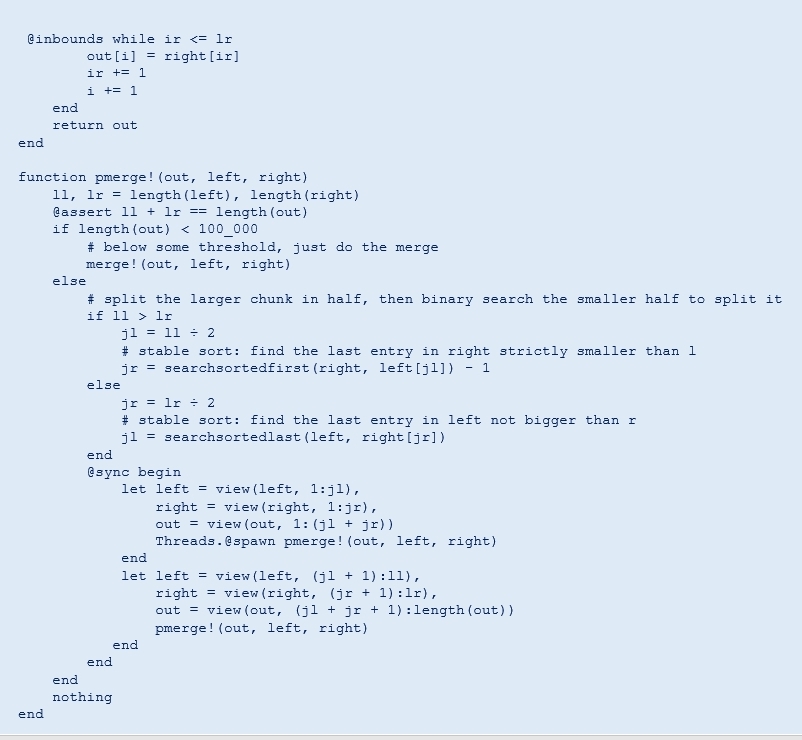
Figure 5
Figure 6 shows how adding more threads affects scaling. Since we're using in-process threads, we could further optimize them by mutating the input in place and reusing the work buffers for additional performance.
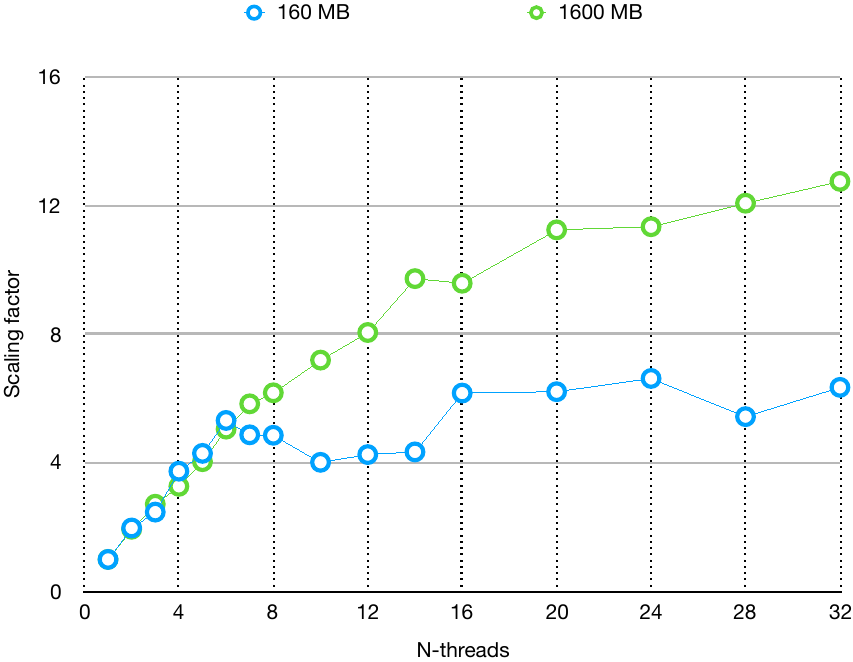
Figure 6. Scale ratios of psort on a server with 40 instances of Intel® Hyper-Threading Technology (two Intel® Xeon® Silver 4114 processors at 2.20 GHz)
While not demonstrated here, fetch would also automatically propagate exceptions from the child task.
Parallel Prefix
Prefix sum (also known as scan sum) is another classic problem that can benefit nicely from multiple threads. The parallel version of the algorithm computes partial sums by arranging the work into two trees. The following short implementation can take advantage of all cores and Single Instruction Multiple Data (SIMD) units available on the machine:

Figure 7
Figure 8 shows how adding more threads affects scaling.
Several features of Julia combine to facilitate expressing this basic yet performant implementation. Under the hood, the system automatically compiles versions of the function optimized for different types of arguments. The compiler can also automatically specialize the function for a specific CPU model, both ahead of time and just in time. Julia ships with a system image of code precompiled for a reasonable range of CPUs, but if the processor used at runtime supports a larger feature set, the compiler automatically generates better-tailored code. Meanwhile, the threading system adapts to the available cores by dynamically scheduling work.
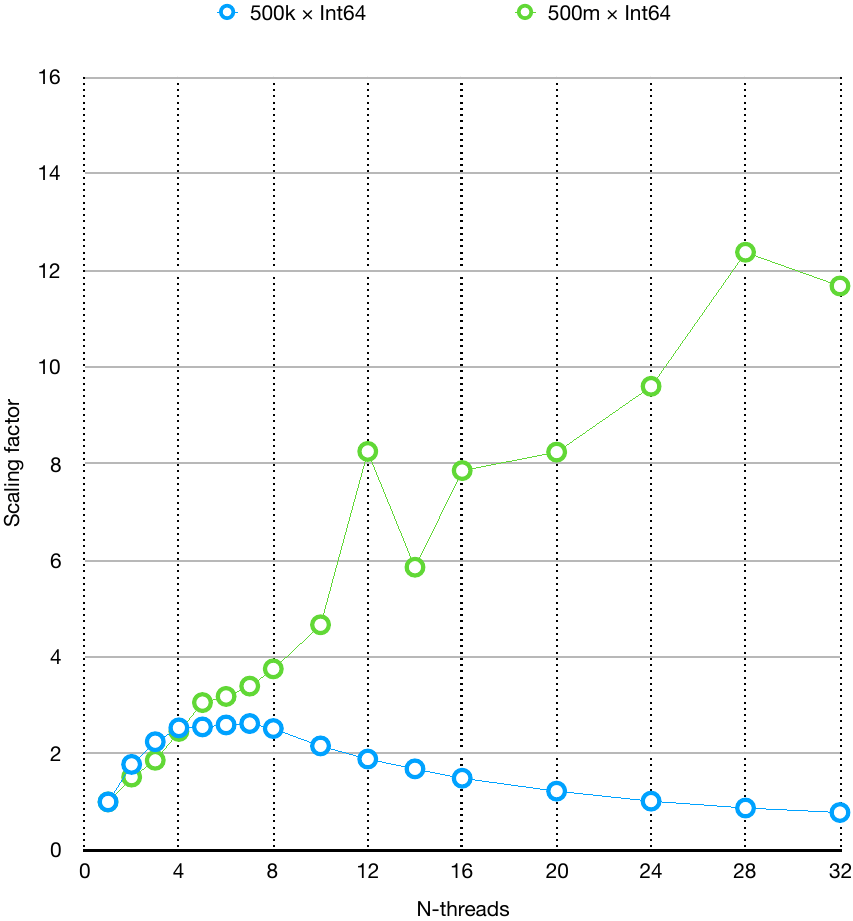
Figure 8. Scaling ratios of prefix_threads on a server with 40 instances of Intel Hyper-Threading Technology (two Intel Xeon Silver 4114 processors at 2.20 GHz)
Parallel-Aware APIs
Several operations in application code must be made thread-aware to be used safely in parallel. These user-facing APIs include:
- Concurrency Basics: Task and associated functions including schedule, yield, and wait
- Mutexes: ReentrantLock and Condition variables, including lock, unlock, and wait
- Synchronization Primitives: Channel, Event, AsyncEvent, and Semaphore
- I/O and Other Blocking Operations: Includes read, write, open, close, and sleep
- Experimental Threads Module: Various building blocks and atomic operations
Scheduler Design
A prototype implementation of the partr scheduler was first written for us in C by Kiran Pamnany while at Intel in late 20161, following research on cache-efficient scheduling2. The goal of this work was to compose threaded libraries with a globally depth-first work ordering. partr implements the prototype using an approximate priority queue, where the priorities are set equal to the thread ID of the thread launching a task.
Foreign Libraries
An important motivation for this work was our desire to better support multithreaded libraries without CPU oversubscription killing performance due to cache-thrashing and frequent context switching. Previously, the only options were for the user to decide up-front to limit Julia to N threads, and to tell the threaded library (such as libfftw or libblas) to use M ÷ N cores. The most common choices are probably 1 and M, so only part of the application can benefit from multiple cores. However, given our ability to quickly create and run work items in our thread pool, we're looking at how to let external libraries integrate with it. This is an ongoing area of exploration as we get feedback on the performance and API needs of various libraries.
We've successfully adapted FFTW to run on top of our threading runtime instead of its own (a pthreads-based work pool). This took the authors only a few hours (they were fortunate to be able to get help from that library’s author). Without any performance tuning (yet), it got competitive performance results. The authors learned important lessons to tightly optimize scheduler latency, which is now ongoing work to achieve exact performance parity. Even with some overhead imposed by generality, however, we expect that the ability to compose thread-aware users and achieve resource sharing from the partr scheduler makes this an overall improvement in program operation.
Conclusion
The Julia approach to multithreading combines many previously known ideas in a novel framework. While each in isolation is useful, we believe that―as is so often the case―the sum is greater than the parts. From this point, we hope to see a rich set of composable parallel libraries develop within the Julia ecosystem.
References
- partr (GitHub*)
- Shimin Chen, Phillip B. Gibbons, Michael Kozuch, Vasileios Liaskovitis, Anastassia Ailamaki, Guy E.
Blelloch, Babak Falsafi, Limor Fix, Nikos Hardavellas, Todd C. Mowry, and Chris Wilkerson. "Scheduling
Threads for Constructive Cache Sharing on cmps." Proceedings of the Nineteenth Annual Association for Computing Machinery (ACM) Symposium on Parallel Algorithms and Architectures (SPAA, New York, NY, USA, 2007), 105–115
______
You May Also Like
Intel® oneAPI Threading Building Blocks (oneTBB)
Simplify the task of adding parallelism to complex applications across diverse architectures. oneTBB is included as part of the Intel® oneAPI Base Toolkit.
| Intel® oneAPI Threading Building Blocks (oneTBB) Simplify the task of adding parallelism to complex applications across diverse architectures. oneTBB is included as part of the Intel® oneAPI Base Toolkit. |