By Angéla Czirkos

Introduction
The ATLAS Experiment* offline software is responsible for simulating, triggering, and processing the data needed to analyze the proton-proton collisions in the center of the ATLAS detector, produced by the Large Hadron Collider (LHC). The analysis of this data is achieved through the correct scheduling and execution of hundreds of algorithms, each responsible for a well-defined step of the data processing.
The ATLAS algorithmic code has been implemented using standard C++ to target classical CPUs; however, now with the ever-increasing computing power coming from non-CPU resources, the ATLAS software must be updated to be able to target new resources.
This project contributed to the R&D work involved in these developments and to measuring the performance of the Acts code†. The Acts code is used by the Athena framework†† to offload part of the calculations to accelerators using the oneAPI SYCL*-based Data Parallel C++ (DPC++) programming interface.
About oneAPI and DPC++
I joined ATLAS’s core software experts to experiment with using oneAPI to offload certain calculations from the Athena framework to Intel and NVIDIA* accelerators. My responsibilities included contributing to the research and development work and measuring the performance of Athena jobs that offload part of its calculations to accelerators using the SYCL/oneAPI/DPC++ programming interface.
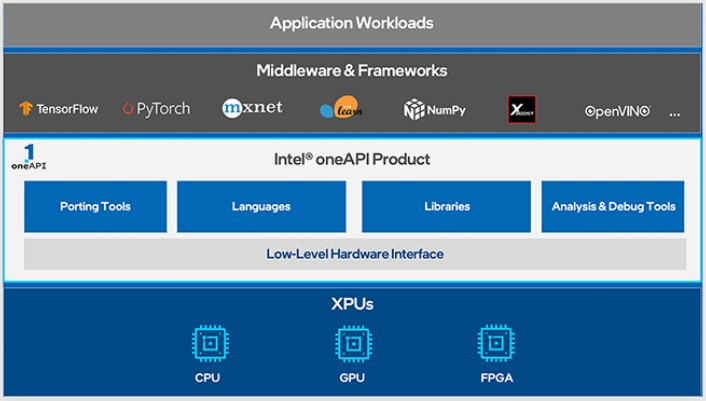
Figure 1. oneAPI Toolkit Overview
The Intel® DPC++/C++ Compiler is part of the oneAPI toolkits from Intel. Within the toolkits, there are also AI and data analytics solutions, powerful libraries, and analysis and debugging tools. The products enable the targeting of diverse architectures: CPUs, GPUs, and FPGAs. With a unified API, developers have an easier job maintaining code. Combined with powerful libraries and language features, efficiency can be highly improved and space for innovation can be made.
Process
To expand further, let’s explore the use of cross-architecture backends, focusing on ATLAS offline software. The seed-finding algorithm of the track-reconstruction software was implemented in DPC++ to offload computations to GPUs. The code successfully ran on diverse architectures, and measurements indicate that it can provide a performance boost compared to the CPU version of the algorithm.
The data of a detector readout is stored in raw format. This raw data is then processed, clusters are formed, and a 3D hit position is then assigned to each.
These hits are also referred to as space points. Hits from the pixel and strip detectors are used to generate seeds. Seeds are formed of three space points, which allow for a crude identification of a particle. These three points correspond to a helix, which is the path of a charged particle in a uniform magnetic field.
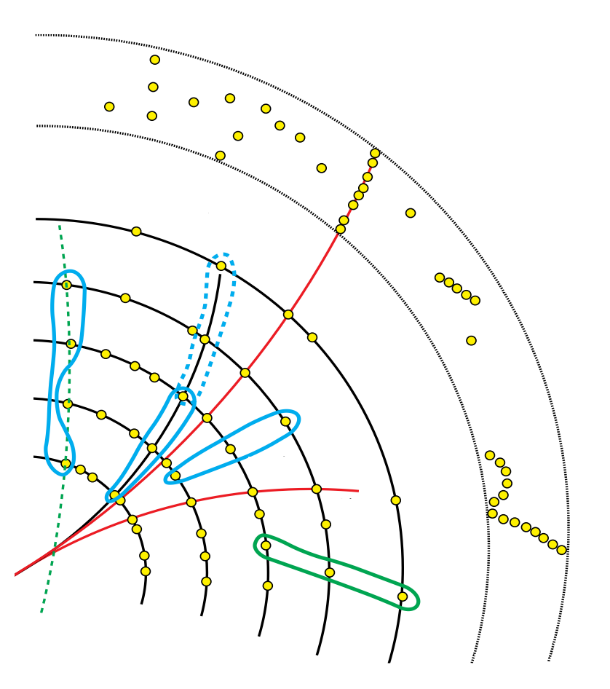
Figure 2. Seed and track information of detector hits
Image courtesy of: Czirkos, A 2020 ‘Intel® oneAPI Integration Tests with the ATLAS Offline Software’, CERN openlab summer intern project presentations, slide 3
Seed generation is limited by many factors. Effects, such as multiple scattering and impact parameter limitations, need to be considered.
Seeding starts with duplet formation of two space points, which are then connected to form triplets if they have a common middle space point and fulfill some other criteria. After some final filtering of the seed candidates found, they are forwarded for use in later parts of the tracking algorithm.
We investigated how seeding could be implemented as a parallel algorithm, potentially increasing performance. What makes seeding a good candidate for parallelization is the independent nature of duplet and triplet formation.
Results So Far
The complete seeding algorithm was implemented in DPC++, which was successfully merged into the Acts GitHub* repository. The seeding algorithm is based on the SYCL 1.2.1. specification, and extensions from DPC++, such as the Unified Memory Model, were used. The code can be compiled with the Intel® oneAPI DPC++/C++ Compiler.
The following describes the experimental setup of the machine through which the performance of the CPU algorithm was compared to the GPU algorithm based on DPC++.
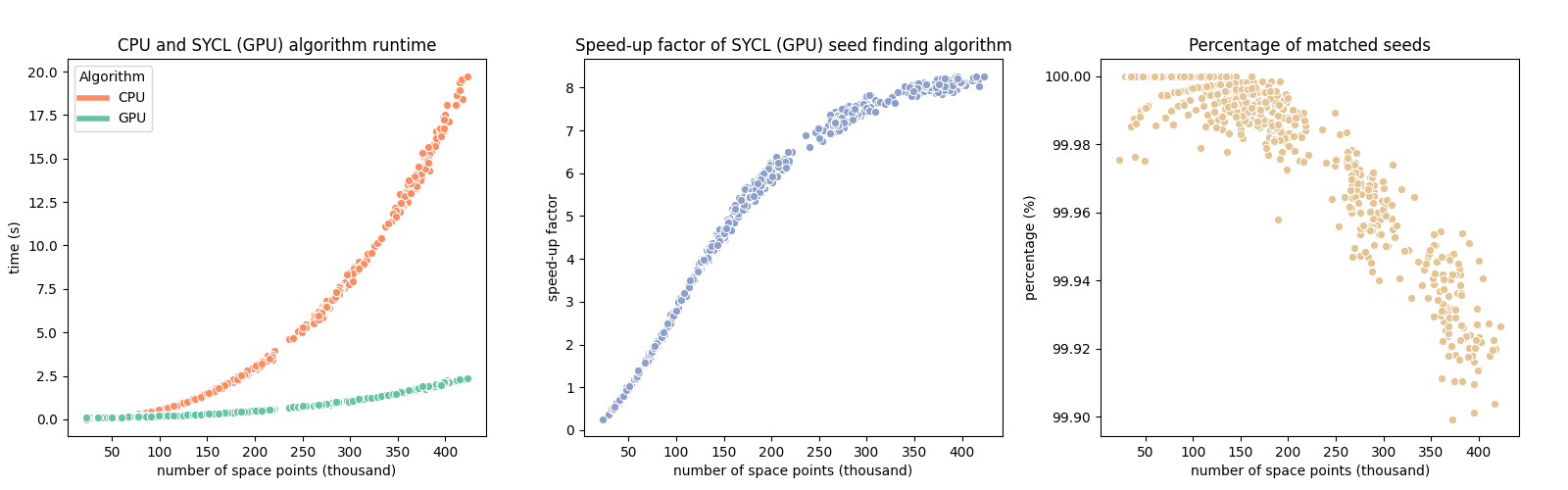
Figure 3. Performance metrics of SYCL-based seed-finding algorithm on our experimental setup
Image courtesy of: Czirkos, A 2020 ‘Intel® oneAPI Integration Tests with the ATLAS Offline Software’, CERN openlab summer intern project presentations, slide 3
Experimental setup:
- CPU: Intel® Core™ i9-9900K processor (16 MB cache, up to 5.00 GHz)
- GPU: NVIDIA* GeForce RTX 2060, 6 GB GDDR6
In Figure 3, three plots describe absolute and relative runtime and speed-up, as well as the agreement of the new algorithm compared to the CPU version. According to these metrics, precision remains high (above 99.9%), even for the high-complexity events. On samples with more than 50,000 space points (approximately), the GPU algorithm achieves better performance on the experimental setup, which can be read from the middle plot.
Other Results
One of the main advantages of Intel’s DPC++ implementation of SYCL is its support for diverse architectures. The SYCL version of the seed-finding algorithm was tested and run successfully on several architectures. These architectures included Intel® Core™ i9-9900K processor with Intel® Graphics Technology, Intel® Iris® Xe MAX graphics, and used on the Intel® DevCloud for oneAPI as well as NVIDIA Turing and Pascal GPU architectures using an open source compiler back end that uses CUDA. These tests confirm that SYCL is indeed successful in using heterogeneous back ends.
Furthermore, the project contributed to the development of the DPC++ compiler by filing reports about bugs and defects we found during development. Additional development possibilities were discussed with Codeplay Software*, who are one of the core supporters of the SYCL specification and who maintain the ComputeCpp implementation.
Conclusion
A complete and close-to-optimal version of the seed-finding algorithm was implemented in SYCL/DPC++. The code was compiled and run on several architectures, which proves the flexibility of SYCL. Performance measurements show that the new algorithm is effective and can provide a performance boost, especially for high-intensity events.
One of the directions for future developments is to implement more algorithms in SYCL, possibly starting from the local reconstruction steps. This development would help limit memory movement between device and host, which is often the bottleneck with lower intensity events.
Additional Resources
††Atlas Athena Project on GitLab
Project Details and Final Presentation
About Angéla Czirkos
Angéla studies computer science at Eötvös Loránd University and was a CERN openlab 2020 online summer intern. She recently joined the team working on the Compact Muon Solenoid (CMS) experiment.