See Part 1 of this Article Series
This article primarily examines the run workflow and underlying operational logic of Python* programs within the JAX framework and OpenXLA back end. It begins with an overview of the high-level integration structure of OpenXLA and fundamental JAX concepts. By demonstrating the running of a JAX example with OpenXLA on Intel® GPUs, the article provides a detailed analysis of how Python programs are recognized by the JAX framework and transformed into StableHLO (high-level optimizer) representations. OpenXLA then parses these StableHLO expressions into HLO and LLVM intermediate representations, ultimately generating executable SPIR-V files for Intel GPUs, followed by subsequent reorganization and packaging processes.
This article provides an initial exploration of how the JAX framework and OpenXLA compiler interpret Python programs, laying the groundwork for running and analyzing more complex models. It serves as a foundational guide for developers aiming to work on OpenXLA compiler development on Intel GPUs and those involved in debugging JAX and OpenXLA models.
The Run Logic of Actual Cases
HLO Dump to LLVM
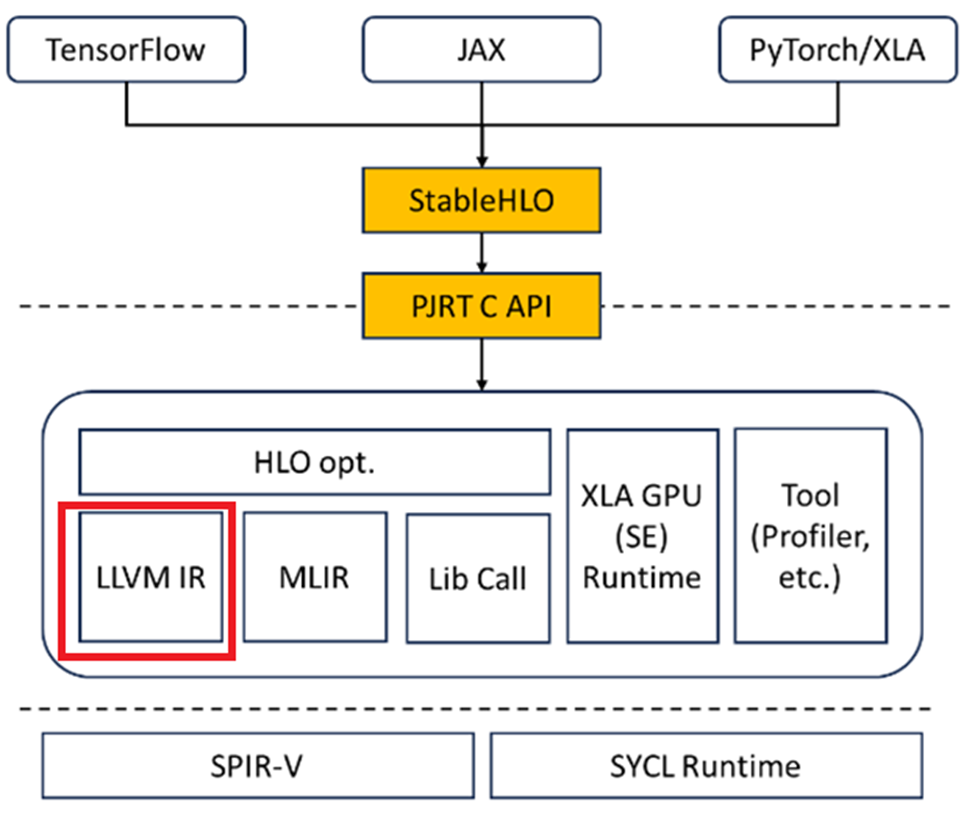
In the OpenXLA compiler, the relationship between HLO representation and LLVM IR (Intermediate Representation) representation reflects the compilation process from high-level operator expressions to low-level machine code generation. HLO uses tensor operations as basic units and expresses the mathematical operations and tensor manipulations involved in the model. See the public LLVM documentation for more information.
HLO is a high-level intermediate representation used in the OpenXLA compiler to represent the computational graph of deep learning models.
LLVM IR is a lower-level intermediate representation that is closer to machine code abstraction and is typically used to describe specific instruction-level operations. LLVM IR is the core of the LLVM compiler framework and is widely used in various compiler toolchains.
The Relationship Between HLO and LLVM IR
- Translation Process: In the OpenXLA compilation flow, HLO serves as a high-level intermediate representation. After a series of optimizations, it is eventually translated into LLVM IR representation. This translation process typically involves refining the high-level operations in HLO and mapping them to low-level instruction sets.
- Mapping and Refinement–Operation Mapping: Each HLO operation may correspond to multiple LLVM IR instructions. For example, an HLO operation for matrix multiplication might be expanded into a series of load, multiply, and accumulate instructions in LLVM IR.
- Hardware-Specific Optimizations: During the generation of LLVM IR, the compiler may use specific hardware features (such as vectorization and pipelining) to perform further optimizations and generate efficient code.
- Code Generation: Once HLO is converted to LLVM IR, the LLVM IR is processed through the LLVM back-end toolchain to ultimately produce machine code specific to the hardware platform (for example, x86, ARM, or CUDA code). However, it will convert to SPIR-V first on the Intel GPU. This machine code is run on the target device.
- Relationship between HLO and LLVM IR: The relationship between HLO and LLVM IR can be seen as a bridge from high-level tensor computation representation to low-level machine code generation. HLO provides a platform-independent, high-level abstraction that facilitates global optimizations, while LLVM IR translates these abstractions into specific instruction sets, enabling hardware-level optimizations and operation. The OpenXLA compiler uses this process to efficiently map deep learning models to various hardware platforms, achieving optimal computational performance.
Environment Variables for Dump LLVM File
$export XLA_FLAGS=“--xla_dump_hlo_as_text --xla_dump_to=./dump
To dump all pass logs, need an extra flag "--xla_dump_hlo_pass_re=.* "
module_0001.jit_integer_pow.ir-no-opt.ll Initial LLVM IR
module_0000.jit_convert_element_type.ir-with-opt.ll Final LLVM IR
module_0001.jit_integer_pow.spv SPIRV file
module_0001.jit_integer_pow.thunk_sequence.txt Execution order
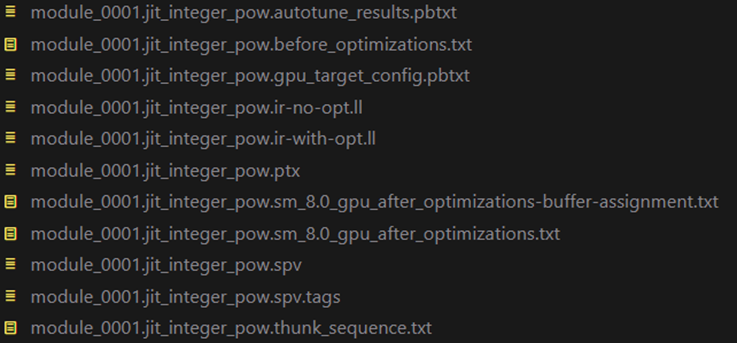
Next, we analyze each file.
Initial LLVM IR
OpenXLA Code Generator HLO to LLVM
For the SPIR (Standard Portable Intermediate Representation) architecture's OpenCL/CUDA kernels, LLVM IR is used for description. It defines a simple kernel function wrapped_multiply for performing multiplication operations on the GPU.
In this file:
Target datalayout: This string specifies the data layout for LLVM IR. It informs the compiler how to arrange data in memory, including the bit-width, alignment, and details of various integer and floating-point types, as well as vector types.
Target triple: Specifies the target platform information.
The code defines the spir_kernel kernel function wrapped_multiply, performing some preliminary calculations including retrieving workgroup and thread IDs and running a simple multiplication operation.
SPIR-V built-in function calls: The code calls built-in SPIR-V functions such as __spirv_BuiltInWorkgroupId and __spirv_BuiltInLocalInvocationId to obtain thread ID information, which is crucial for GPU parallel computation.
Final LLVM IR
The final LLVM IR, after optimization and transformation, is close to the form of the machine code that will ultimately be generated. It includes additional optimizations and hardware-specific transformations beyond the initial IR.
- Kernel Entry Function: In addition to wrapped_multiply, an additional kernel entry function __spirv_entry_wrapped_multiply is defined. This function calls wrapped_multiply and provides the necessary extra encapsulation to ensure the correct kernel execution environment.
- Hardware-Level Optimizations: The code includes completed optimizations such as register allocation, instruction optimization, and alignment corrections, preparing it for further machine code generation.
- Constant Built-in Functions: Constants like @__spirv_BuiltInWorkgroupId and @__spirv_BuiltInLocalInvocationId in memory address space 8 indicate specific data storage locations, reflecting hardware-related optimizations.
Differences Between Initial LLVM IR and Final LLVM IR
Structure and Expression:
- Initial LLVM IR: More raw and abstract, containing high-level operations and platform-independent logic. This stage of IR primarily focuses on describing the computation process with an emphasis on logical accuracy and abstract representation.
- Final LLVM IR: More specific and closer to the hardware layer, involving deeper optimization and hardware mapping. This IR reflects the specific instruction generation and register allocation optimizations for the target architecture.
Changes in Calls and Definitions:
- Handling of Built-in Functions: The Initial LLVM IR directly calls SPIR-V built-in functions, while in the Final LLVM IR, these functions are replaced with constant loads. The function definitions become more specific, reflecting the actual hardware access patterns.
- Entry Functions: An additional entry function __spirv_entry_wrapped_multiply is added in the Final LLVM IR to ensure the correct execution and initialization environment of the kernel.
Relationship between Initial LLVM IR and Final LLVM IR
Conversion and Optimization:
- From Initial to Final: The compiler starts with the Initial IR and applies a series of optimization steps such as constant propagation, register allocation, instruction selection, and memory access optimization to generate a more efficient and specific Final IR.
- Incremental Refinement: The Initial IR serves as an intermediate state in the compilation process, preserving the high-level abstractions of operations. During the generation of the Final IR, the compiler refines these abstractions, mapping them to actual hardware instructions.
- The optimizations between initial HLO and final HLO are done by OpenXLA Extension, and the optimizations between initial LLVM IR and final LLVM IR are done by LLVM, they are not controlled by Intel® Extension for OpenXLA.
- Functional Consistency: Despite the noticeable differences in form, the two versions of the IR are functionally consistent. The Final IR retains the computational logic of the Initial IR but is optimized for efficiency and tailored to meet the specific requirements of the target hardware.
The Initial LLVM IR is an early representation in the compilation process, being more abstract and focused on describing computational logic and basic operations. The Final LLVM IR, on the other hand, is the optimized representation, closer to the final machine code, having undergone hardware-specific optimizations and adjustments.
These two stages of IR represent different phases in the process of transforming high-level language code into low-level machine code. The conversion and optimization between them directly impact the execution efficiency and performance of the final generated code.
SPIR-V File Introduce
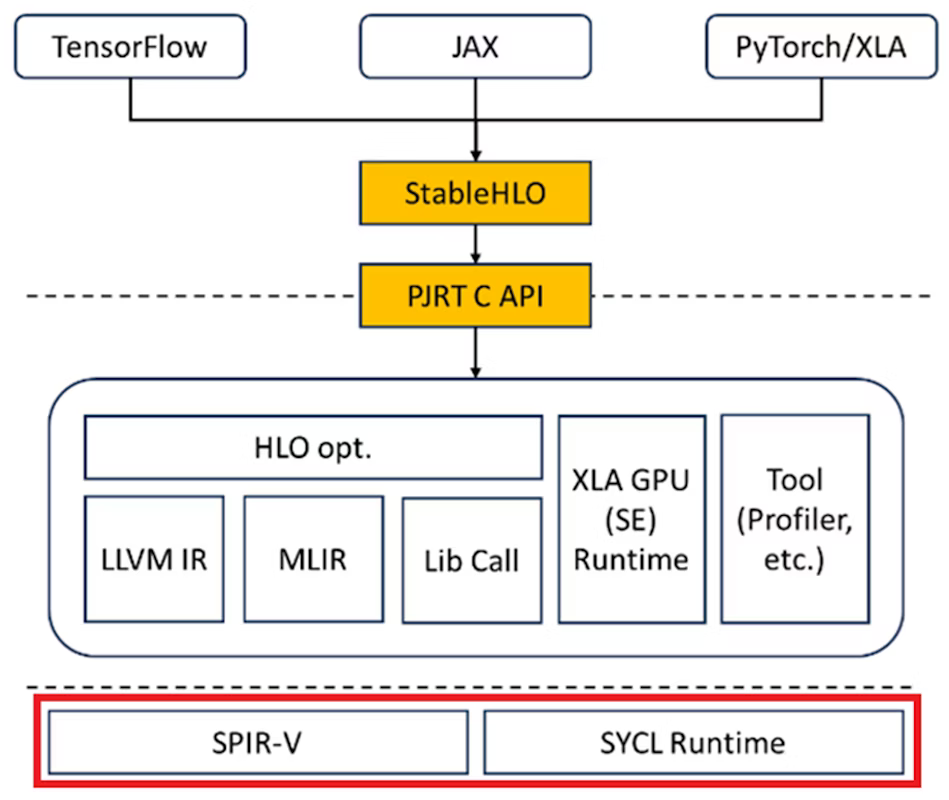
SPIR-V is a binary format version of the Standard Portable Intermediate Representation (SPIR) containing compiled binary code that represents the computation tasks to be run by GPUs or other accelerators.
There's a public translator to convert LLVM IR to SPIR-V for Intel GPU. SPIR-V is a binary intermediate representation format used to describe parallel computing and graphics rendering tasks. By providing a unified representation for different platforms, SPIR-V allows developers to run the code efficiently across various heterogeneous computing environments.
The resulting SPIR-V files can be directly loaded and run on the target hardware, fully using the device's computational capabilities.
The Python expression x^2, after being processed by the JAX framework to generate StableHLO representations, is converted by OpenXLA into HLO and then into LLVM IR. These LLVM IR representations go through a series of optimization and transformation steps to ultimately generate SPIR-V binary files. SPIR-V files can be efficiently run on the target hardware.
How is this file sent to the GPU for running?
- Load the Generated Binary File: The binary file is loaded and then goes through various API calls and transformations to generate a kernel recognized by SYCL.
- Add Parallel Attributes: Various parallel attributes are added to create a sycl_nd_range.
- Start Parallel Execution: parallel_for begins scheduling parallel execution, involving the generated kernel, data pointers, and related parameters for the computation.
- Submit to Queue: queue.submit distributes tasks from the CPU to the GPU for the actual operation. Intel's GPU compiler then intervenes to generate files that the GPU can recognize and use for computation.
The program operation is complete.
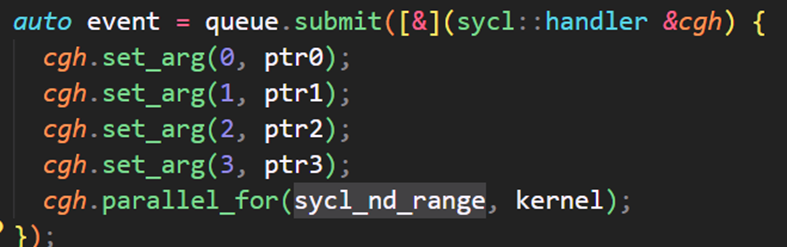
Picture Code
‘’’
auto event = queue.submit([&](sycl::handler &cgh) {
cgh.set_arg(0, ptr0);
cgh.set_arg(1, ptr1);
cgh.set_arg(2, ptr2);
cgh.set_arg(3, ptr3);
cgh.parallel_for(sycl_nd_range, kernel);
});
‘’’
Summary
This article focuses on the specific run process and underlying logic of running practical cases on the OpenXLA stage. OpenXLA parses StableHLO expressions into HLO and LLVM intermediate representations, ultimately generating executable SPIR-V files for Intel GPUs, followed by subsequent reorganization and packaging processes. It serves as an initial explanation for developers working on OpenXLA compiler development for Intel GPUs and the debugging process for JAX and OpenXLA.