See Part 2 of this Article Series
This article primarily examines the operation workflow and underlying operational logic of Python* programs within the JAX framework and OpenXLA* back end. It begins with an overview of the high-level integration structure of OpenXLA and fundamental JAX concepts. By demonstrating the operation of a JAX example with OpenXLA on Intel® GPUs, this article provides a detailed analysis of how Python programs are recognized by the JAX framework and transformed into StableHLO (high-level optimizer) representations. OpenXLA then parses these StableHLO expressions into HLO.
This article initially explores how the JAX framework and OpenXLA compiler interpret Python programs, laying the groundwork for running and analyzing more complex models. It is a foundational guide for developers aiming to work on OpenXLA compiler development on Intel GPUs and those involved in debugging JAX and OpenXLA models.
JAX: Auto-grad and XLA
JAX is a Python library for accelerator-oriented array computation and program transformation designed for high-performance numerical computing and large-scale machine learning.
Intel® Extension for OpenXLA*
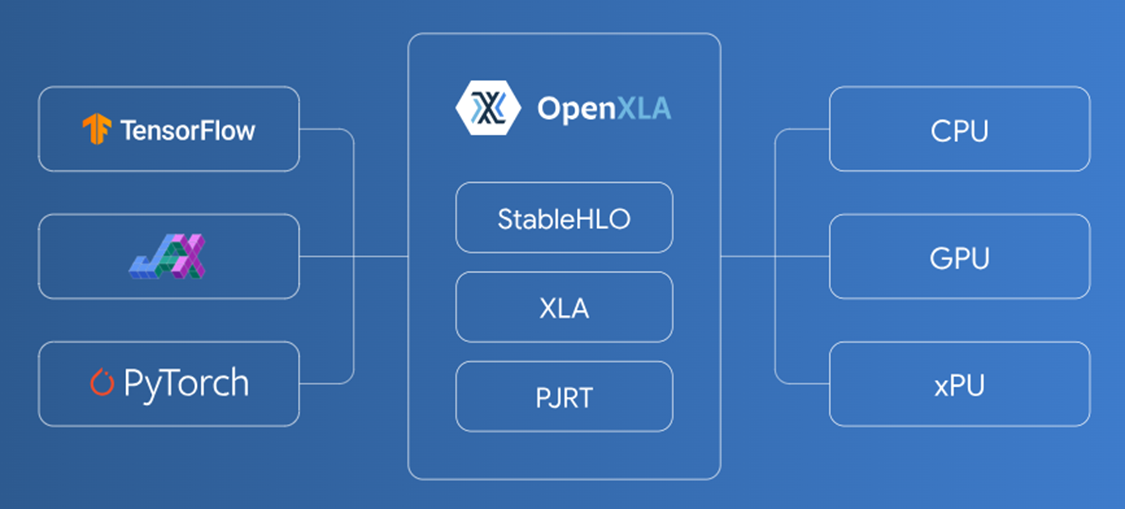
The OpenXLA Project brings together a community of developers and leading AI and machine learning teams to accelerate machine learning and address infrastructure fragmentation across machine learning frameworks and hardware.
Intel® Extension for OpenXLA* includes PJRT plug-in implementation, which seamlessly runs JAX models on Intel GPUs. The PJRT API simplified the integration, which allowed the Intel GPU plug-in to be developed separately and quickly integrated into JAX. This same PJRT implementation also enables initial Intel GPU support for TensorFlow and PyTorch models with XLA acceleration. Refer to OpenXLA PJRT Plug-in RFC for more details.

The combination of JAX and Intel Extension for OpenXLA provides better hardware adaptation and model acceleration for Intel GPUs.
The Operation Logic of Actual Cases
Explain the operation process of a Python script in the JAX Framework with the OpenXLA back end, using an example to help understand program and data transformation.
The JAX framework parses the Python program, OpenXLA generates the computation graph, and the operations run on the GPU hardware.
The following operation process and details will demonstrate the development and debugging process of JAX and OpenXLA. The entire process is divided into the following stages: JAX expression, StableHLO, Initial HLO, Final HLO, Initial LLVM IR, Final LLVM IR, and SPIRV file.
Now, let's explain this with a real-world example:

Picture Code
‘’’
import jax.numpy as jnp
from jax import grad
def simple_function(x):
return x**2 + 3*x + 2
gradient = grad(simple_function)
x = 2.0
computed_gradient = gradient(x)
print("Computed Gradient:", computed_gradient)
‘’’
JAX Expression Dump to StableHLO File
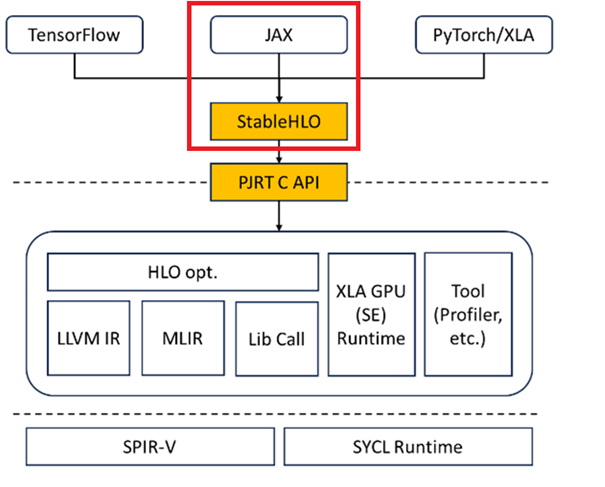
Intel Extension for OpenXLA directly calls the public StableHLO module without making additional changes or optimizations. The public StableHLO module is responsible for converting JAX expressions. Refer to the OpenXLA explanation of this module for more information. JAX framework development focuses more on StableHLO expressions.
The JAX framework first converts the Python expressions into StableHLO expressions. By setting export JAX_DUMP_IR_TO="dump", it generates a text file similar to jax_ir0_xxx.mlir, which records the detailed operation process of the expressions. View OpenXLA official document for more information.
$ export JAX_DUMP_IR_TO=”dump” python grade.py

Since OpenXLA primarily focuses on stages beyond StableHLO, a brief explanation of the subsequent steps is provided below:
-
jax_ir0_jit_convert_element_type_compile.mlir: A simple JIT compilation module, @jit_convert_element_type, is defined, which includes a function named @main. This function takes a floating-point tensor as input and directly returns the tensor without any operations.
The module @jit_convert_element_type contains some attributes, such as mhlo.num_partitions and mhlo.num_replicas, both set to 1 and of type i32 (32-bit integer). These attributes specify the number of partitions and replicas for parallel computation during the JIT compilation process.
- jax_ir1_jit_integer_pow_compile.mlir:
Processing x^2: This step involves a simple tensor operation represented using MLIR, which computes the square of an input tensor at runtime via a JIT (Just-In-Time) compiler. tensor<f32> represents a 32-bit floating-point tensor.
The @jit_integer_pow module has some attributes, with mhlo.num_partitions and mhlo.num_replicas both set to 1. It is a function or operation that computes integer powers (for example, x^y), where x is the base and y is the exponent. This operation is commonly used in mathematical or scientific computations where a number needs to be raised to a specified integer power.
Tensor Multiplication Operation: Using stablehlo.multiply (a stable high-level operation representing multiplication) to compute the result of %arg0 multiplied by itself and store the result in %0. loc(#loc7) indicates the location of this operation, marked as #loc7.
Function: This operation performs the actual tensor multiplication and computes the square of the input tensor %arg0. The location marker #loc7 helps track the source code context of this multiplication operation.
#loc(numbers): Location markers are used not only for code tracing but also to aid in understanding the origins of various steps and operations during optimization and debugging.
- jax_ir2_jit_integer_pow_compile.mlir/ jax_ir3_jit_mul_compile.mlir/ jax_ir11_jit_add_compile.mlir: These parts of the definition are like the file mentioned above.
- jax_ir4_jit_fn_compile.mlir/jax_ir5_jit_fn_compile.mlir/jax_ir6_jit_fn_compile.mlir: A simplified computation graph represented using MLIR and StableHLO. It defines a module named @jit_fn and a computation process in the @main function, which includes multiplication, addition, and data type conversion operations. The corresponding operation markers are used for tracking and locating during debugging and optimization.
- jax_ir7_jit_convert_element_type_compile.mlir: Using MLIR syntax, the JIT compilation process demonstrates a data type conversion operation. The stablehlo.convert instruction converts the input tensor %arg0 to a tensor of the same type (tensor<f32>). Since the input and output types are the same (tensor<f32>), this conversion does not change the data representation.
- jax_ir8_jit_fn_compile.mlir/ jax_ir9_jit_fn_compile.mlir/ jax_ir10_jit_fn_compile.mlir: Data Transmission and Output Structure for Testing or Simple Data Flow Verification
File Relationships in Terms of Operations
Common Features:
- Module and Function Definitions: Each code block defines a module named @jit_fn, which contains a @main function. This function is marked as public, meaning it can be called from outside the module.
- JIT Compilation: JIT is a decorator in JAX used to optimize functions through JIT compilation, reducing the overhead of the Python interpreter and making computations more efficient on hardware (such as CPUs or GPUs).
- Tensors: The primary objects handled by the functions are tensors (tensor), which are 32-bit floating-point tensors (tensor<f32>) in each code snippet.
- Location Information: Each piece of code includes location information (such as #loc) that tracks the source location of the code, primarily for debugging and optimization contexts.
Operation Process Relationships:
- JIT Compilation Context: All three code snippets are JIT-compiled, with the optimized code running efficiently on hardware.
- Function Return Values: The return value structures of the first two snippets are similar, but jax_ir8_jit returns a single value, while jax_ir9_jit returns two values. The return value of jax_ir10_jit is the result of the computation.
- Data Flow: jax_ir8_jit and jax_ir9_jit focus more on data transmission and output structures, while jax_ir10_jit demonstrates actual computation operations within the JAX framework.
jax_ir8_jit and jax_ir9_jit are simple tensor-passing functions mainly used for data flow verification. jax_ir10_jit showcases more complex computational operations within the JAX framework, combining tensor operations to illustrate how basic mathematical computations are performed in JAX.
StableHLO Dump to HLO

Environment Variables for Dump HLO file:
- $export XLA_FLAGS=“--xla_dump_hlo_as_text --xla_dump_to=./dump
- To dump all pass logs, an extra flag is needed "--xla_dump_hlo_pass_re=.* "
- module_0000.jit_convert_element_type.gpu_target_config.pbtxt Hardware Information
- module_0000.jit_convert_element_type.before_optimizations.txt Initial HLO
- module_0000.jit_convert_element_type.sm_8.0_gpu_after_optimizations.txt Final HLO
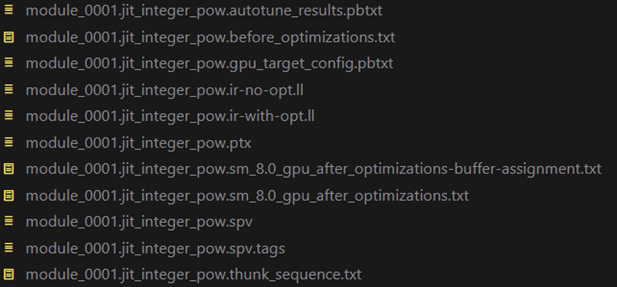
In the JAX expression dump to StableHLO phase, each file serves as input to OpenXLA, generating the corresponding steps of HLO representation. The above shows the further representation of the jit_integer_pow module, which can be used as a reference to facilitate understanding the other steps. View the OpenXLA public document for more details.
Next, we will analyze each file.
Hardware Info File
This file will record static information about the hardware used, including the configuration and performance parameters of the GPU devices, such as threads_per_block_limit, threads_per_warp, shared_memory_per_block, shared_memory_per_core, and so on.
Initial HLO
Defines an HLO module named jit_integer_pow, which describes a computation process where an input scalar floating-point number is squared. This corresponds directly to the integer_pow operation from the previous JAX expression dump, where the square of x is represented. The previous corresponding operation has been transformed into the HLO representation, where Arg_0.1 is multiplied by itself. The multiply operation computes the square of the input parameter.
- HloModule jit_integer_pow: This is an HLO module named jit_integer_pow. The HLO (High-Level Optimizer) module is an intermediate representation used by the XLA (Accelerated Linear Algebra) compiler, typically for optimizing and running deep learning computation graphs.
- entry_computation_layout={(f32[])->f32[]}: This part defines the layout of the entry computation. Specifically, it describes that the computation graph takes an f32[] scalar floating-point number as input and returns an f32[] scalar floating-point number as output.
- metadata={...}: This part attaches metadata to the operation, used to trace the source of the operation in the source code, including the operation name, file location, and the operation's position in the source file.
- source_line=*: This indicates that this operation is defined on line * of the source file.
Final HLO
HLO module jit_integer_pow contains two computation operations:
-
- wrapped_multiply_computation: Computes the square of param_0.
- main.3: Defines the entry point, passing the input parameter Arg_0.1.0 to wrapped_multiply_computation for computation and returning the result.
- wrapped_multiply_computation: Computes the square of param_0.
The module sets up SPMD (Single Program Multiple Data) shard propagation, specifies the computation layout, and attaches frontend attributes and metadata.
is_scheduled=true: Indicates that the computation graph has been scheduled, meaning the operations have been arranged in a certain order.
The Relationship Between StableHLO and HLO
- Conversion Chain: StableHLO is an early-stage representation used for high-level model computation, while HLO represents a subsequent stage. StableHLO is transformed into HLO, which is then further optimized to generate machine code.
- Optimization Bridge: StableHLO provides a stable interface, and HLO is responsible for optimizing these high-level abstractions for hardware operation. The conversion between the two is a crucial part of the OpenXLA compiler chain.
StableHLO is a higher-level representation focused on expression and abstraction, while HLO further refines these representations and optimizes the computation graph for efficient mapping to the target hardware.
Summary
This section introduces the basic concepts of JAX and Intel Extension for OpenXLA, including how the JAX framework transforms Python expressions into StableHLO expressions and StableHLO dump to HLO. It includes a brief overview of each file related to StableHLO and HLO. The next article will explain LLVM and SPIR-V parts.
See Part 2 of this Article Series