The Deep Learning Workbench (DL Workbench) included in the Intel® Distribution of OpenVINO™ toolkit allows developers to easily:
- Profile and visualize throughput, latency and accuracy of deep learning models on various Intel® architecture, so they can identify and tune performance bottlenecks
- Boost performance through lowering the precision to INT8 or Winograd, especially on edge inference devices which may already be oversubscribed with heavy workloads
For more introductory information about DL Workbench, please refer to the previous blog New Deep Learning Workbench Profiler Provides Performance Insights.
In the latest release (R3.1) of Intel® Distribution of OpenVINO™ Toolkit, DL Workbench offers Model Optimizer integration via the import Original Model feature, allowing import of popular DL models from the Internet or your own custom built models which are in the original framework format. As a result, it is no longer necessary to point DL Workbench to IR files generated by Model Optimizer offline, although this option still exists if needed. This release also includes:
- Model Optimizer support within Deep Learning Workbench (DL Workbench). Now you can start using DL Workbench with an original pre-trained model and proceed to model profiling and optimization through an intuitively clear conversion step. The conversion step is simplified by the internal analysis of the provided model and suggests required Model Optimizer parameters.
- Simplified model import process in the Deep Learning Workbench (DL Workbench). The new flow does not require that you set parameters for accuracy measurement during the import step. The parameters are required only if you want to measure accuracy and/or conduct INT8 calibration. This significantly simplifies user journey for first inference experiments and decreases the learning curve while keeping all the necessary functionality for advanced users.
- Simplified installation through Docker* Hub of the Deep Learning Workbench (DL Workbench). While you can still build DL Workbench from the OpenVINO™ installation, now you can easily download it from Docker* Hub.
This release offers support for many more models, both FP32 and FP16 data types, across several industry-recognized frameworks, including Tensorflow*, Caffe*, Apache MxNet*, PyTorch* and Paddle Paddle* (via ONNX*), as well as optimized INT8 versions of models.. Currently, the Linux* version of the DL Workbench runs with support for CPUs, integrated GPUs and Intel® Movidius™ VPUs but only CPUs can benefit from INT8 or Winograd optimization.
The DL Workbench backend is a Docker* container, so developers can use the pre-built one on Docker* Hub or they can build their own. The easiest way to get started with the current version of DL Workbench is to run this command (Linux example):
1)
sudo docker run -p 127.0.0.1:5665:5665 --name workbench --privileged -v /dev/bus/usb:/dev/bus/usb -v /dev/dri:/dev/dri -e PORT=5665 -e PROXY_HOST_ADDRESS=0.0.0.0 -it openvino/workbench:latest2) Point a web browser which runs on the Linux system to http://0.0.0.0:5665 and voila ! You got your DL Workbench profiler.
Step-by-step installation and run instructions are provided here
3) Next import a compatible data set in the correct format. Currently ImageNet* (for classification) and Pascal VOC* (for Object Identification) are supported. You can also import your own data set as long as it's converted to the correct file-structure and annotation-file format (ImageNet* or VOC*).
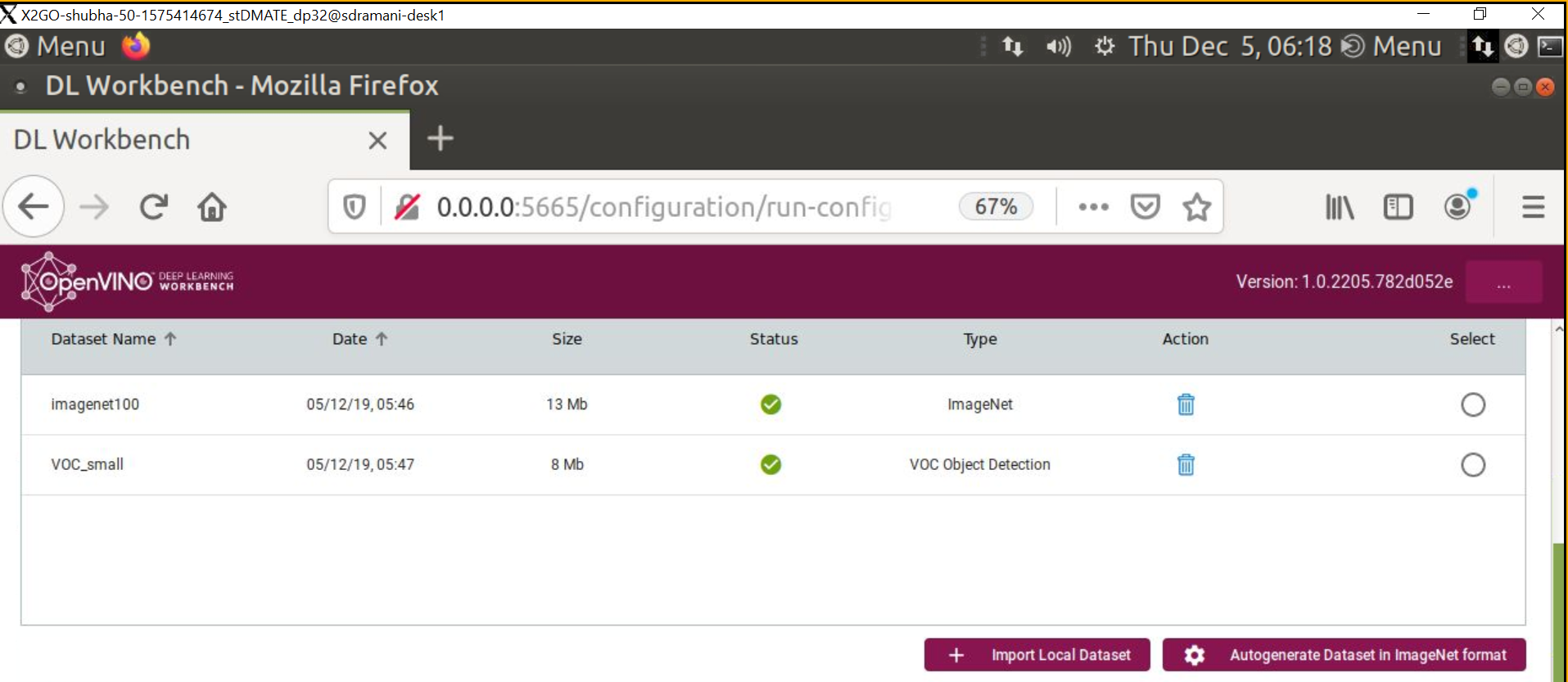
If you don't have a dataset handy, DL Workbench will allow you to auto-generate your own dataset in ImageNet* (file-structure and annotation file) format. Keep in mind that, if this option is used, the images will consist of random noise, which is sufficient for performance measurements but inadequate for accuracy measurements.
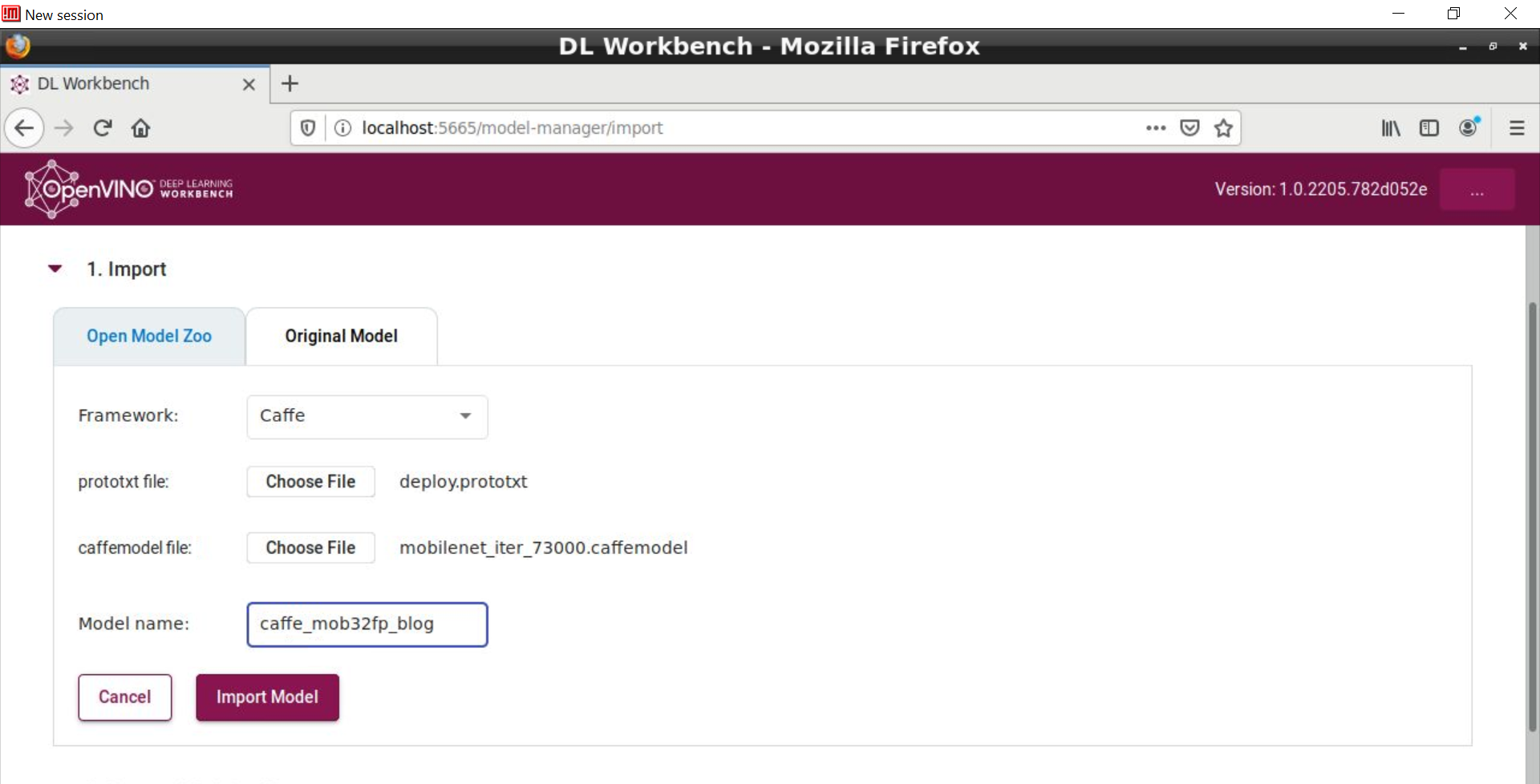
Importing a model from the more than 40 choices available within Model Zoo is highly recommended, since these models include both models developed by Intel and models vetted, tested and, in some cases, optimized (INT8) and popularized via the Internet Note, however, that you can also use the Import Original Model button. In this case, DL Workbench now automatically runs the Model Optimizer command under the hood, prompting you to import relevant model files. Following is an example for Caffe ssd-mobilenet:
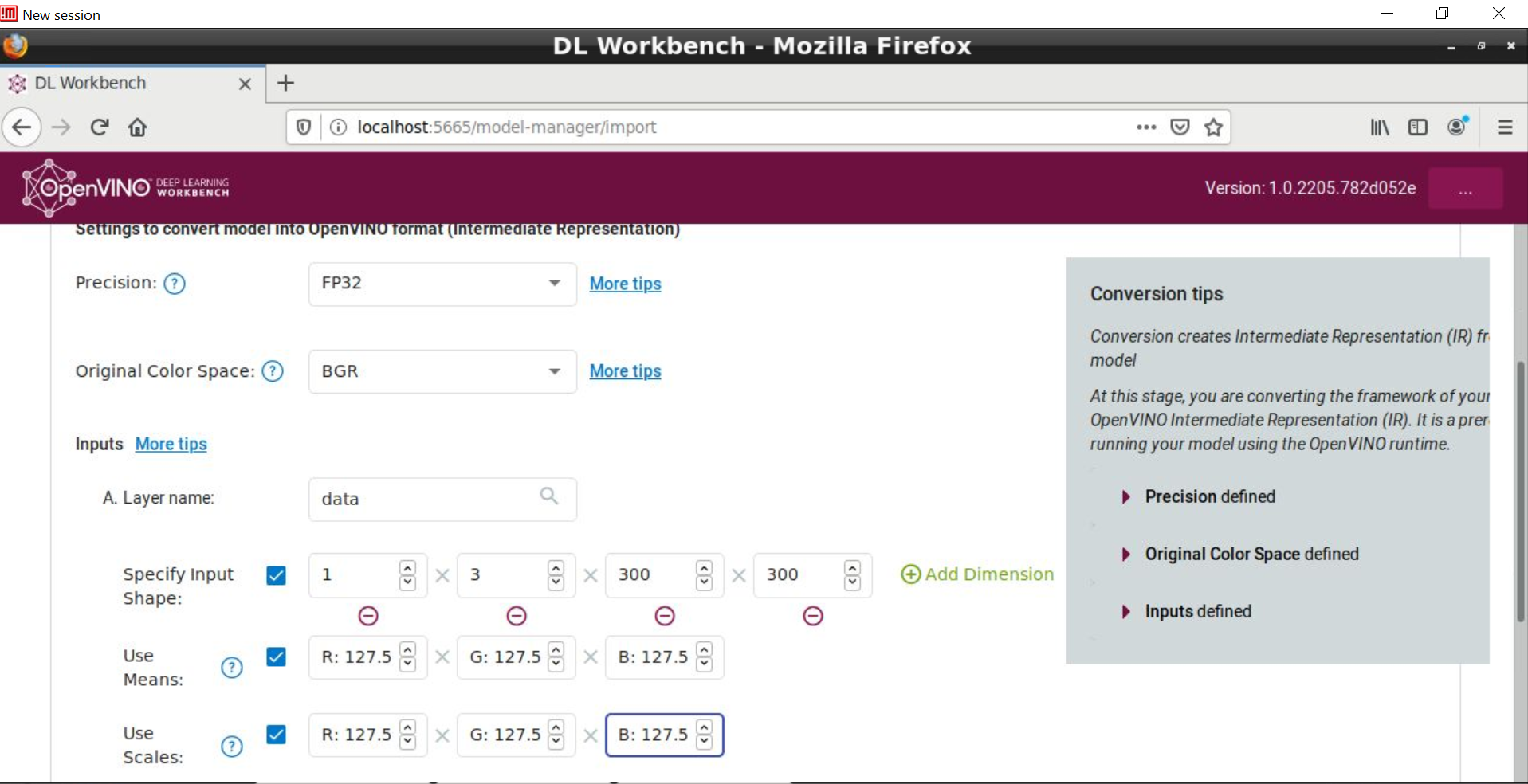
As you step through the DL Workbench screens you will also be prompted to enter image size as well as --mean_values and --scale_values and --reverse_input_channels pre-processing switches which are ordinarily passed in through the Model Optimizer command-line tool. As discussed in the previous blog post such pre-processing switches (mean values, scale values, input channels order) need to be explicitly defined and input onto Model Optimizer (and now DL Workbench) in order to generate correct IR which actually reflects how the model was trained.
Now, in both the Model Zoo and Original Model scenarios, DL Workbench invokes Model Optimizer under the hood, and in the latter case, if the model is supported by DL Workbench, inputting pre-processing switches is a seamless endeavor. For the Original Model, you will have the option to import Framework types OpenVINO (IR), Caffe*, Apache MxNet*, ONNX*, and Tensorflow*. OpenVINO (IR) handles the case where the Original Model is not recognized by DL Workbench or you wish to have full control over the Model Optimizer process, so you will need to import the generated *.xml and *.bin files after running Model Optimizer on the model manually. In addition, when the user chooses Import from Model Zoo, the recognition of whether the model is of Classification or Object Detection type is automatically determined by DL Workbench.
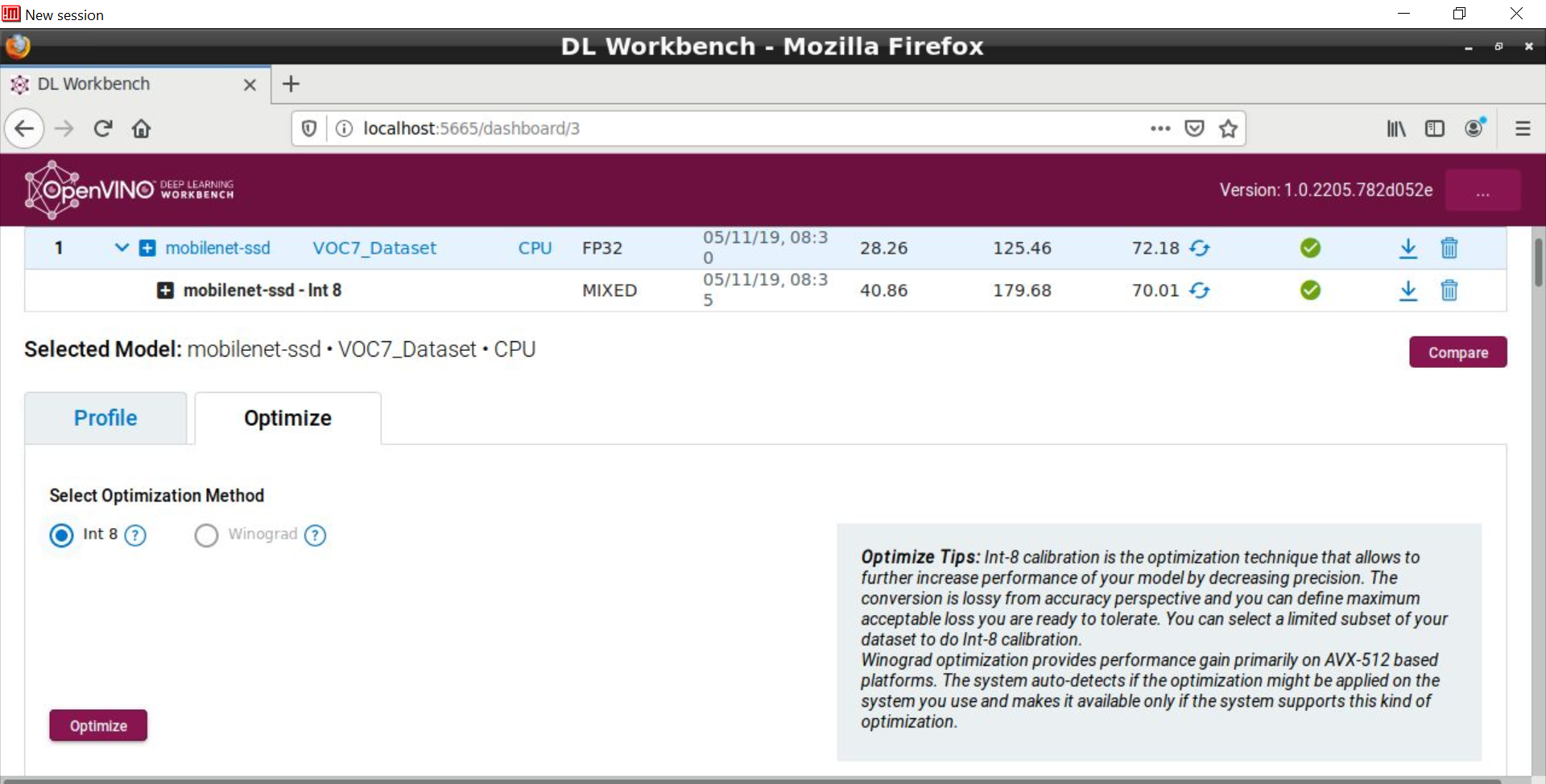
This version of DL Workbench provides several helpful tips throughout, an example being the Optimize Tips shown below.
We welcome and encourage your input, comments and questions. Please engage with us through the Computer Vision Forum, or by using the tag #OpenVINO on Stack Overflow.