Introduction
Transformer models have revolutionized natural language processing with their ability to capture complex semantic and syntactic relationships. However, these models also pose significant challenges for efficient inference, especially for large language models (LLMs) that have billions of parameters. For example, running half-precision inference of Megatron-Turing 530B would require 40 A100-40 GB GPUs.1 To address challenges associated with the inference of large-scale transformer models, the DeepSpeed* team at Microsoft* developed DeepSpeed Inference.2 It provides high-performance multi-GPU inferencing capabilities and introduces several features to efficiently serve transformer-based PyTorch* models using GPU. We are very excited to share that DeepSpeed Inference has been implemented for the 4th generation Intel® Xeon® Scalable processor.
4th Gen Intel Xeon Scalable Processor
Intel launched this processor in January 2023 with built-in accelerators for AI, data analytics, networking, storage, and HPC. Tile Matrix Multiplication (TMUL) is the built-in AI accelerator. It runs the Intel® Advanced Matrix Extensions (Intel® AMX), which can significantly speed up deep learning applications, both in inference and training. Other notable new features that can speed up deep learning applications include PCI Express* Gen5 (PCIe* 5.0) and DDR5. PCIe 5.0 doubles the I/O bandwidth from PCIe 4.0, increasing the bandwidth between CPU and connected devices. DDR5 offers up to 1.5x bandwidth increase over DDR4.3
The 4th generation Intel Xeon Scalable processor with Intel AMX sped up training of the BERT large model by 4x compared to 3rd generation Intel Xeon Scalable processors.4 TMUL runs Intel AMX instructions on data loaded in 2D registers, hence the name tiles. These instructions operate on 8-bit integer (int8) or 16-bit bfloat (bfloat16) datatype. The 4th generation Intel Xeon Scalable processor with Intel AMX can attain 2048 int8 operations per cycle compared to 256 int8 operations per cycle in 3rd generation Intel Xeon Scalable processors with Intel® Advanced Vector Extensions 512 (Intel® AVX-512) Vector Neural Network Instructions (VNNI). Its bfloat16 performance is 1024 operations per cycle compared to its 32-bit floating point (FP32) performance of 64 operations per cycle. Therefore, Intel AMX can significantly speed up deep learning applications when int8 or bfloat16 datatype is used for matrix multiplication or convolution computations, the common operations in transformer or convolution-based models.
DeepSpeed Enabled
DeepSpeed is a deep learning optimization software for scaling and speeding up deep learning training and inference. DeepSpeed Inference refers to the feature set in DeepSpeed that is implemented to speed up inference of transformer models.2 It initially supported only CUDA* GPUs. We recently added support for CPUs, specifically 4th generation Intel Xeon Scalable processors. Features currently implemented include automatic tensor parallelism (AutoTP), bfloat16 and int8 datatype support, and binding cores to rank.
DeepSpeed builds on top of PyTorch, which has been highly optimized for CPU inference and training. Intel® Extension for PyTorch* adds state-of-the-art optimizations for popular LLM architectures, including highly efficient matrix multiplication kernels to speed up linear layers and customized operators to reduce the memory footprint.5 The runtime software components for DeepSpeed Inference on CPU are shown in Figure 1. Intel® oneAPI Deep Neural Network Library (oneDNN) uses Intel AVX-512 VNNI and Intel AMX optimizations.6 Intel® oneAPI Collective Communications Library (oneCCL) is a library that implements the communication patterns in deep learning.7 Intel® Neural Compressor was used to convert the LLMs from FP32 datatype to bfloat16 or int8 datatype.8
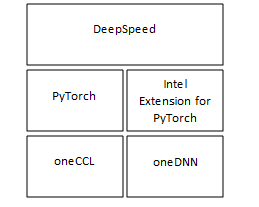
Technologies Introduced
To accelerate running LLMs with DeepSpeed on 4th generation Intel Xeon Scalable processors, we introduced technologies into both DeepSpeed and Intel Extension for PyTorch.
- Extend DeepSpeed Accelerator Abstraction Interface to provide CPU support.9 We implemented the CPU as a DeepSpeed accelerator, which allows CPU support to be plugged into DeepSpeed in a device-agnostic manner. Device-agnostic DeepSpeed model scripts, which use DeepSpeed Accelerator Abstraction Interface, can run on CPU devices without modification.
- Fine grain core binding. We introduced two new DeepSpeed command line arguments: --bind_cores_to_rank and --bind_core_list to allow core binding with DeepSpeed AutoTP10 on a node with multiple sockets or on a single socket with multiple sub-NUMA nodes (SNC). Using numactl for each tensor parallel worker, we can bind workers to cores and NUMA memory. This reduces interference between workers and uses memory bandwidth and core more effectively.
- Optimized shared memory (SHM) based on AllReduce communication primitives for a single CPU node. We implemented a low latency SHM-based AllReduce primitive which utilizes the shared memory of a single node CPU system.
- Optimizations in Intel Extension for PyTorch include:
- oneDNN, Tensor Processing Primitives (TPP), and customized linear kernels for weight only quantization
- Indirect Access KV Cache reduces memory reorder overhead when using a KV cache
- Subgraph fusion to reduce memory footprint
- Fusion of AllReduce between multihead attention and multilayer perceptron in transformer layer when there is no dependency between them
How to Run DeepSpeed on a CPU
The following software is required for DeepSpeed Inference on a CPU (specific details are in the configuration):
- PyTorch
- Intel Extension for PyTorch6
- oneCCL binding for PyTorch11
- oneCCL7
- DeepSpeed12
After installing the required software, we can run inference for a model on the CPU. Device agnostic-interfaces are used to load and run the model. These device agnostic interfaces are accessed through deepspeed.accelerator.get_accelerator() as shown in Listing 1. For further details, refer to the DeepSpeed tutorial on DeepSpeed accelerator interfaces.13
# Listing 1. An example of using device agnostic interface to get the accelerator device and load and run a model.
import deepspeed
from deepspeed.accelerator import get_accelerator
...
# load model checkpoint into model
model = model.eval().to(get_accelerator().device_name())
ds_world_size = int(os.getenv('WORLD_SIZE', '0'))
engine = deepspeed.init_inference(model=model, mp_size=ds_world_size, \
dtype=torch.bfloat16, replace_method="auto", \
replace_with_kernel_inject=False)
model = engine.module
...
# evaluate model
Run the inference code with DeepSpeed using the following command:
deepspeed --bind_cores_to_rank <python script>
This command detects the number of sockets on the host and launches as many inference workers as the number of sockets. The LLM workload runs in parallel on the inference workers with DeepSpeed AutoTP.10 AutoTP distributes inference computation among workers and reduces inference latency. For example, if the host has two sockets, this command will launch two inference workers to inference the input sample in parallel. The argument --bind_cores_to_rank instructs DeepSpeed to split the CPU cores and distribute them to each rank evenly. This ensures that each inference worker uses an exclusive set of CPU cores to avoid interfering with one another. If this argument is not specified, it will defer to the operating system to schedule the workers to the CPU cores, which may not be optimal.
Intel Extension for PyTorch is compatible with DeepSpeed AutoTP and can therefore be used to further optimize AutoTP models generated by DeepSpeed.
# Use Intel Extension for PyTorch to optimize model
...
model = engine.module
import intel_extension_for_pytorch as ipex
model = ipex.optimize_transformers(model.eval(), dtype=torch.bfloat16, inplace=True)
...
Examples of LLM optimizations for DeepSpeed AutoTP models with Intel Extension for PyTorch are available at Intel Extension for PyTorch large language model example.14
Results
DeepSpeed enables optimal distribution of LLM inference on two 4th generation Intel Xeon Scalable processor sockets. Intel AMX on 4th generation Intel Xeon Scalable processors can be used to accelerate bfloat16 matrix multiplication operations. Support for Intel AMX is available through Intel Extension for PyTorch. Performance speedups in GPT-J-6B and LLaMA2-13B from DeepSpeed AutoTP on two sockets are shown in Figure 2. GPT-J-6B has six billion parameters, requiring 12 GB of memory for its weights. Llama-2-13B has 13 billion parameters, requiring 26 GB of memory for the weights. Latency improvement is the metric used. Prompt latency and per token latency improved as shown by the speedups in the plot.
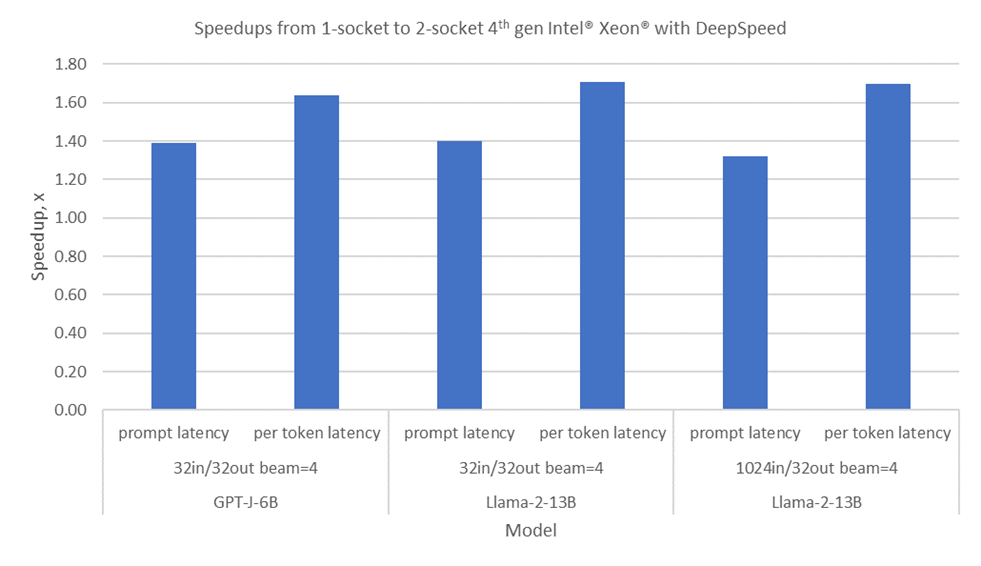
Summary
DeepSpeed Inference has been enabled for 4th generation Intel Xeon Scalable processors with Intel AMX to accelerate matrix multiplications common in deep learning workloads. DeepSpeed Inference uses 4th generation Intel Xeon Scalable processors to speed up the inferences of GPT-J-6B and Llama-2-13B. We will continue to improve it for new devices and new LLMs. Intel® Data Center GPU Max Series is a new GPU designed for AI for which DeepSpeed will also be enabled.15
Contributors
This work was made possible through deep collaboration between software engineers and researchers at Intel and Microsoft.
Intel Contributors:
- Guokai Ma
- Kiefer Kuah
- Yejing Lai
- Liangang Zhang
- Xiaofei Feng
- Xu Deng
- Mengfei Li
- Jianan Gu
- Haihao Shen
- Fan Zhao
Microsoft Contributors:
- Olatunji Ruwase
- Martin Cai
- Yuxiong He
References
- Microsoft, "ZeRO-Inference: Democratizing massive model inference," September 9, 2022, accessed April 12, 2023, https://www.deepspeed.ai/2022/09/09/zero-inference.html.
- "DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale," June 30, 2022. https://arxiv.org/abs/2207.00032.
- Intel, "4th Gen Intel® Xeon® Scalable Processors," accessed April 4, 2023, https://www.intel.com/content/www/us/en/products/docs/processors/xeon-accelerated/4th-gen-xeon-scalable-processors-product-brief.html.
- Intel, "Accelerate AI Workloads with Intel AMX," accessed April 12, 2023, https://www.intel.com/content/www/us/en/products/docs/accelerator-engines/advanced-matrix-extensions/ai-solution-brief.html.
- Intel, "Large Language Models (LLM) Optimizations Overview," https://intel.github.io/intel-extension-for-pytorch/cpu/2.1.0+cpu/tutorials/llm.html.
- Intel, "Intel® Extension for PyTorch*," https://github.com/intel/intel-extension-for-pytorch.
- Intel, "oneAPI Collective Communications Library (oneCCL)," https://github.com/oneapi-src/oneCCL.
- Intel, "Intel Neural Compressor," https://github.com/intel/neural-compressor.
- Microsoft, "DeepSpeed Accelerator Abstraction Interface," https://github.com/microsoft/DeepSpeed/blob/master/docs/_tutorials/accelerator-abstraction-interface.md.
- Microsoft, "Automatic Tensor Parallelism for HuggingFace Models," https://www.deepspeed.ai/tutorials/automatic-tensor-parallelism.
- Intel, "oneCCL Bindings for PyTorch," https://github.com/intel/torch-ccl.
- Microsoft, "DeepSpeed," https://github.com/microsoft/deepspeed.
- Intel, "DeepSpeed Accelerator Abstraction Interface," https://github.com/microsoft/DeepSpeed/pull/3184.
- Intel, "Intel Extension for PyTorch Large Language Model," https://github.com/intel/intel-extension-for-pytorch/tree/llm_feature_branch/examples/cpu/inference/python/llm.
- Intel, "Intel® Data Center GPU Max Series," https://www.intel.com/content/www/us/en/products/details/discrete-gpus/data-center-gpu/max-series.html.
Product and Performance Information
1-node, 2x Intel® Xeon® Platinum 8480+ processor, 56 cores, hyperthreading on, turbo on, 1024 GB (16x64 GB DDR5 4800 MT/s [4800 MT/s]), BIOS version Intel Corporation SE5C7411.86B.9525.D13.2302071333, 02/07/2023, ucode version 0x2b000190, Red Hat* Enterprise Linux* 8.6, kernel version 4.18.0-372.9.1.el8.x86_64, GCC 11.2.1, PyTorch 2.1.0.dev20230618+cpu, DeepSpeed 0.9.5+3f5e4931, Intel Extension for PyTorch 2.1.0+git31b7cd6, GPT-J-6B, LLaMA-2-13B
Tested by Intel, June 2023.