Executive Summary
The new Intel® Xeon® Scalable processor family provides dramatically improved cryptographic performance for data at rest and in transit. Many Advanced Encryption Standard (AES)1 based encryption schemes will immediately benefit from the 75 percent improvement in Intel® Advanced Encryption Standard New Instruction (Intel® AES-NI) instruction latency. In addition to improvements in existing technologies, the new Intel® Advanced Vector Extensions 512 (Intel® AVX–512) instruction family brings up to 3X performance gains1 over previous-generation Intel® Advanced Vector Extensions 2 (Intel® AVX2) implementations of secure hashing. These performance gains for cryptographic primitives improve throughput for intensive workloads in markets such as networking and storage, lowering the barrier to making encryption ubiquitous.
Overview
With strong security becoming a ubiquitous data center application prerequisite, any associated cryptographic performance tax takes computes away from the main function. Intel’s focus on providing primitives in every core to accelerate cryptographic algorithms has helped alleviate this burden and enable demanding workloads to achieve remarkable throughputs on general purpose servers2. One example of this is the continued performance increases of Intel® AES-NI since its original launch in 2010. This focus also holds for the introduction of new features that provide significant gains over previous generations1.
With Intel® Xeon Scalable Processors, the improved Intel AES-NI design and introduction of Intel® AVX-512 brings a new level of cryptographic performance to the data center. This paper examines the gains seen in two modes of AES operation, Galois counter mode (GCM) and cipher block chaining (CBC), as a result of the Intel AES-NI improvements. The impact of Intel AVX-512 will be demonstrated with the secure hashing algorithms (SHA-1, SHA-256, and SHA-512)3, in particular comparing the new results against Intel® AVX2 based implementations from the previous Haswell/Broadwell generation of Intel Xeon processors.
Intel® Xeon® Scalable Processor Improvements
The cryptographic performance enhancements seen in the Intel Xeon Scalable processors are due to new instructions, micro architectural updates, and novel software implementations. Intel AVX-512 doubles the instruction operand size from 256 bits in Intel AVX2 to 512 bits. In addition to the 2X increase in amount of data that can be processed at once, powerful new instructions such as VPTERNLOG enable more complex operations to be executed per cycle. Combining Intel AVX-512 with the multibuffer software technique for parallel processing of data streams spectacularly improves SHA performance. The latency reduction of the AES Encrypt and AES Decrypt (AESENC/AESDEC) instructions along with the improved microarchitecture have shown gains in both parallel and serial modes of AES operation.
AES
The new Intel® Xeon® Scalable processor has significantly reduced the latency of AES instructions from seven cycles in the previous Xeon v4 generation down to four cycles. This reduction benefits serial modes of AES operation, such as Cipher Block Chaining (CBC) encrypt. As with most new Intel® microarchitectures introduced, improvements in the core design manifest into appreciable performance gains. For optimized implementations of AES GCM, the parallel paths of the AESENC and PCLMULQDQ instructions have improved to the point where the authentication path is almost free.
SHA
Moving from Intel AVX2 to Intel AVX-512 implementations of the SHA family brings benefits beyond the doubling of data buffers that can be processed at once. Two key additions are the expansion of registers available from the 16 256-bit YMMs in Intel AVX2 to the 32 512-bit ZMMs in Intel AVX-512 and the more powerful instructions in Intel AVX-512. With more registers available, the message schedule portion of SHA can be stored in registers and no longer has to be saved on the stack. With more powerful instructions, the number of instructions that need to be executed is reduced and the dependencies are eliminated.
A closer examination of the power of the VPTERNLOG instruction can be illustrated on the SHA-256 Ch and Maj functions. Table 1 shows the Ch and Maj functions along with the Boolean logic table.
Table 1. SHA-256 Ch and Maj function logic tables.
| Ch (e, f, g) = (e & f) ^ (~e & g) |
Maj (a, b, c) = (a & b) ^ (a & c) ^ (b & c) |
||||||
| e |
f |
g |
Result (0xCA) |
a |
b |
c |
Result (0xE8) |
| 0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 0 |
0 |
1 |
1 |
0 |
0 |
1 |
0 |
| 0 |
1 |
0 |
0 |
0 |
1 |
0 |
0 |
| 0 |
1 |
1 |
1 |
0 |
1 |
1 |
1 |
| 1 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
| 1 |
0 |
1 |
0 |
1 |
0 |
1 |
1 |
| 1 |
1 |
0 |
1 |
1 |
1 |
0 |
1 |
| 1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
The VPTERNLOG instruction takes three operands and an immediate specifying of the Boolean logic function to execute. Tables 2 and 3 compare the Intel AVX2 and Intel AVX-512 instruction sequences for the SHA-256 Ch and Maj functions. Note that register to register copies are generally free in the microarchitecture.
Table 2. Intel® AVX2 and Intel® AVX-512 instruction sequence for the SHA-256 Ch function.
| Ch (e, f, g) = (e & f) ^ (~e & g) Note this is equivalent to ((f ^ g) & e) ^ g) |
|
| Intel® AVX2 |
Intel® AVX-512 |
| vpxor ch, f, g vpand ch, ch, e vpxor ch, ch, g | vmovdqa32 ch, e vpternlogd ch, f, g, 0xCA |
Table 3. Intel® AVX2 and Intel® AVX-512 instruction sequence for the SHA-256 Maj function.
| Maj (a, b, c) = (a & b) ^ (a & c) ^ (b & c) Note this is equivalent to ((a ^ c) & b) | (a & c) |
|
| Intel® AVX2 |
Intel® AVX-512 |
| vpxor maj, a, c vpand maj, maj, b vpand tmp, a, c vpor maj, maj, tmp | vmovdqa32 maj, a vpternlogd maj, b, c, 0xE8 |
Performance Gains
Cryptographic performance of Intel Xeon Scalable Processors shows per core gains of 1.181X to over 3X compared to the previous Xeon v4 Processors. The performance of some of the most commonly used cryptographic algorithms in secure networking and storage are highlighted using two popular open source libraries, OpenSSL*4 and the Intel® Intelligent Storage Acceleration Library (Intel® ISA-L)5.
Methodology
In order to maximize reproducibility and be able to project performance to different frequency and core count processors, the results are reported in cycles/byte (lower is better). The platforms are tuned for performance and turbo mode is disabled to allow for consistent core frequency for every run. To get throughput numbers in bytes per second for a specific processor, divide the processor’s frequency by the cycles/byte value reported. For total system performance multiply that value by the number of cores as these performance results have a nice linear scale.
The processors used for these performance tests are the Intel® Xeon® Gold 6152 processor and Intel Xeon processor E5-2695 v4, each with 16 GB of memory and running Ubuntu* 16.04.1.
OpenSSL*
Results shown in Table 4 are collected from the OpenSSL v1.1.0f speed application on 8 KB buffers using the following commands:
openssl speed -mr -evp aes-128-cbc
openssl speed -mr -evp aes-128-gcm
Table 4. OpenSSLU speed results for AES CBC Encrypt and AES GCM (cycles/byte).
| Algorithm | Xeon V4 |
Xeon Scalable |
Xeon Scalable Gain |
| AES-128-CBC Encrypt | 4.44 |
2.64 |
1.68 |
| AES-128-GCM | 0.77 |
0.65 |
1.18 |
Intel® ISA-L
Results shown in Table 5 are collected from the Intel ISA-L crypto version v2.19.0 cold cache performance tests using the following commands:
make perfs
make perf
Table 5. Intel® ISA-L performance test results for SHA Multibuffer (cycles/byte).
| Algorithm | Xeon V4 |
Xeon Scalable |
Xeon Scalable Gain |
| SHA-1 | 1.13 |
0.44 |
2.55 |
| SHA-256 | 2.60 |
0.87 |
2.97 |
| SHA-512 | 3.24 |
1.07 |
3.03 |
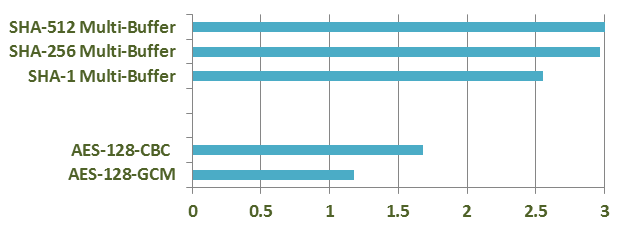
Figure 1. Single core Xeon Scalable Processor performance gain over previous generation Xeon v4.
Conclusion
The new Intel Xeon Scalable processors continue the tradition of lowering the computational burden of cryptographic algorithms. By incorporating the open source optimized cryptographic software libraries profiled in this paper, your application will take advantage of the best performance from the latest processor features.
Acknowledgements
We thank Jim Guilford, Ilya Albrekht, and Greg Tucker for their contributions to the optimized code. We also thank Jon Strang for preparing the Intel Xeon platforms in the performance tests.
References
1. “Federal Information Processing Standards Publication 197 Advanced Encryption Standard” http://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.197.pdf
2. “6WIND Boosts IPsec with Intel Xeon Scalable Processors” http://www.6wind.com/wp-content/uploads/2017/07/6WIND-Purley-Solution-Brief.pdf
3. “Federal Information Processing Standards Publication 180-4 Secure Hash Standard” http://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.180-4.pdf
4. OpenSSL https://github.com/openssl/openssl
5. Intel Intelligent Storage Acceleration Library Crypto Version https://github.com/01org/isa-l_crypto
1 – Performance claims based on measured data and methodology outline in the “Performance Gains” section of this document