Cutting-edge 4th generation Intel® Xeon® Scalable processors give Amazon Web Services (AWS)* M7i instances a performance boost and a higher level of cost performance.
In September 2023, MLCommons* unveiled the v3.1 results for its machine learning inference benchmark suite, MLPerf*. These results covered seven distinct use cases:
- Natural language processing (BERT)
- Image classification (ResNet*-50)
- Object detection (RetinaNet)
- Speech-to-text (RNN-T)
- Medical imaging (3D U-Net)
- Recommendation systems (DLRMv2)
- Summarization (GPT-J)
Intel's submission for the 4th gen Intel® Xeon® Scalable processors, equipped with Intel® Advanced Matrix Extensions (Intel® AMX), demonstrated robust performance for general-purpose AI workloads.
This article discusses the impressive inference performance numbers obtained across the MLPerf v3.1 inference workloads running M7i instances with different numbers of vCPUs on cutting-edge 4th gen Intel Xeon Scalable processors. When compared to Amazon EC2* M6i instances using 3rd gen Intel Xeon Scalable processors, M7i instances can process more samples per second at a more cost-effective rate.
Overview of the MLPerf v3.1 Inference Performance Numbers
We collected the inference performance numbers from five of the MLPerf workloads:
- ResNet-50 image classification
- RetinaNet object detection
- BERT natural language processing
- 3D U-Net medical imaging
- RNN-T speech-to-text models
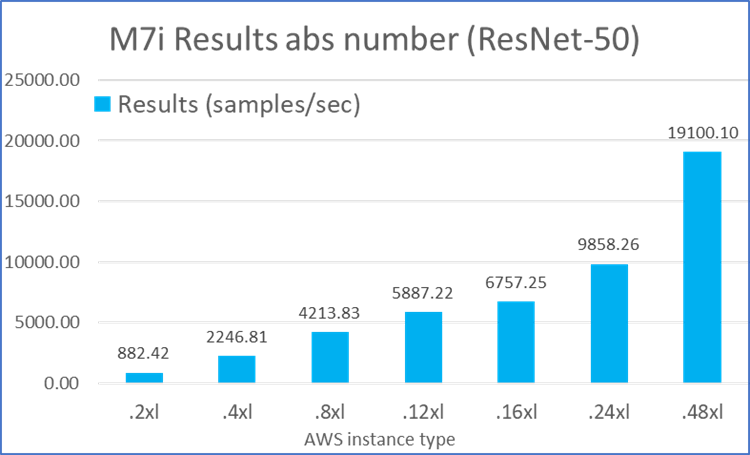
For each workload, we collected performance numbers from different types of EC2 M7i instances, from .2xlarge (with 4 vCPUs) to .48xlarge (with 96 vCPUs). The workload performance number increases with more vCPUs, and .48xlarge instances give the best performance on samples processed per second. For example, as shown in Figure 1, the ResNet-50 model can classify up to 19100.1 samples per second1 on an M7i .48xlarge instance.
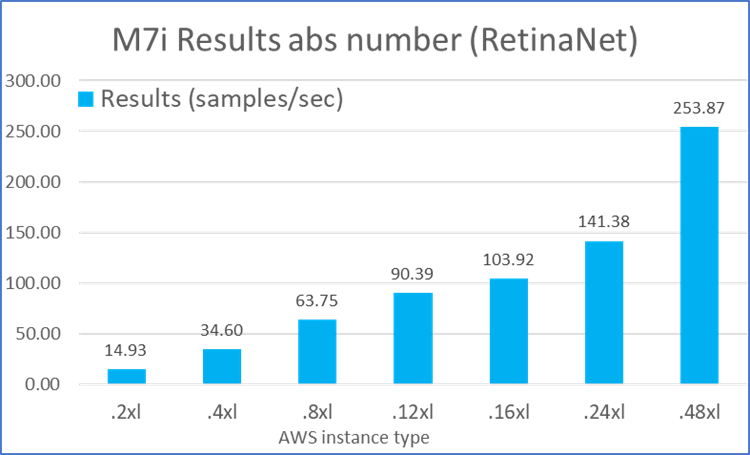
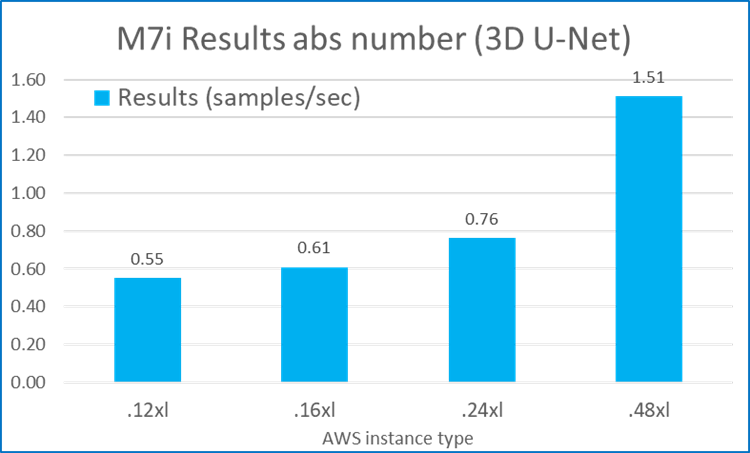
Figures 1 through 5 summarize the performance results of these five MLPerf workloads across different types of EC2 M7i instances:


Gen-to-Gen Comparison between M6i and M7i Instances
EC2 M7i instances are supported by 4th gen Intel Xeon Scalable processors with Intel AMX. Intel AMX is a powerful built-in accelerator that empowers 4th gen Intel Xeon Scalable processors to efficiently manage deep learning training and inferencing workloads, allowing for seamless pivoting between optimizing general computing and AI tasks. Moreover, according to AWS, M7i instances are equipped with DDR5 memory and a 4:1 ratio of memory to vCPU, further boosting M7i instance performance over M6i instances.2
Figure 6 shows that across all the types, M7i instances powered by 4th gen Intel Xeon Scalable processors demonstrated remarkable performance improvements, processing over three times the samples per second compared to M6i instances.
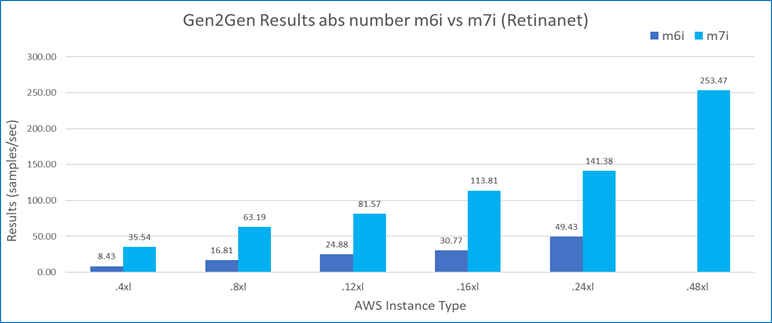
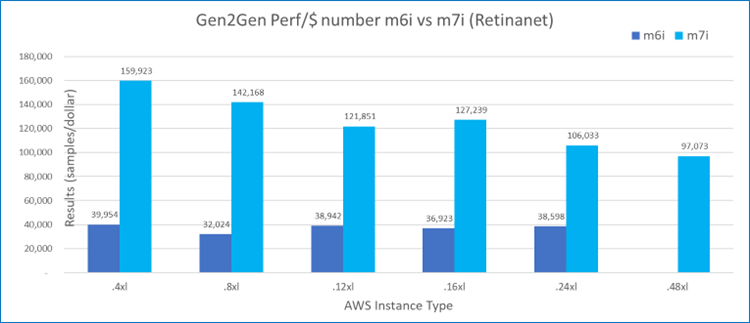
Beyond the higher performance numbers, M7i instances can give even better price performance than M6i instances. As shown in Figure 7, with each dollar spent, M7i instances can achieve over three times higher value of performance compared to M6i instances.
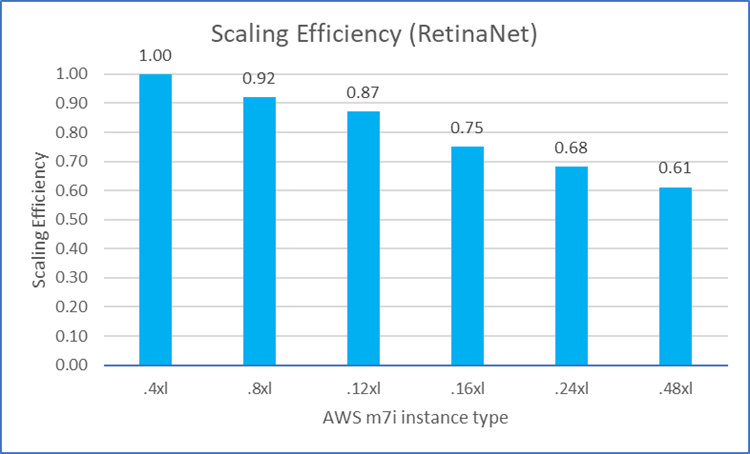
Good Scaling on M7i Instances
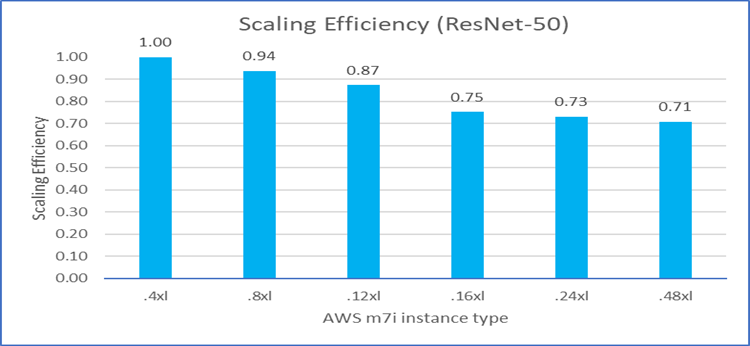
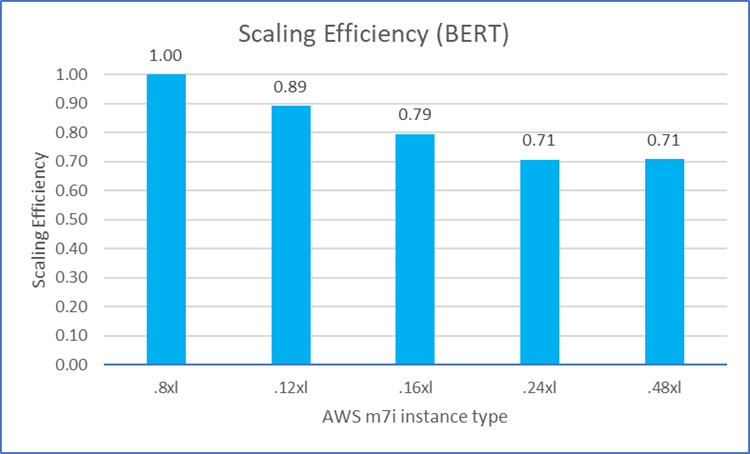
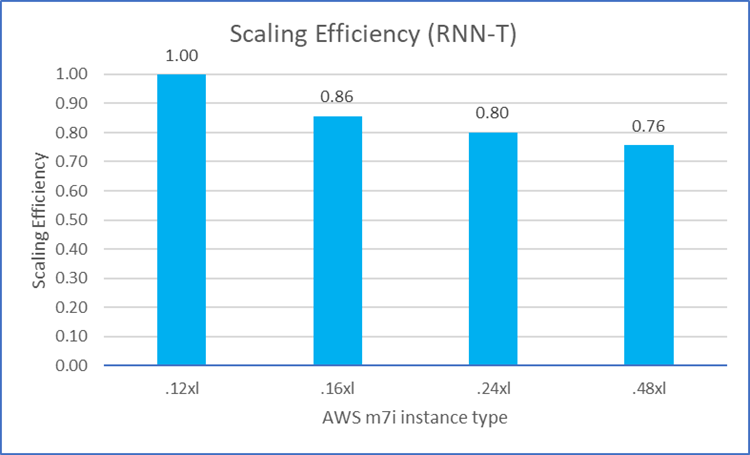
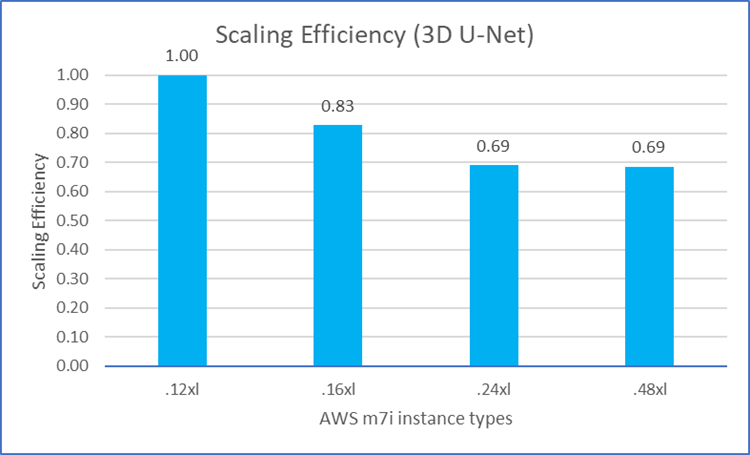
We also examined how the MLPerf workload performance scaled on M7i instances as we increased the number of vCPUs. With ideal scaling efficiency, the relative performance ratio should be 100% (1.0) as the number of processors is increased. As shown in Figures 8 through 12, most of the workloads can achieve good scaling efficiency (over 70%) among M7i instances with different vCPU counts. These figures also show the scaling efficiency of the five MLPerf workloads on M7i instances as the vCPU count is increased. Note Closer to 100% (1.0) is better.
Conclusion
Workflows involving AI, machine learning, and deep learning require significant computational power and time. With high-performance cloud instances, you can significantly reduce processing time and quickly turn data into valuable insights. When compared to the older M6i instances, M7i instances featuring 4th gen Intel Xeon Scalable processors show over 3x better throughput performance and cost performance. You can also expect good scaling and performance speedup when running AI workflows on M7i instances with additional vCPUs.
Additional Resources
To begin running your AI, machine learning, and deep learning workloads on EC2 M7i instances, see Get Started.
To start running Intel MLPerf v3.1 inference workloads, see Get Started with Intel MLPerf Submission.
To learn more about MLPerf inference submissions, see MLPerf Inference: Datacenter Benchmark Suite Results.
References
- Reddi, Vijay Janapa, et al. "MLPerf Inference Benchmark." 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2020.
- EC2 M7i and M7i-flex Instances
Product and Performance Information
Data was collected by Intel on AWS in September 2023. All M7i instances: Intel Xeon Platinum processor 8488C at 2.4 GHz, 4 GB RAM per CPU, BIOS microcode 0x2b000461. All M6i instances: Intel Xeon Platinum processor 8375C at 2.90 GHz, 4 GB RAM per CPU, BIOS microcode 0xd000390. Software configuration: Intel®-optimized Docker* Images for MLperf v3.1 Inference.
Note If you have questions, contact aice.mlperf@intel.com or aice@intel.com.