In scientific research, data analytics, and finance, getting the same result for a subroutine every single time code is executed at a given precision is key. By its very nature, floating-point arithmetic on computers is, however, impacted by limited storage for floating-point numbers and requires computers to truncate and round the results of some math operations. One programming idiom that is not always reproducible is the global sum reduction of a distributed array. Changing the number of compute units changes the order in which array elements are added together, which, in turn, changes the truncation and rounding. This may change the result of individual add operations and the resulting global sum. Therefore, floating-point addition is not always associative.[1]
This is the type of problem Conditional Numerical Reproducibility (CNR) addresses.
A decade ago, it was introduced as a feature in the one API Math Kernel Library (oneMKL) and its predecessor, the Intel® Math Kernel Library (Intel® MKL). Originally developed for CPUs, with oneMKL 2024.1, some of this functionality is now also available for workloads running on Intel® GPUs.
CNR provides functions for obtaining consistently reproducible floating-point (FP) results when calling library functions from their application. With CNR enabled, oneMKL functions are designed to return the same floating-point results from run-to-run, subject to the following limitations:
- Calls to oneMKL occur in a single executable.
- The number of computational threads the library uses remains constant throughout the run.
OneMKL supports strict CNR mode for bitwise identical results for a specific subset of functions. This level of determinism focused on key BLAS functionality is also important for GPU-based acceleration, which has now been introduced for GPUs. When enabled, the functions supporting strict CNR mode will return exactly identical results even if the number of computational threads varies. We will go into more detail on this later in the article.
Floating Point Numerical Reproducibility on GPUs
oneMKL 2024.1 introduces CNR support on GPU, providing bitwise reproducible results for the following routines:
- BLAS level-3 routines (gemm, symm, hemm, syrk, herk, syr2k, her2k, trmm, trsm), all precisions.
- BLAS level-3 extensions (batched versions of above, and gemmt), all precisions.
When any CNR code branch is enabled, GPU CNR support will be enabled automatically, ensuring run-to-run bitwise reproducible results for these routines on Intel® GPUs.
Note: The specific code branch chosen (AVX2, AVX-512, etc.) is ignored for GPU execution.
Two GPUs are considered the same if they have the same product name, e.g. Intel® Arc™ A770. Note that results may differ across devices (between CPU and GPU or between different kinds of GPUs).
Both OpenMP* offload APIs and SYCL APIs support GPU CNR mode.
Enabling Numerical Reproducibility for GPUs
Using the call mkl_cbwr_set() or the environment variable MKL_CBWR with any of the CPU CNR code path settings described in the developer guide will also enable it for GPU offload. A list of these code path options can also be found in this article below under the heading: “Supported CPU Instruction Set Settings”.
Alternatively, to ensure selected oneMKL calls return the same results on every Intel GPU you can also simply do either of the following:
- Call
mkl_cbwr_set(MKL_CBWR_AUTO) - Set the environment variable:
export MKL_CBWR = AUTO <Linux>
set MKL_CBWR=AUTO <Windows>
OpenMP* Offload
When using OpenMP offload to execute oneMKL routines on the GPU, numerical reproducibility is supported for BLAS level-3 routines and batched extensions, starting in version 2024.1. CNR will be enabled for GPU whenever any CNR code branch is enabled (i.e., a setting other than MKL_CBWR_OFF or MKL_CBWR_BRANCH_OFF). See the oneMKL Developer Guide for more information on CNR support for GPU.
Conditional Numerical Reproducibility Overview
It is well known that for general single and double precision IEEE floating-point numbers, the associative property does not always hold, meaning (a+b)+c may not equal a +(b+c). Let's consider a specific example. In infinite precision arithmetic 2-63 + 1 + -1 = 2-63. If instead we do this same computation on a computer use double precision floating-point numbers, rounding error is introduced and we clearly see why order of operations becomes important:
(2-63 + 1) + (-1) ≈ 1 + (-1) = 0
versus
2-63 + (1 + (-1)) ≈ 2-63 + 0 = 2-63
This inconsistency in results due to order-of-operations is precisely what the new functions are designed to address.
The application related factors that affect the order of floating-point operations within a single executable program include code-path selection based on run-time processor dispatching, data array alignment, variation in number of threads, threaded algorithms, and internal floating-point control settings. The user can control most of these factors by properly controlling the number of threads, floating point settings and taking steps to align memory when allocated. On the other hand, run-time dispatching and certain threaded algorithms have not allowed users to make changes to ensure the same order of operations from run to run.
oneMKL does run-time processor dispatching to identify the appropriate internal code paths to traverse for the oneMKL functions called by the application. The code paths chosen may differ across a wide range of Intel processors and IA compatible processors and may provide differing levels of performance. For example, a oneMKL function running on an Intel® Pentium® 4 processor may run an SSE2-based code path, while on a more recent Intel® Xeon® processor supporting Intel® Advanced Vector Extensions (AVX), that same library function may dispatch to a different code path that uses these AVX instructions. This is because each unique code path has been optimized to match the features available on the underlying processor. The feature-based approach introduces a challenge: if any internal floating-point operations are done in a different order or re-associated, then the computed results may differ.
Dispatching optimized code-paths based on the capabilities of the processor on which it is running is central to the optimization approach used by oneMKL so it is natural that there should be some performance trade-offs when requiring consistent results. If limited to a particular code-path, oneMKL performance can, in some circumstances, degrade by more than half., This can be easily understood by noting that matrix-multiply performance nearly doubled with the introduction of new processors supporting AVX instructions. In other cases, performance may degrade by 10-20% if algorithms are restricted to maintain the order of operations.
Supported CPU Instruction Set Settings
To ensure oneMKL calls return the same results on all Intel or Intel compatible CPUs supporting SSE2 instructions or later:
Make sure your application uses a fixed number of threads and call
mkl_cbwr_set(MKL_CBWR_COMPATIBLE)
or set the environment variable
MKL_CBWR=COMPATIBLE
Note: the special MKL_CBWR_COMPATIBLE option is provided because Intel and Intel compatible CPUs have approximation instructions (e.g., rcpps/rsqrtps) that may return different results. This option ensures that Intel MKL uses an SSE2 only code-path which does not use these instructions.
To ensure oneMKL calls return the same results on every Intel CPU that supports SSE2 instructions or later:
Make sure your application uses a fixed number of threads and call
mkl_cbwr_set(MKL_CBWR_SSE2)
or set the environment variable
MKL_CBWR=SSE2
Note: on non-Intel CPUs results may differ because the MKL_CBWR_COMPATIBLE code path is run instead.
To ensure oneMKL calls return the same results on every Intel CPU that supports SSE4.1 instructions or later:
Make sure your application uses a fixed number of threads and call
mkl_cbwr_set(MKL_CBWR_SSE4_1)
or set the environment variable
MKL_CBWR=SSE4_1
Note: on non-Intel CPUs the results may differ because the MKL_CBWR_COMPATIBLE code path is run instead.
Ensure oneMKL calls return the same results on every Intel CPU that supports Intel® AVX instructions or later:
Make sure your application uses a fixed number of threads and call
mkl_cbwr_set(MKL_CBWR_AVX)
or set the environment variable
MKL_CBWR=AVX
Note: on non-Intel CPUs the results may differ because the MKL_CBWR_COMPATIBLE code path is run instead. On an Intel CPU without AVX support, the MKL_CBWR_DEFAULT path is run instead.
Ensure oneMKL calls return the same results on every Intel CPU that supports Intel® AVX2 instructions or later:
Make sure your application uses a fixed number of threads and call
mkl_cbwr_set(MKL_CBWR_AVX2)
or set the environment variable
MKL_CBWR=AVX2
Note: on non-Intel CPUs, the results may differ because the MKL_CBWR_COMPATIBLE code path is run instead. On an Intel CPU without AVX2 support, the MKL_CBWR_DEFAULT path is run instead.
Please consult the developer guide for additional details.
Strict CNR Mode on CPU
Strict CNR mode provides stronger reproducibility guarantees for specific routines and conditions. When strict CNR is enabled, oneMKL will produce bitwise identical results, regardless of the number of threads, for the following functions:
- ?gemm, ?trsm, ?symm, and their CBLAS equivalents.
Additionally, strict CNR is only supported under the following conditions:
- the CNR code-path must be set to AVX2 or later, or the AUTO code-path is used and the processor is an Intel processor supporting AVX2 or later instructions;
- the 64-bit Intel oneMKL libraries are used.
To enable strict CNR, add the new MKL_CBWR_STRICT flag to the CNR code-path you would like to use:
mkl_cbwr_set(MKL_CBWR_AVX512 | MKL_CBWR_STRICT)
or append “,STRICT” to the MKL_CBWR environment variable:
MKL_CBWR = AVX2,STRICT
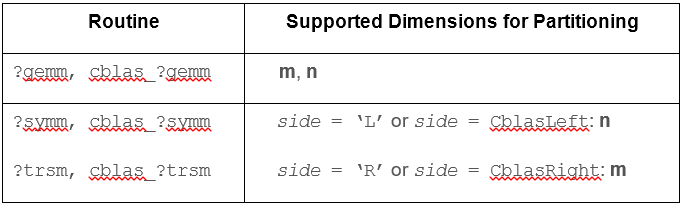
Besides guaranteeing run-to-run reproducibility for varying numbers of threads, strict CNR also allows the expert user to partition their input matrices, call ?gemm, ?symm, or ?trsm on the resulting sub-problems, then reassemble the results. When strict CNR is enabled, the results will be bitwise identical, no matter how the inputs are partitioned, as long as partitioning is performed only along the dimensions listed in the table below:
Make Your Floating Point Math Numerically Reproducible
Ensure floating point numerical reproducible calculations for your math routines on both Intel® CPUs and Intel® GPUs.
Download the latest Intel® oneAPI Math Kernel Library 2024.1 standalone or as part of the Intel® oneAPI Base Toolkit today.
Additional References:
- Developer Guide for Intel® oneAPI Math Kernel Library Linux*
- Developer Guide for Intel® oneAPI Math Kernel Library Windows*
- Intel® oneAPI Math Kernel Library Cookbook
- Developer Reference for Intel® oneAPI Math Kernel Library
[1] Sara Faraji Jalal Apostal et al., “Improving Numerical Reproducibility of Scientific Software in Parallel Systems”, IEEE International Conference on Electro-Information Technology, 2020