In this article, we first review the performance challenges encountered in Ceph* 4K I/O workloads and give a brief analysis of the CPU distribution for a single Ceph OSD object storage daemon (OSD) process. We then discuss inefficiencies in the existing TCP/IP stack and introduce the iWARP RDMA protocol supported by Intel® Ethernet Connection X722, followed by a description of the design and implementation for iWARP RDMA integration into Ceph. Finally, we provide a performance evaluation of Ceph with iWARP RDMA, which demonstrates up to 17 percent performance improvement compared with the TCP/IP stack6.
Background
Red Hat Ceph*, one of today’s most popular distributed storage systems, provides scalable and reliable object, block, and file storage services in a single platform 1. It is widely adopted in both cloud and big data environments, and over the last several years, Ceph RADOS block device (RDB) has become the dominant OpenStack* Cinder driver. Meanwhile, with the emergence of new hardware technologies like Intel® 3D XPoint™ memory2 and remote direct memory access (RDMA) network interface cards (NICs), enterprise application developers have developed new expectations for high-performance and ultra-low latency storage solutions for online transaction processing (OLTP) workloads on the cloud.
Ceph has made steady progress on improving networking messenger since the Ceph Jewel* release. The default simple messenger has been changed to async messenger to be more CPU efficient and compatible with different network protocols, such as TCP/IP and RDMA. The Ceph community designed and implemented a new solid-state drive (SSD)-friendly object storage backend called BlueStore*, and leveraged additional state-of-the-art software technology such as Data Plane Development Kit (DPDK) and Storage Performance Development Kit (SPDK). These software stack changes made it possible to further improve the Ceph-based storage solution performance.
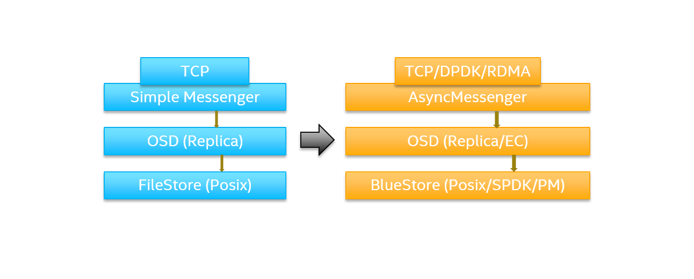
Figure 1. Software evololution in the Ceph* system
Intel® Optane™ SSD, used for Red Hat Ceph BlueStore metadata and WAL drives, fill the gap between DRAM and NAND-based SSD, providing unrivaled performance even at low queue depth workloads. Intel® Xeon® Scalable processors, offering a range of performance, scalability and feature options to meet a wide variety of workloads, are ideal for Red Hat Ceph data-intensive solutions. RDMA enables direct, zero-copy data transfer between RDMA-capable server adapters and application memory, removing the need in Ethernet networks for data to be copied multiple times to operating system data buffers. This is highly efficient and eliminates the associated processor-intensive context switching between kernel space and user space. The Intel Xeon Scalable processor platform includes integrated Intel® Ethernet Connection X722 with Internet Wide-area RDMA Protocol (iWARP), and provides up to four 10-gigabit Ethernet (GbE) ports for high data throughput and low-latency workloads, which makes the platform an ideal choice for scale-out storage solutions.
Motivation
The performance challenges
At the 2017 Boston OpenStack Summit3, Intel presented an Intel Optane SSD and Intel® SSD Data Center P4500 Series based Ceph all-flash array cluster that delivered multimillion input/output operations per second (IOPS) with extremely low latency and competitive dollar per gigabyte costs. We also showed the significant networking overhead imposed by network messenger. As shown in Figure 2, the CPU tended to be the bottleneck in a 4K random read workload. Analysis showed that 22–24 percent of the CPU was used to handle network traffic, highlighting the need to optimize the Ceph networking component for ultra-low latency and low CPU overhead. Traditional TCP/IP cannot satisfy this requirement, but RDMA can 4.
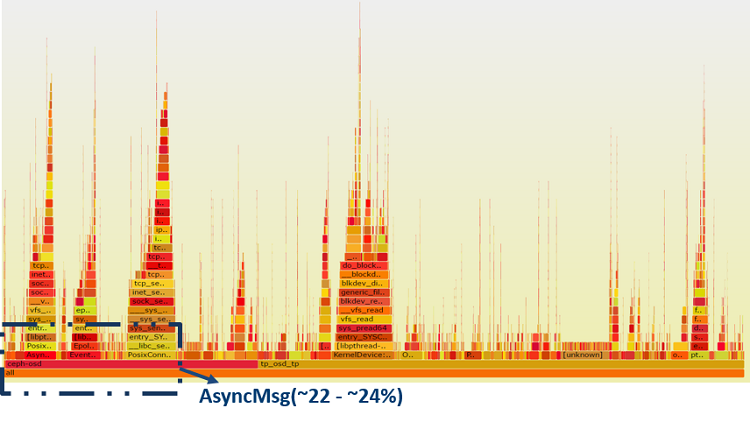
Figure 2. Networking component bottleneck in the Ceph* system.
RDMA versus traditional TCP/IP protocol
Today there are three RDMA options: InfiniBand* requires deploying a separate infrastructure in addition to the requisite Ethernet network, iWARP 5, and RoCE (RDMA over Converged Ethernet) are computer networking protocols that implement RDMA for efficient data transfer over Internet protocol networks.
Previous studies have shown that traditional TCP/IP has two outstanding issues: high CPU overhead for handling packets in the operating system kernel and high message transfer round-trip latency, even when the average traffic load is moderate. RDMA performs direct memory access from one computer to another without involving the destination computer’s operating system, and has the following advantages over TCP/IP:
- Avoids memory copies on both sender and receiver, providing the application with the smallest round trip latency and lowest CPU overhead.
- The data moves from the network into an area of application memory in the destination computer without involving its operating system and the network input/output (I/O) stack.
- RDMA protocol transfers data as messages, while TCP sockets transfer data as a stream of bytes. RDMA avoids the header used in the TCP stream that consumes additional network bandwidth and processing.
- RDMA protocol is naturally asynchronous; no blocking is required during a message transfer.
Therefore, we expect lower CPU overhead and lower network message latency when integrating RDMA into the Ceph network component.
Integrating iWARP into the Ceph* System
This section describes the evolution of RDMA design and implementation in Ceph. We will discuss the general architecture of Ceph RDMA messenger, and then share how we enabled iWARP in the current Ceph async messenger.
Ceph RDMA messenger
The Ceph system relies on messenger for communications. Currently, the Ceph system supports simple, async, and XIO messengers. From the view of the messenger, all of the Ceph services such as OSD, monitor, and metadata server (MDS), can be treated as a message dispatcher or consumer. Messenger layers play the role of bridge between Ceph services and bottom-layer network hardware.
There are several other projects that focus on integrating RDMA into the Ceph system—XIO* messenger is one of them. XIO messenger is built on top of an Accelio* project that is a high-performance asynchronous reliable messaging and remote procedure call (RPC) library optimized for hardware acceleration. It was merged into the Ceph master in 2015, and supports different network protocols, such as RDMA and TCP/IP. XIO messenger seamlessly supports RDMA*, including InfiniBand*, RoCE* and iWARP*. In this implementation, RDMA is treated as a network component, like simple messenger or async messenger in the Ceph system. According to feedback from the Ceph community 7, there are some scalability issues and stability issues; currently this project is not actively maintained.
Another project is aimed at integrating InfiniBand RDMA into async messenger. Async messenger is the default networking component starting with the Ceph Jewel release. Compared to simple messenger, the default networking component before Ceph Jewel, async messenger is more CPU-efficient and spares more CPU resources. It is an asynchronous networking library designed for the Ceph system and is compatible with different network protocols such as Posix, InfiniBand RDMA, and DPDK. Figure 3 shows the architecture of Ceph async messenger with InfiniBand protocol; RoCE support is similar.
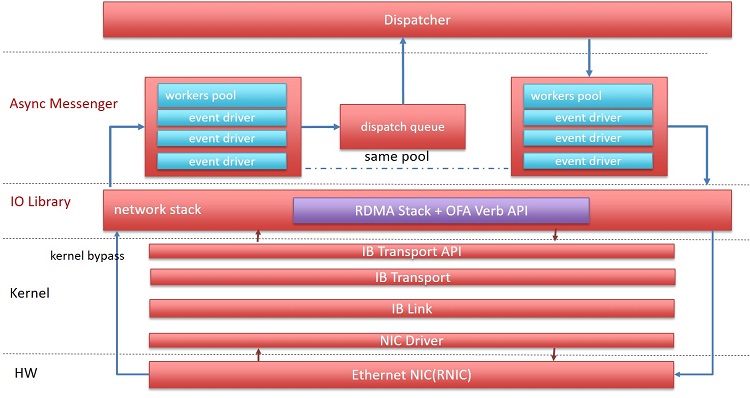
Figure 3. InfiniBand integration with Ceph* async messenger
iWARP integration with async messenger
With the rapid growth of message transfer between Internet applications, high-performance (high-speed, high-throughput, and low-latency) networking is needed to connect servers in data centers, where Intel Ethernet is still the dominant network physical layer, and the TCP/IP stack is widely used for network services. Previously, we came to the conclusion that the TCP/IP stack cannot meet the demands of the new generation of data center workloads. Ceph with iWARP RDMA is a practical way for data centers running Ceph over TCP/IP to move to RDMA, leveraging Intel® Ethernet with iWARP RDMA to accelerate the Ceph system.
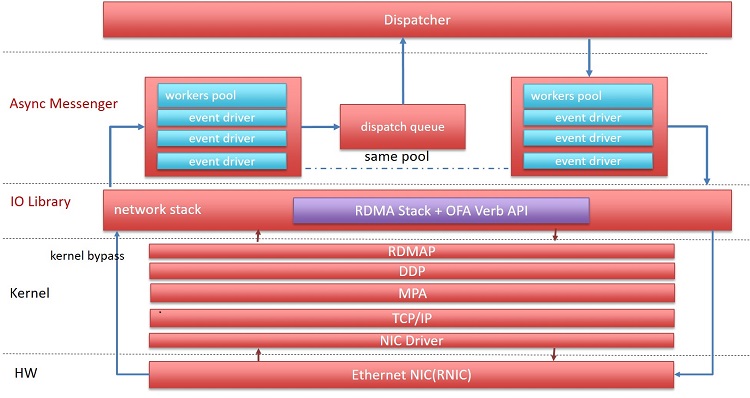
Figure 4. iWARP integrated in async messenger
Thanks to the extensible framework of async messenger, we can modify RDMA connection management to use the RDMA connection management (RDMA-CM) library to support iWARP, instead of the current InfiniBand RDMA implementation,which uses self-implemented TCP/IP-based RDMA connection management. We implement the RDMA connection interface with the librdmacm library so it is compatible with other implementations including InfiniBand and RoCE. Choosing iWARP or InfiniBand as the RDMA protocol is configurable. In addition, we support creating queue pairs that are not associated with a shared receive queue. The memory requested by the receive queue is allocated from a centralized memory pool. The memory pool is reserved and released when starting and ending async messenger service.
Performance Tests
In this section, we present the performance evaluation of Ceph with iWARP RDMA.
Testing methodology
The performance evaluation was conducted on a cluster with two OSD nodes and two client nodes. The detailed configurations were as follows:
- Hardware configuration: Each of the four nodes was configured with an Intel Xeon Platinum 8180 processor and 128 GB memory, with integrated 10-Gigabit Intel Ethernet Connection X722 with iWARP RDMA. Each of the OSD nodes had 4x Intel SSD Data Center P3520 Series 2TB SSDs as storage devices.
- Ceph system and FIO* configuration: The OSD servers ran Ubuntu* 17.10 with the Ceph Luminous* release. Each OSD drive on each server node hosted one OSD process as BlueStore* data and DB drive, totaling 8x OSD processes running in the test. The RBD pool used for testing was configured with two replications. The FIO version was 2.12.
- Network configuration: The network module between OSD nodes and client nodes was user defined. In this test, we changed the network module from TCP/IP to RDMA. The networking topology is described in Figure 5. For Ceph with RDMA testing, the public network and cluster network shared one NIC.
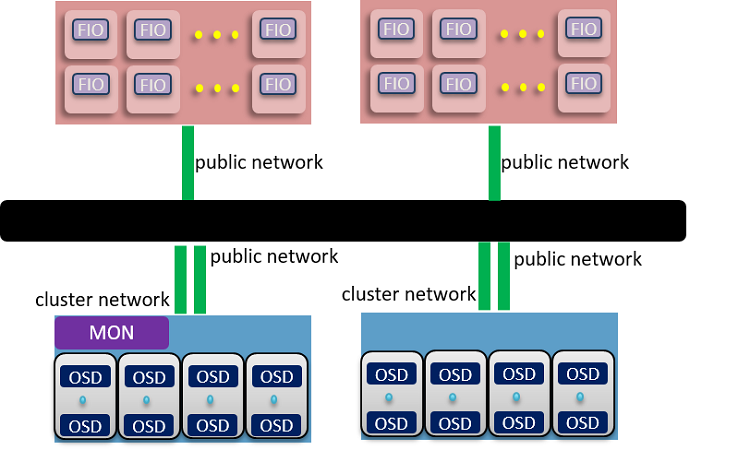
Figure 5. Ceph* benchmarking topology—two nodes
We simulated typical workloads on an all-flash Ceph cluster in the cloud with FIO 4K random write running on Ceph RBD volumes. For each test case, IOPS was measured at different levels of queue depth scaling (1 to 32). Each volume was configured to be 30 GB. The volumes were pre-allocated to eliminate the Ceph thin-provision mechanism’s impact on stable and reproducible results. The OSD page cache was dropped before each run to eliminate page cache impact. For each test case, FIO was configured with a 300-second warm up and 300-second data collection.
Ceph system performance comparison with TCP and with iWARP RDMA
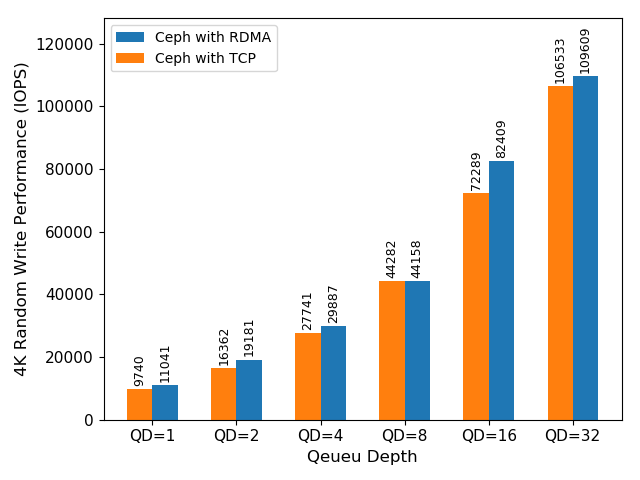
(a) FIO performance comparison
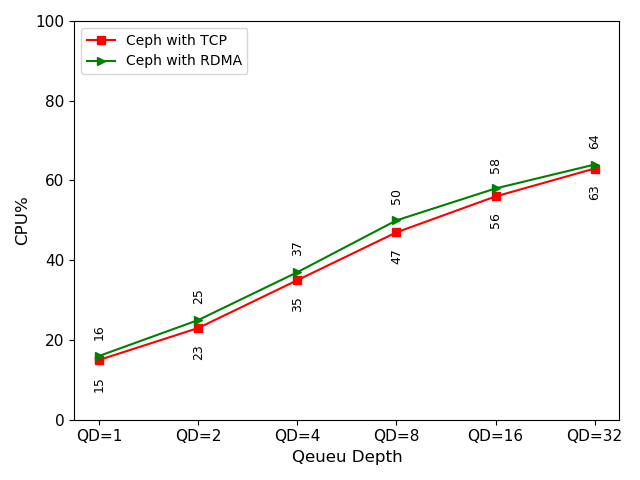
(b) CPU comparison on OSD node
Figure 6. Ceph* system performance comparison with RDMA or TCP/IP
Figure 6 (a) illustrates aggregated FIO IOPS on client nodes using different network protocols. It shows that Ceph with RDMA delivered higher performance in a 4K random write workload than TCP/IP—up to a 17 percent performance improvement with queue depth = 2. Increasing FIO queue depth also impacted RDMA results. The RDMA benefit was more obvious in a low queue depth workload, depending on Ceph tunings, such as completed queue depth in Ceph RDMA messenger.
Figure 6 (b) shows CPU utilization on an OSD node when running an FIO process on an RBD volume. The CPU utilization of Ceph with RDMA was higher than with TCP/IP, which was not our expectation (detailed root cause will be illustrated later). Theoretically, RDMA should reduce CPU utilization since RDMA bypasses the kernel and limits context switching.
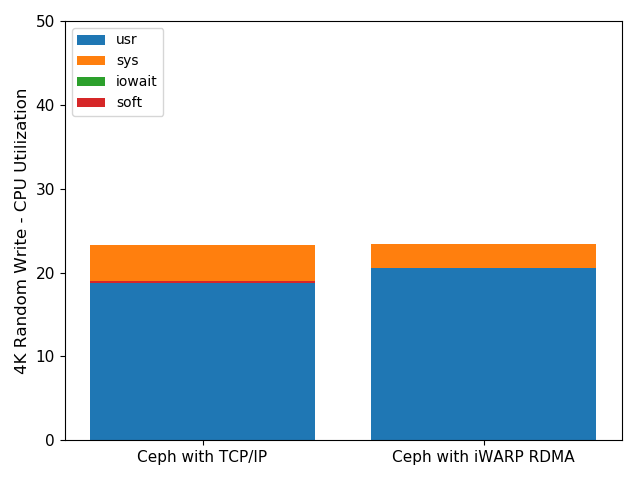
Figure 7. CPU profiling on OSD node
As shown in Figure 7, Ceph with TCP/IP consumed more system-level CPU, and Ceph with iWARP RDMA consumed more user-level CPU. That makes sense at first glance, because RDMA achieves kernel bypass, so RDMA consumes less system-level CPU. However, it does not make sense that RDMA consumed more user-level CPU. The root cause for this will be explained later. Even Ceph with iWARP consumed more CPU, and the FIO IOPS per CPU cycles on the OSD node was higher compared to TCP/IP. Overall, Ceph with iWARP provided higher 4K random-write performance and was more CPU efficient than Ceph with TCP/IP.
Scalability tests
To verify the scalability of Ceph with iWARP RDMA, we scaled up the number of OSD nodes and client nodes to three, keeping the other Ceph configuration and benchmarking methodologies the same as previous tests.
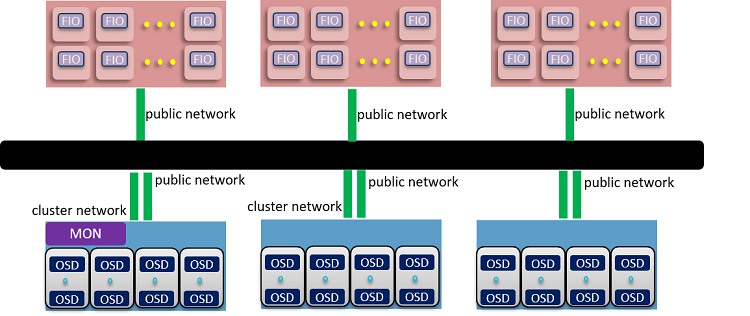
Figure 8. Ceph* benchmarking topology—scale up to three nodes
With one more OSD node, the performance of Ceph with iWARP increased by 48.7 percent and the performance of Ceph with TCP/IP increased by 50 percent. Both of them showed greater node scalability. Not surprisingly, Ceph with iWARP RDMA showed higher 4K random write on the three OSD nodes cluster.
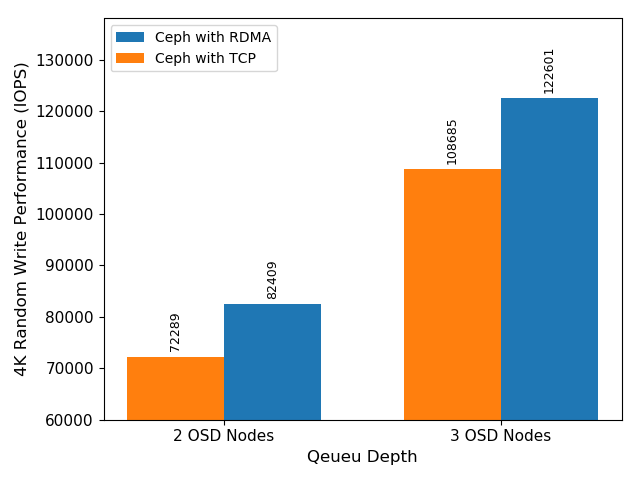
Figure 9. Ceph* benchmarking topology—scale up to three nodes
Performance Analysis
To better understand the overhead inside Ceph async messenger with iWARP RDMA, we looked at the message receiving flow.
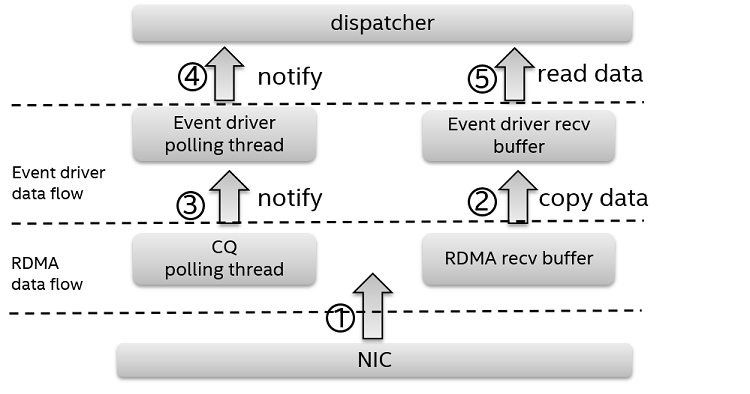
Figure 10. Data receiving flow in async messenger with RDMA
To give a clearer description of the flow, we simplify the message transfer process, which follows this precondition: It is a single server and client architecture; the client has already established an RDMA connection with the server, and the server sends a 4K message to the client.
- Once the network driver on the client side gets the remote send request it triggers the CQ polling event. The event takes over the back-end worker thread and handles the CQ polling event. The CQ polling event fetches the 4K remote DMA message and puts it into the async messenger recv buffer, followed by another request to trigger an async messenger read event. After that, the polling event releases the back-end threads.
- The read event reads the 4K message from the specified recv buffer and then transfers it to the responding dispatcher to handle. Finally, the read event releases the work thread and completes the read process.
The RDMA message transfer process is based on Ceph async messenger. For one message receiving flow, two events are triggered and one message copied. We go deeper and use a perf flame graph to get the details of CPU usage for one async messenger worker.
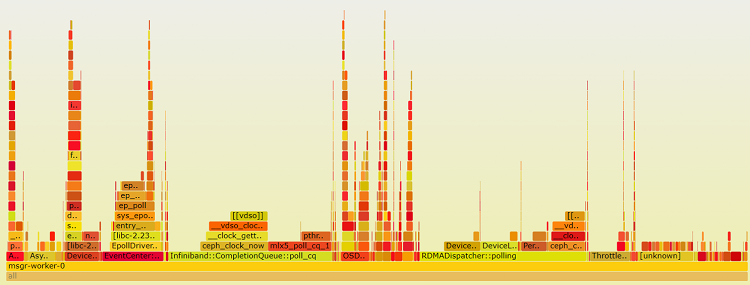
Figure 11. CPU usage of Ceph* async messenger worker
Figure 11 shows that most of the CPU used by a worker is consumed by the RDMA polling thread and async messenger polling process. As described in the message transfer flow, adding RDMA polling over async messenger increases the CPU overhead and context switch because it doubles the polling process, and two events are triggered for one message transfer. Meanwhile, an additional message copy from the RDMA received buffer to the async messenger unread buffer adds message transfer roundtrip latency. The two polling threads and additional memory copy issue lead to higher user-level CPU consumption for Ceph with iWARP RDMA.
Next Steps
Performance optimization
Adapting RDMA polling to an I/O multiplexing framework such as async messenger is not an optimal solution. RDMA concentrates on avoiding CPU overhead in the kernel level. Signaling a descriptor in async messenger introduces an extra context switch, which increases CPU overhead. Meanwhile, we have proposed an RDMA messenger library, and integrated it with a distributed cache storage project, Hyper-converged Distributed Cache Storage (HDCS) 8. The initial benchmark shows great performance benefit (I/O and CPU consumption) with RDMA networking, compared to TCP/IP.
Based on past experience, we will continue to make performance optimizations to the Ceph RDMA code, including separating RDMA polling from the async messenger event driver, and avoiding memory copy to the async messenger recv buffer. Because RDMA protocol provides message-based rather than stream-based transactions, we do not need to separate the stream into different message/transactions on the message sender side and piece them together on the receiver side. Messenger-based transactions make it possible to avoid extra memory copy operations for buffering the data.
Disaggregate Ceph storage node and OSD node with NVMe-oF
For two issues, we consider leveraging non-volatile memory express over Fabrics (NVMe-oF) to disaggregate the Ceph storage node and the OSD node. First, current Ceph system configuration cannot fully benefit from NVMe drive performance; the journal drive tends to be the bottleneck. Second, for the one OSD process per one NVMe drive configuration, 40 percent of the Intel Xeon processor is not utilized on the OSD node. By disaggregating the Ceph storage and OSD nodes, we can use all NVMe devices on the target node as an NVMe pool and dynamically allocate an appropriate NVMe drive for the specified OSD node.
We have initial performance data6 to show that NVMe-oF does not degrade Ceph 4K random-write performance. With NVMe-oF CPU offload on the target node, the CPU overhead on the target node is less than 1 percent. We did not find evidence of CPU overhead on the OSD node. However, we found that with NVMe-oF, the FIO tail latency is much higher than with the local NVMe drive in a high FIO queue depth workload. We still need to identify the root cause and leverage the high-density storage node as a pool for lower TCO.
Summary
We find that the CPU still tends to be the bottleneck in 4K random read/write workloads, which severely limits the peak performance and OSD scale-up ability, even with the latest network layer and object storage backend optimization in the Ceph community. RDMA provides remote memory access, bypassing the kernel to unleash CPU overhead there, and reducing round-trip message transfer time.
We find that iWARP RDMA accelerates the Ceph network layer (async messenger) and improves 4K random-write performance by up to 17 percent. In addition, Ceph with iWARP RDMA shows great scalability. When scaling the Ceph OSD nodes from two to three, the 4K random-write performance increased by 48.7 percent.
According to system metrics on the OSD node, Ceph with iWARP RDMA consumes more CPU. But, through deeper analysis, we see the CPU cycle distribution and find the two polling threads issue in the current RDMA implementation.
Next steps: we will focus on async messenger RDMA performance optimization, including the two polling threads issue. Furthermore, we will explore the opportunity to leverage an NVMe-oF and use the high-density storage node as a storage pool to reduce the TCO of Ceph all-flash array cluster.
References
1. OpenStack User Survey (PDF)
2. Intel Optane technology and Intel® 3D NAND SSDs
3. Ceph system optimization with Intel Optane and Intel Xeon platform
4. RDMA over Commodity Ethernet at Scale (PDF)
5. iWARP RDMA technology brief
6. Accelerating Ceph with RDMA and NVMe-oF
7. Ceph with XIO Messenger performance
8. Hyper-converged Distributed Cache Storage (HDCS)
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors. Performance tests, such as SYSmark* and MobileMark*, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products.
§ Configurations: [describe config + what test used + who did testing].
§ For more information go to http://www.intel.com/performance.
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. Check with your system manufacturer or retailer or learn more at intel.com.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.
This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps.
The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request.
Copies of documents which have an order number and are referenced in this document may be obtained by calling 1-800-548-4725 or by visiting www.intel.com/design/literature.htm.