Introduction
To efficiently utilize all available resources for the task concurrency application on heterogeneous platforms, designers need to understand the memory architecture, the thread utilization on each platform, the pipeline to offload the workload to different platforms, and to coordinate all these activities.
To relieve designers of the burden of implementing the necessary infrastructures, the Heterogeneous Streaming (hStreams) library provides a set of well-defined APIs to support a task-based parallelism model on heterogeneous platforms. hStreams explores the use of the Intel® Coprocessor Offload Infrastructure (Intel® COI) to implement these infrastructures. That is, the host decomposes the workload into tasks, one or more tasks are executed in separate targets, and finally the host gathers the results from all of the targets. Note that the host can also be a target too.
Intel® Manycore Platform Software Stack (Intel® MPSS) version 3.6 contains the hStreams library, documentation, and sample codes. Starting from Intel MPSS 3.7, hStreams is removed from Intel MPSS software and becomes an open source project. The current version 1.0 supports the Intel® Xeon® processor and Intel® Xeon Phi™ coprocessor as targets. hStreams binaries version 1.0.0 can be downloaded:
- https://01.org/sites/default/files/downloads/hetero-streams-library/hstreams-1.0.0.tar (for Linux*)
- https://01.org/sites/default/files/downloads/hetero-streams-library/hstreams-1.0.0.zip (for Windows*)
Users can contribute to hStreams development at https://github.com/01org/hetero-streams. The following tables summarize the tools that support hStreams in Linux and Windows:
| Name of Tool (Linux*) | Supported Version |
|---|---|
| Intel® Manycore Platform Software Stack | 3.4, 3.5, 3.6, 3.7 |
|
Intel® C++ Compiler |
15.0, 16.0 |
| Intel® Math Kernel Library | 11.2, 11.3 |
| Name of Tool (Windows*) | Supported Version |
|---|---|
| Intel MPSS | 3.4, 3.5, 3.6, 3.7 |
|
Intel C++ Compiler |
15.0, 16.0 |
| Intel Math Kernel Library | 11.2, 11.3 |
|
Visual Studio* |
11.0 (2012) |
This whitepaper briefly introduces hStreams and highlights its concepts. For a full description, readers are encouraged to read the tutorial included in the hStreams package mentioned above.
Execute model concepts
This section highlights some basic concepts of hStreams: source and sink, domains, streams, buffers, and actions:
- Streams are FIFO queues where actions are enqueued. Streams are associated with logical domains. Each stream has two endpoints: source and sink, which is bound to a logical domain.
- Source is where the work is enqueued and sink where the work is executed. In the current implementation, the source process runs on an Intel Xeon processor-based machine, and the sink process runs on a machine that can be the host itself, an Intel Xeon Phi coprocessor, or in the future, even any hardware platform. The library allows the source machine to invoke the user’s defined function on the target machine.
- Domains represent the resources of hetero platforms. A physical domain is the set of all resources available in a platform (memory and computing). For example, an Intel Xeon processor-based machine and an Intel Xeon Phi coprocessor are two different physical domains. A logical domain is a subset of a given physical domain; it uses any subset of available cores in a physical domain. The only restriction is that two logical domains cannot be partially overlapping.
- Buffers represent memory resources to transfer data between source and sink. In order to transfer data, the user must create a buffer by calling an appropriate API, and a corresponding physical buffer is instantiated at the sink. Buffers can have properties such as memory type (for example, DDR or HBW) and affinity (for example, sub-NUMA clustering).
- Actions are requests to execute functions at the sinks (compute action), to transfer data from source to sink or vise-versa (memory movement action), and to synchronize tasks among streams (synchronization action). Actions enqueued in a stream are proceeded in first in, first out (FIFO) semantics: The source places the action in and the sink removes the action. All actions are non-blocking (asynchronous) and have completion events. Remote invocation can be user-defined functions or optimized convenient functions (for example, dgemm). Thus, a FIFO stream queue handles dependencies within a stream while synchronization actions handle dependencies among streams.
In a typical scenario, the source-side code allocates stream resources, allocates memory, transfers data to the sink, invokes the sink to execute a predefined function, handles synchronization, and eventually terminates streams. Note that actions such as data transferring, remote invocation, and synchronization are handled in FIFO streams. The sink-side code simply executes the function that the source requested.
For example, consider the pseudo-code of a simple hStreams application that creates two streams, the source transfers data to the sinks, performs remote invocation at the sinks, and then transfers results back to the source host:
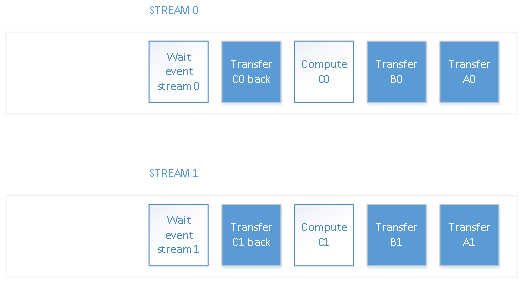
Step 1: Initialize two streams 0 and 1
Step 2: Allocate buffers A0, B0, C0, A1, B1, C1
Step 3: Use stream i, transfer memory Ai, Bi to sink (i=0,1)
Step 4: Invoke remote computing in stream i: Ai + Bi -> Ci (i=0,1)
Step 5: Transfer memory Ci back to host (i=0,1)
Step 6: Synchronize
Step 7: Terminate streams
The following figure illustrates the actions generated at the host:

Actions are placed in the corresponding streams and removed at the sinks:
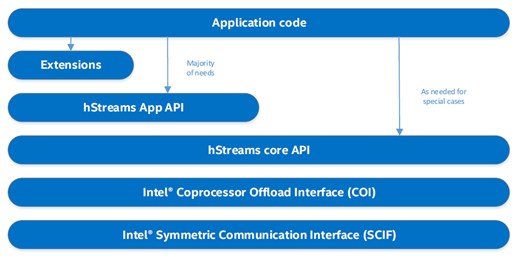
hStreams provides two levels of APIs: the app API and the core API. The app API offers simple interfaces; it is targeted to novice users to quickly ramp on hStreams library. The core API gives advanced users the full functionality of the library. The app APIs in fact call the core layer APIs, which in turn use Intel COI and the Symmetric Communication Interface (SCIF). Note that users can mix these two levels of API when writing their applications. For more details on the hStreams API, refer to the document Programming Guide and API Reference. The following figure illustrates the relation between the hStreams app API and the core API.
Refer to the document “Hetero Streams Library 1.0 Programming Guide and API” and the tutorial included in the hStreams download package for more information.
Building and running a sample hStreams program
This section illustrates a sample code that makes use of the hStreams app API. It also demonstrates how to build and run the application. The sample code is an MPI program running on an Intel Xeon processor host with two Intel Xeon Phi coprocessors connected.
First, download the package from https://github.com/01org/hetero-streams. Then, follow the instruction to build and install the hStreams library on an Intel Xeon processor-based host machine that runs Intel MPSS 3.7.2 in this case. This host machine has two Intel Xeon Phi coprocessors installed and connects to a remote Intel Xeon processor-based machine. This remote machine (10.23.3.32) also has two Intel Xeon Phi coprocessors.
This sample code creates two streams; each stream runs explicitly on a separate coprocessor. An MPI rank manages these two streams.
The application consists of two parts: The source-side code is shown in Appendix A and the corresponding sink-side code is shown in Appendix B. The sink-side code contains a user-defined function vector_add, which is to be invoked by the source.
This sample MPI program is designed to run with two MPI ranks. Each MPI rank runs on a different domain (Intel Xeon processor host) and initializes two streams; each stream is responsible for communicating with a coprocessor. The MPI ranks enqueues the required actions into the streams in the following order: Memory transfer action from source to sink action, remote invocation action, and memory transfer action from sink to source. The following app APIs are called in the source-side code:
hStreams_app_init:Initialize and create streams across all available Intel Xeon Phi coprocessors. This API assumes one logical domain per physical domain.hStreams_app_create_buf:Create an instantiation of buffers in all currently existing logical domains.hStreams_app_xfer_memory:Enqueue memory transfer action in a stream; depending on the specified direction, memory is transferred from source to sink or sink to source.hStreams_app_invoke:Enqueue a user-defined function in a stream. This function is executed at the stream sink. Note that the user also needs to implement the remote target function in the sink-side program.hStreams_app_event_wait:This sync action blocks until the set of specified events is completed. In this example, only the last transaction in a stream is required, since all other actions should be completed.hStreams_app_fini:Destroy hStreams internal structures and clear the library state.
Intel MPSS 3.7.2 and Intel® Parallel Studio XE 2016 update 3 are installed on the host machine Intel® Xeon® processor E5-2600. First, bring the Intel MPSS service up and set up compiler environment variables on the host machine:
$ sudo service mpss start
$ source /opt/intel/composerxe/bin/compilervars.sh intel64
To compile the source-side code, link the source-side code with the dynamic library hstreams_source which provides source functionality:
$ mpiicpc hstream_sample_src.cpp –O3 -o hstream_sample -lhstreams_source \ -I/usr/include/hStreams -qopenmp
The above command generates the executable hstream_sample. To generate the user kernel library for the coprocessor (as sink), compile with the flag –mmic:
$ mpiicpc -mmic -fPIC -O3 hstream_sample_sink.cpp –o ./mic/hstream_sample_mic.so \ -I/usr/include/hStreams -qopenmp -shared
To follow the convention, the target library takes the form <exec_name>_mic.so for the Intel Xeon Phi coprocessor and <exec_name>_host.so for the host. This generates the library named hstream_sample_mic.so under the folder /mic.
To run this application, set the environment variable SINK_LD_LIBRARY_PATH so that hStreams runtime can find the user kernel library hstream_sample_mic.so
$ export SINK_LD_LIBRARY_PATH=/opt/mpss/3.7.2/sysroots/k1om-mpss-linux/usr/lib64:~/work/hStreams/collateral/delivery/mic:$MIC_LD_LIBRARY_PATH
Run this program with two ranks, one rank running on this current host and one rank running on the host whose IP address is 10.23.3.32, as follows:
$ mpiexec.hydra -n 1 -host localhost ~/work/hstream_sample : -n 1 -wdir ~/work -host 10.23.3.32 ~/work/hstream_sample
Hello world! rank 0 of 2 runs on knightscorner5
Hello world! rank 1 of 2 runs on knightscorner0.jf.intel.com
Rank 0: stream 0 moves A
Rank 0: stream 0 moves B
Rank 0: stream 1 moves A
Rank 0: stream 1 moves B
Rank 0: compute on stream 0
Rank 0: compute on stream 1
Rank 0: stream 0 Xtransfer data in C back
knightscorner5-mic0
knightscorner5-mic1
Rank 1: stream 0 moves A
Rank 1: stream 0 moves B
Rank 1: stream 1 moves A
Rank 1: stream 1 moves B
Rank 1: compute on stream 0
Rank 1: compute on stream 1
Rank 1: stream 0 Xtransfer data in C back
knightscorner0-mic0.jf.intel.com
knightscorner0-mic1.jf.intel.com
Rank 0: stream 1 Xtransfer data in C back
Rank 1: stream 1 Xtransfer data in C back
sink: compute on sink in stream num: 0
sink: compute on sink in stream num: 0
sink: compute on sink in stream num: 1
sink: compute on sink in stream num: 1
C0=97.20 C1=90.20 C0=36.20 C1=157.20 PASSED!
Conclusion
hStreams provides a well-defined set of APIs allowing users to design a task-based application on heterogeneous platforms quickly. Two levels of hStreams API co-exist: The app API offers simple interfaces for novice users to quickly ramp on the hStreams library, and the core API gives advanced users the full functionality of the rich library. This paper presents some basic hStreams concepts and illustrates how to build and run an MPI program that takes advantages of the hStreams interface.
About the Author
Loc Q Nguyen received an MBA from University of Dallas, a master’s degree in Electrical Engineering from McGill University, and a bachelor's degree in Electrical Engineering from École Polytechnique de Montréal. He is currently a software engineer with Intel Corporation's Software and Services Group. His areas of interest include computer networking, parallel computing, and computer graphics.