This is the third article in a series about how memory management works in the Data Plane Development Kit (DPDK). The first article in the series described general concepts that lie at the foundation of DPDK. The second article provided an in-depth overview of input-output virtual address (IOVA) and kernel drivers that also apply to all DPDK versions. This article outlines memory management facilities available in DPDK versions up to and including 17.11.
DPDK 17.11 is (currently) the oldest long-term support (LTS) release that is still supported. Therefore, describing memory management features available in DPDK 17.11 not only provides valuable historical perspective on the evolution of memory management features in DPDK, but also is helpful for a great many DPDK consumers who use these older, but still supported releases.
From a memory management perspective, LTS versions before 18.11 behaved exactly the same, so, unless noted otherwise, anything said about version 17.11 also applies across the board to any earlier version of DPDK as well. Some of the concepts referenced in this article have been covered in Parts 1 and 2 of this series, so be sure to read those too!
Providing Huge Page Memory to DPDK
To provide access to huge page memory for applications, Linux* uses a special hugetlbfs filesystem. Thus, in order to make use of huge pages, DPDK 17.11 has to use hugetlbfs filesystem mountpoints. Since huge pages can come in different sizes, hugetlbfs mountpoints can provide access to different-sized huge pages, depending on how it was configured. If the huge page size for a particular hugetlbfs mountpoint was not explicitly specified, it uses a default huge page size, which is set through the kernel command line (or is set to some default value if no default huge page size was specified at boot time).
On many current distributions, a hugetlbfs mountpoint is available by default through systemd, and in a few cases (such as development or ramp up), having one default mountpoint is enough. The user may also choose to create their own hugetlbfs mountpoints by editing /etc/fstab. Describing how to set up hugetlbfs mountpoints, set default huge page sizes, and reserve huge pages is out of scope for this article series, however relevant guides on how to do that can be found in the DPDK documentation, as well as Linux distributions documentation.
Managing Huge Page Memory with DPDK
Once the system has been set up to reserve huge page memory for application use, DPDK is able to use it. By default, if no memory-related Environment Abstraction Layer (EAL) command-line arguments were specified, a DPDK application takes any huge pages it can have from the system. This is a good default, as it makes it easy to get started with DPDK.
While using all the huge page memory available may be good for development environments and ramp-up scenarios, it may not be suitable for production environments where multiple applications may require huge pages. To solve this problem, it is possible to specify how much huge page memory a DPDK application is allowed to use by using an -m EAL command-line switch:
./app -m 64This EAL parameter limits DPDK’s memory use to 64 megabytes (MB) (rounded up to the smallest available page size). On systems with non-uniform memory access (NUMA) support, supplying this parameter will attempt to spread the requested amount of memory on all available NUMA nodes. For example, given a two-socket system, the above command will reserve 32 MB on NUMA node 0, and 32 MB on NUMA node 1.
However, the memory is not always spread to all NUMA nodes equally; in actuality, amounts of memory assigned to each NUMA node are calculated proportionately to the number of cores on a particular NUMA node in the coremask. Default coremask includes all available cores, and the number of cores on each NUMA node is usually equal, so the memory would be spread equally in the default case. If the coremask instead had six cores on NUMA node 0 and two cores on NUMA node 1, the memory would have been spread differently: 48 MB on NUMA node 0 and 16 MB on NUMA node 1. Similarly, if there were no cores on NUMA node 0 in the coremask, the above command would have allocated all 64 MB on NUMA node 1.
What if more fine-grained control is needed over per-NUMA node allocation? DPDK has another EAL command-line flag dedicated to this use-case—the --socket-mem flag:
./app --socket-mem 0,64Using this flag, it is possible to specify any per-NUMA node memory requirements. If the amount of memory for a particular NUMA node is not specified, the value is assumed to be 0; for example, on a two-socket system, supplying --socket-mem 64 will reserve 64 MB on NUMA node 0, and nothing on NUMA node 1.
How Much Memory to Reserve
Any application using DPDK library version 17.11 or earlier must know its memory requirements in advance. This is because, for these versions of DPDK, there is no possibility to either reserve additional huge page memory after initialization, or to release it back to the system. Therefore, any memory a DPDK application might use must be reserved at application initialization and is held onto by DPDK for the entirety of the application’s lifetime.
It is generally a good idea to leave some headroom when deciding on the amount of memory to reserve. Certain amounts of DPDK memory will be “wasted” on various internal allocations, and these amounts vary depending on your configuration (number of devices DPDK will use, enabled functionality, and so on).
Additionally, most APIs in DPDK 17.11 expect a lot of IOVA-contiguous memory. This is because in DPDK 17.11, the virtual memory layout always matches the physical memory layout. In other words, if the memory area is VA-contiguous, it will also be IOVA-contiguous. This is one of the well-known issues in DPDK 17.11’s memory management: very few things actually require IOVA-contiguous memory, but because there is no way to have VA-contiguous memory without it also being IOVA-contiguous, large memory allocations may fail due to lack of sufficient amounts of IOVA-contiguous memory.
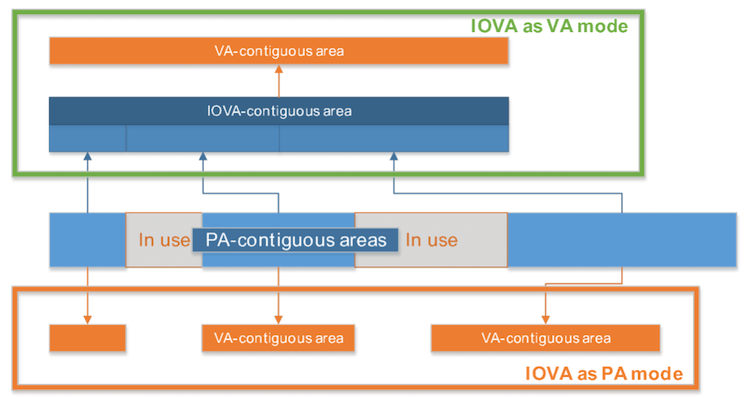
Figure 1. Comparison of IOVA modes
The above limitation is of course only applicable to IOVA as physical addresses (PA) mode, as in that mode, DPDK’s virtual address (VA) space follows the layout of PA space. In IOVA as PA mode, amounts of available IOVA-contiguous memory depend on many factors outside of DPDK’s control, and while DPDK will attempt to reserve as much IOVA-contiguous memory as possible, depending on the amounts of memory available and the system configuration, there may not be enough IOVA-contiguous memory to satisfy all allocations.
In IOVA as VA mode this is not an issue, because in that case, the IOVA space layout will match that of the VA space (rather than the other way around), and all of the physical memory is remapped to appear IOVA-contiguous to the hardware.
Using Huge Page Memory Within DPDK
Once DPDK has started up, there are numerous ways to use the memory provided by DPDK in the user applications. In DPDK, most of the time, available memory will be pinned to a NUMA node. The user then has a choice to either allocate memory on a specific NUMA node (by specifying the NUMA node ID at allocation time as an API parameter), or letting DPDK itself decide where to allocate the memory by using a special value as a NUMA node ID.
For allocating data structures provided by DPDK such as hash tables, memory pools, rings, and so on, the appropriate memory allocation method is used automatically by the API. For example, a call to an rte_ring data structure allocation API calls appropriate memory allocation procedures, so there is no need to explicitly call any memory allocation APIs in cases like these.
For general purpose allocations, DPDK provides its own set of APIs that are mirroring glibc malloc() functions. There are also NUMA-aware versions of these APIs. These APIs should feel very familiar to a C programmer, and all of the benefits of using DPDK’s memory management—explicit NUMA node locality, fewer translation lookaside buffer (TLB) misses, alignment, and so on—will apply to any memory allocated using these APIs.
In addition to that, DPDK also provides the rte_memzone family of APIs, which allow allocating raw memory zones that satisfy requirements of size, alignment, and boundaries, as well as NUMA node and page size. Memory zones must also have unique names, as they can be looked up by their name. These APIs are mainly used internally by data structures, drivers, and such, and are not typically used in application code.
Table 1. Decision chart for allocation APIs
| Use Case | API |
|---|---|
| Raw memory areas | rte_memzone |
| General purpose allocations | rte_malloc |
| DPDK data structures | Respective data structure allocation API if present, otherwise rte_malloc |
In DPDK 17.11 and earlier, all DPDK memory allocations, regardless of how they are performed, are both VA- and IOVA-contiguous. All memory allocation APIs are also thread-safe, and since the memory is also shared between all primary and secondary processes, passing pointers between processes, as well as allocating or freeing memory in different processes, is perfectly safe.
Other Memory-Related Features
In addition to the above, EAL also provides some specialized functionality that is not useful in a general case, but can come in handy in certain scenarios.
Running DPDK Without Huge Page Support
One of the features EAL provides is a no-huge mode, available by specifying the --no-huge EAL command-line flag. This makes it so that DPDK does not require (or use) huge page memory to initialize, and instead uses regular memory. This is usually useful for debugging purposes only (such as running some unit tests), as packet IO will not work unless IOVA as VA mode is used. The --socket-mem switch is invalid in this mode, but the -m switch still specifies how much memory DPDK should reserve at startup.
Setting Custom Huge Page Filesystem Mountpoint
Another feature available in EAL is setting a custom hugetlbfs mountpoint with the --huge-dir command-line parameter. If the user has multiple mountpoints for hugetlbfs of the same page size, the results can be unpredictable, as this is not an expected environment for DPDK to operate in. Specifying a particular mountpoint for DPDK to use resolves that issue, although only one such mountpoint can be used at a time.
Removing Huge Pages from the Filesystem
Finally, the most useful option is --huge-unlink. By default, whenever DPDK initializes, it creates and stores all huge page files in hugetlbfs mountpoints and will not remove them at exit. Thus, when a DPDK application exits, those huge pages are still used as far as the kernel is concerned (even though the DPDK has already shut down), and in order to free them back to the system, these files need to be removed from the filesystem. This behavior is intentional, as it allows secondary DPDK processes to initialize and attach to the memory (and continue working normally), even if the primary process has exited.
The --huge-unlink option makes it so that, at initialization time, the huge page files in hugetlbfs mountpoints are created, mapped, and then immediately removed. DPDK will keep holding on to the allocated huge pages, but there will be no more files left behind in the hugetlbfs filesystem, so there is nothing to clean up after DPDK application exit. It goes without saying that this option sacrifices secondary process support (because there is no shared memory that can be discovered at initialization), but for many DPDK use cases, this tradeoff is acceptable.
Conclusion
This article provides an overview of memory management features available in DPDK version 17.11 and earlier, as well as outlining the various options available to make the most out of DPDK for a particular use case.
This is the third article in the series of articles about memory management in DPDK. The first article has outlined key principles that lie at the foundation of DPDK’s memory management subsystem. The second article has provided an in-depth overview of how DPDK handles physical addressing. The next, and final article in the series will outline the new memory management features that are available in DPDK version 18.11 or later.
Helpful Links
DPDK documentation for release 17.11
DPDK documentation for previous releases
DPDK API documentation for release 17.11
EAL section of the Programmer’s Guide for DPDK release 17.11
About the Author
Anatoly Burakov is a software engineer at Intel. He is the current maintainer of VFIO and memory subsystems in DPDK.