Introduction
The networking world is rife with buzz words like SDN, NFVs, Cloud, and Virtualized everything for network switches, routers, firewalls, load balancers, web servers, and other communication functions. In recent years, market trends have been moving away from expensive, specialized hardware, which is not easily scalable and quickly becomes obsolete, to using relatively inexpensive network interface cards (NIC) on common server systems. Meanwhile, these commodity NICs and their related software drivers have gained advanced functions that can offload from the CPU more complex routing and traffic processing. The result is that a single NIC can replace the specialized devices for much less cost and can easily be reconfigured as requirements change.
The transformation to achieve this goal had to occur both in the NIC hardware design and in the supporting software. With this combination we have general purpose building blocks that can understand and utilize hardware’s capabilities to provide an extremely powerful network. However, the system and network administrators must know how to configure these tools to get the most out of their investments.
Although the idea of building specialized networks and network components from commodity NICs is discussed in many places, this information often doesn’t include the details that tell us where to start, what to use, and the choices we will have to make. Configuration of a server becomes a complex task that must be achieved with minimal overhead. What is needed are some detailed examples to guide us through what we might need for our networks. In this article we describe several recipes for building such network functions.
Setting the Table
Network design and optimization is the fine art of tuning network throughput, data latency, and CPU utilization while scaling a single device to multiple endpoints and making it fit any network device profile. Any general purpose network device that can provide the hardware and software support to configure these characteristics qualifies to be a building block for making software-defined networks (SDN) a reality.
Plates and Napkins
As CPUs have evolved to support multicore parallel operations, similar transformations have happened in network chips: they have gone from single function, single queue to multifunction, multiqueue devices. Various network device vendors have raced to make more and more parallelized HW flows, while adding capabilities to do a lot more of the network stack's work, also known as HW offloads. With virtualization support in the platform, these network devices can show up as multiple devices either through Single Root I/O Virtualization (SR-IOV) support or through Virtual Machine Device Queues (VMDq) support, both to improve virtual machine (VM) performance.
Early data centers invested in specialized pieces of equipment such as switches,routers, and firewalls. With the advent of high-speed CPUs, low-latency caching and high-speed commodity server NICs, building these specialized gateway modules with general purpose components provides similar performance at a fraction of the cost. This solution has the added benefits of configuration flexibility and virtualization. High-speed processing is enhanced by distributing the flows to allow parallel processing on the platform.
The data centers, too, have evolved to cater to multi-tenant, multi-application configurations. The hypervisor supporting the tenant VMs provides secure isolation between the VMs along with value-added services such as ACL and metering support. The networking between these isolated VMs also needs isolation, and our advanced devices include support for specialized tunneling and traffic routing to help with this.
To provide these features, the new server NICs have programmable parts that can be configured to any specialized role on the fly, and many network function roles can be played by a single NIC. But how do we access these bits?
Knives, Forks, and Spoons
The Linux* operating system tends to be a major player in the data center world, so we’ll use it and its tools in this discussion in order to give specific descriptions. Some of the basic tools we use include
- Ethtool. Queries and sets various network driver and hardware settings, such as reading device statistics, adjusting interrupt handling, and setting special receive filters.
- ifconfig/ifup/ifdown. Configures a network interface, such as for setting an IP address. Note that this tool has been deprecated and replaced by ip addr and ip link.
- vconfig. Sets vlan tagging and filtering on a network interface.
- ip link and ip addr. These are parts of the iproute2 package, a collection of several facilities that manipulate network interfaces. They are newer functions meant to be more flexible than the ifconfig and vconfig tools that they replace.
- brctl. Manages Ethernet bridge configurations.
Using these tools in standard setups is usually unnecessary—Linux distributions today usually do a good job of setting up the networking system by default. Startup scripts using dhclient and NetworkManager usually can take care of finding and connecting to the local network. However, our tools come in handy when we need to do something “different” in order to set up our special needs.
Starters
Simple NIC
Our starting point is the simple NIC, a single path for all the packets. In this case, all the incoming and outgoing packets use a single traffic flow, and processing typically happens on a single CPU core. The NIC is not meant for heavy traffic handling, so we don’t worry much about tuning for performance. The only real consideration is to be sure the network port has a useful network address. If DHCP is not available on the network or dhclient is not running on the NIC’s port, we’ll need to set the address and start the device:
The NIC is not meant for heavy traffic handling, so we don’t worry much about tuning for performance. The only real consideration is to be sure the network port has a useful network address. If DHCP is not available on the network or dhclient is not running on the NIC’s port, we’ll need to set the address and start the device:
- ifconfig eth1 192.168.101.13
Set the IP address for the device.
- ifconfig eth1 up
Turn the device on and start processing packets.
Multiqueue
With newer devices, we add multiqueue processing in the NIC, which can offload some of the traffic placement processing from the CPUs. In the simplest case, the NIC can provide load balancing across the CPU cores by inspecting the incoming packet header and sorting the traffic by “conversation” into core-specific message queues. If the NIC knows that a consumer for messages on TCP port 80 (web server) is on core 3, the NIC can put those packets in the core 3 packet queue. This process would then be separate from the database traffic being handled on core 2 and the video traffic on core 0. Each packet queue has its own interrupt line assigned to the related cores, and now video traffic and interrupts can be processed without bothering the database or web server processing. This process also helps with cache locality, keeping data on a single core instead of needing to move it around from cache to cache.
If the NIC knows that a consumer for messages on TCP port 80 (web server) is on core 3, the NIC can put those packets in the core 3 packet queue. This process would then be separate from the database traffic being handled on core 2 and the video traffic on core 0. Each packet queue has its own interrupt line assigned to the related cores, and now video traffic and interrupts can be processed without bothering the database or web server processing. This process also helps with cache locality, keeping data on a single core instead of needing to move it around from cache to cache.
There are several ways to filter the traffic, but the primary tools are Receive Side Scaling (RSS) and Flow Director (FD). In most devices, these are setup automatically to work with the kernel to spread the processing load. However, they can be configured by hand using ethtool. For example:
- ethtool -L eth1 combined 64
ethtool –l eth1
By default, the device tends to set up as many Tx and Rx queues as there are CPU cores. The -L command can override this and change to more or fewer queues. The “combined” tag keeps the Tx count equal to the Rx. The -l command prints the current setting. - ethtool -X eth1 equal 32
ethtool -X eth1 weight 10 20 30
ethtool -x eth1
The -X command configures how the RSS hashing is spread across the receive queues. “equal 32” will spread the load across 32 queues, which might be done to keep the traffic off of the other 32 queues in a 64-core server. The “weight …” tag sets the load proportions across the cores. The -x command prints the current distribution. - ethtool -N eth1 flow-type tcp4 src-ip 192.168.60.109 dst-ip 192.168.60.108 src-port 5001 dst-port 5001 action 4 loc 1
ethtool –n eth1
The FD configuration command allows very specific targeting of traffic to a core, allowing you to select by traffic source and destination, port number, message types, and a few other specifiers. In this example, an IPv4 TCP message coming from 192.168.60.109 and using port 5001 is put into queue number 4, and this rule will be stored as rule 1.
Main Dishes
VMDq
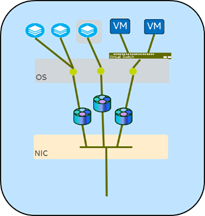 Another way to offload traffic decisions is to set up VMDq handling, which is primarily for supporting VMs with different network addresses from the server on which they are hosted. With a simple command you can set up “virtual” network devices (for example, eth1, eth2, eth3, …) all on top of the a single hardware NIC. In those NICs that support it, the new virtual network devices can have their own MAC addresses and network traffic queues, and can then be assigned to specific jobs (VMs, containers, etc.) in the host server.
Another way to offload traffic decisions is to set up VMDq handling, which is primarily for supporting VMs with different network addresses from the server on which they are hosted. With a simple command you can set up “virtual” network devices (for example, eth1, eth2, eth3, …) all on top of the a single hardware NIC. In those NICs that support it, the new virtual network devices can have their own MAC addresses and network traffic queues, and can then be assigned to specific jobs (VMs, containers, etc.) in the host server.
The NIC is able to sort the inbound traffic into a set of queues set aside specifically for that VMDq path. This can be used by full-fledged VMs, lightweight containers, or other similar entities that would have a different address from the host server. This allows for separate control and configuration of the traffic. Specifying different “modes” of connection—bridge, passthru, private, or vepa—control whether the VMDq ports can talk to each other and how they connect outside the server.
The easiest to use is the MAC-VLAN style, which will support most standard TCP and UDP type messaging. First create a VMDq device (the MAC address is generated for you), then give it an IP address:
- ip link add veth1 link eth0 type macvlan mode bridge
Split off a VMDq device named “veth1” from the existing “eth0” device. Using “bridge” mode allows this to talk with other bridge mode VMDq devices from the same eth0. - ip addr add 10.10.10.88/24 broadcast 10.10.10.255 dev veth1
Instead of using the deprecated ifconfig command, here we use the newer iproute2 command to assign the address and broadcast mask for the new virtual device.
The MAC-VTAP device can give you more low-level control, such as choosing your own specific MAC address.
- ip link add macvtap2 link eth0 address 00:22:33:44:55:66 type macvtap mode passthru
ip addr add 10.10.12.88/24 broadcast 10.10.12.255 dev macvtap2
ip link set macvtap2 up
Set up a new macvtap link with a specific MAC address, set the IP address, and start the processing. - ip link show macvtap2
Print the details on the new device.
Tunneling
In building larger, more complex data centers that will support many customers, traffic must be separated so that individual customers cannot see each other’s network traffic.  The hard way to do this is to have completely separate wires and computers for each customer. Since this approach is rather impractical and inflexible, other methods are required.
The hard way to do this is to have completely separate wires and computers for each customer. Since this approach is rather impractical and inflexible, other methods are required.
With “tunneling” we hide each network message inside of another message by adding additional message headers. These headers are used for routing around the data center and then are stripped off when the message is delivered to the appropriate customer’s applications. The customers’ loads can now be spread across compute servers as needed to manage the data center, and yet the network traffic seen by the customer remains constant and private. These become virtual “overlays” on the physical network.
There are several different types of tunneling, such as VXLAN, GRE, Geneve, and IPinIP, and the ip link commands are able to set them up.
For example, for a VXLAN tunnel into a local virtual switch:
- ip link set eth1 mtu 1600
Set the MTU (maximum transmission unit size) to a larger value to make room for the extra tunneling header. - ip link add br200 type bridge
Create a local bridge named br200 to work as a virtual switch.
- ip link add vx200 type vxlan id 5000 group 239.1.1.1 dstport 4789 dev eth1
Create the VXLAN tunnel endpoint named vx200 attached to the physical network interface, using an id number of 5000 and passing the traffic through the physical interface on UDP port 4789. - brctl addif br200 vx200
Attach the tunnel endpoint to the virtual switch. - ip link set br200 up
Start the bridge processing. - ip link set vx200 up
Start the tunnel processing. - ifconfig eth1 172.16.10.7/24
Set the physical device’s IP address. - ip link set eth1 up
Start the physical network device processing.

The above example requires the OS to do the sorting for which messages go to eth1 and which go to the tunnel endpoint. We can make use of the NIC’s traffic handling to do the sorting without impacting the CPU by building a VMDq channel and directing the tunnel messages into the VMDq device.
Single Root IO Virtualization
One of the issues with these networking paths is that they add some amount of processing load in the host OS. Worse, when supporting VMs, the message traffic gets copied from host buffers to VM buffers, and then processed again in the VM OS.
 If we know the traffic needs to go into a VM, we could get better throughput if we can bypass the host OS altogether. This is the basis of SR-IOV: with support from the NIC hardware, portions of the PCI (Peripheral Component Interconnect) device can be essentially “split off” and dedicated to the VM. We call these portions Virtual Functions, or VFs. We can set up a number of these per physical device and give them their own MAC address, and the physical NIC will do the traffic sorting and place the packets directly into the VM’s OS buffers.
If we know the traffic needs to go into a VM, we could get better throughput if we can bypass the host OS altogether. This is the basis of SR-IOV: with support from the NIC hardware, portions of the PCI (Peripheral Component Interconnect) device can be essentially “split off” and dedicated to the VM. We call these portions Virtual Functions, or VFs. We can set up a number of these per physical device and give them their own MAC address, and the physical NIC will do the traffic sorting and place the packets directly into the VM’s OS buffers.
A script for a typical setup of four VFs on the host might look something like this:
dev=eth1
num_vfs=4
ip addr add 192.169.60.108/24 dev $dev
echo $num_vfs > /sys/class/net/$dev/device/sriov_numvfs
sleep 1
for (( c=0; c<$num_vfs; c++ )) ; do
ip link set $dev vf $c mac 00:12:23:34:45:$c
doneIn the VM, the VF is assigned as a pass-through device and shows up just as any other PCI network device would. The simple IP address assignment in the VF then is:
ip addr add 192.168.50.108/24 dev eth0
Fancy Feasts
Tunnels Revisited
Now that we have direct traffic placement into the VM, we can add tunneling such that the VM doesn’t know that it is part of a tunnel. This gives arguably the best separation, security, and performance for customer applications.
Using FD again, we can select our tunnel traffic and aim it at the VF. In this case, we’ll use VF number 4. We’ll place the rule in location 4 rather than whatever would be chosen by default, so we edit the rule later as needed. We use the 64-bit user-def field to tell the driver to give traffic on port 4789 to VF number 2, and the action says to deliver it to the VF’s queue 1:
ethtool -N eth1 flow-type udp4 dst-port 4789 user-def 2 action 1 loc 4
That works well if we have a specific VF for all tunneled traffic. However, if we want to inspect the inner message for a vlan id and sort it into a specific VF, we need to make use of the upper part of the 64-bit user-def field to specify the id to be used, which in this example is 8:
ethtool –N eth1 flow-type ether dst 00:00:00:00:00:00 m ff:ff:ff:ff:ff:ff src 00:00:00:00:00:00 m 00:00:00:00:00:00 user-def 0x800000002 action 1 loc 4
Network Functions Virtualization for Appliances
A growing use of network features in support of virtualization is for SDN and Network Functions Virtualization (NFV). NFV takes what have traditionally been network appliances in separate boxes that do specific processing, such as firewalls, security inspections, network load balancing, and various DPDK-based applications, and puts them into a VM that can run on a “generic” server. This saves money as these are cheaper than the hardware network appliance. They also add flexibility, because you can move them around in the network when needs change, without physically moving a box or changing any wiring.
However, these are specialized VMs that need additional control over their own network addressing and traffic reception. Normally, we don’t allow these capabilities in the VMs. In these cases, we might set the default MAC address to something bogus and then give the VF the trust attribute so it can set its own MAC address and enable promiscuous traffic reception:
ip link set p4p1 vf 1 mac 00:DE:AD:BE:EF:01
ip link set dev p4p1 vf 1 trust on
Just Desserts
These are only a few examples of what we can do with our modern NICs. Most or all of these commands are supported by our current 10 Gigabit and 40 Gigabit network server adapters, and more variations are in the works for the future. By putting a few of these simple commands together, we can create large and complex networking structures to support a variety of data center and customer needs.
As the drive for centrally controlled and designed networks grows, the various SDN products will use these technologies to implement the data center’s connections. Packages such as OpenFlow*, Open Daylight*, and many vendor-specific offerings will offer management systems to handle all the heavy work of tracking and managing these connections, but knowing what they are doing will help us all to understand what’s really going on under the table.
Authors
Shannon Nelson is a Networking Software Engineer in the Intel Data Center Group (DCG) Networking Division. In his 28 years at Intel he has worked in scientific computing, factory automation, embedded systems, and networking. He is currently developing and supporting Linux drivers for Intel’s server networking devices.
Anjali S Jain is a Software Engineer working for Linux drivers in DCG’s Network Processing Group. In her 12 year career she has worked on diverse aspects of networking like device driver development, kernel enablement, device performance, HW/FW debugs and SW architecture.
Manasi Deval is Staff Engineer working as the performance lead for Windows drivers in DCG’s Network Processing Group. In her 16 year career she has worked on diverse aspects of networking including device driver development, device performance and architecture.