Introduction
A virtual machine (VM) is a compute resource that uses software instead of a physical computer to run programs and deploy apps. One or more virtual “guest” machines run on a physical “host” machine. Chromebooks support Android OS, Windows OS, and Linux OS as virtual machines in ChromeOS. These deployments are sandboxed and hence provide additional security for applications running in ChromeOS. Crosvm is the ChromeOS virtual machine manager written from the ground-up to run lightweight, secure, and performant VMs.
In a virtualized environment, the performance of workloads is comparatively lower than the native performance. In the above VM environment, the average performance gap was between 5% and 20% on various workloads compared to native. One of the areas we looked at for improving the performance and reducing the native gap is reducing the number of VM exit calls that have significant CPU overhead. In Android and Crostini VM, VM exits are significantly higher for HLT/Timer and IPI (MSR) events. In the case of HLT, in addition to VM exit overhead, context switching and expensive wakeup IPI interrupts contribute to the performance degradation.
In this work, we have supported KVM halt polling and guest halt polling optimizations, such as configured optimal polling values and interval, to reduce the VM exits due to HLT, which in turn improves the performance by saving (reducing) CPU cycles that are caused by VM overhead.
The results show that our implementation has achieved the following:
- Improved performance for Android and Crostini VM workloads by 2% to 5%
- Reduced context switches for Android workloads an average of 18% by using KVM halt polling optimization
- Improved performance by 7% to 10% for Android storage and productivity workloads, with an average 10% reduction in VM exits due to HLT
- Reduced cycles per second by 19% for all workloads using guest halt polling technique
- Reduced power usage by 10%, which should improve battery life
The overall VM performance gap with native was reduced by 2%-4% with the above optimizations.
Motivation
Background – VM exits [1]
Processor support for virtualization is provided by a form of processor operation called VMX operation. There are two kinds of VMX transitions. Transitions into VMX non-root operation are called VM entries. Transitions from VMX non-root operation to VMX root operation are called VM exits. Processor behavior in VMX root operation is much like normal CPU operation. Processor behavior in VMX non-root operation is restricted and modified to facilitate virtualization. Instead of their ordinary operation, certain instructions (including the new VMCALL instruction) and events introduces VM exits to the VMM. Because these VM exits replace ordinary behavior, the functionality of software in VMX non-root operation is limited.
VM exits in response to certain instructions and events (e.g., page fault) are a key source of performance degradation in a virtualized system. Refer to Figure 1 below.

A VM exit marks the point at which a transition is made between the VM currently running and the VMM (hypervisor) that must exercise system control for a particular reason. In general, the processor must save a snapshot of the VM's state as it was running at the time of the exit. Kernel-based virtual machine (KVM) is a virtualization module in the Linux kernel that allows the kernel to function as a hypervisor. For Intel® architectures, here are the steps to save a snapshot (refer to Figure 2 for an illustration of the steps).
- Record information about the cause of the VM exit in the VM-exit information fields (exit reason, exit qualification, and guest address), and update VM-entry control fields.
- Save processor state in the guest state area. This includes control registers, debug registers, machine specific registers (MSRs), segment registers, descriptor-table registers, RIP, RSP, and RFLAGS, as well as non-register states, such as pending debug exceptions.
- Save MSRs in the VM-exit MSR-store area. They are used to control and report on processor performance.
- Load the processor state based on the host-state area and some VM-exit controls.
- This includes host control registers, debug registers, MSRs, host table and descriptor-table registers, RIP, RSP, RFLAGS, page-directory pointer table entries, as well as non-register states.
- Load MSRs from the VM-exit MSR-load area.
After the VMM has performed its system management function, a corresponding VM entry will be performed that transitions processor control from the VMM to the VM. Repeat the above steps in reverse order. Now you can see why VM exits generate considerable overhead, to the tune of hundreds or thousands of cycles for a single transition.
To mitigate this problem, considerable effort has gone into:
- reducing the number of cycles required by a single transition, and
- identifying options to reduce VM exits.
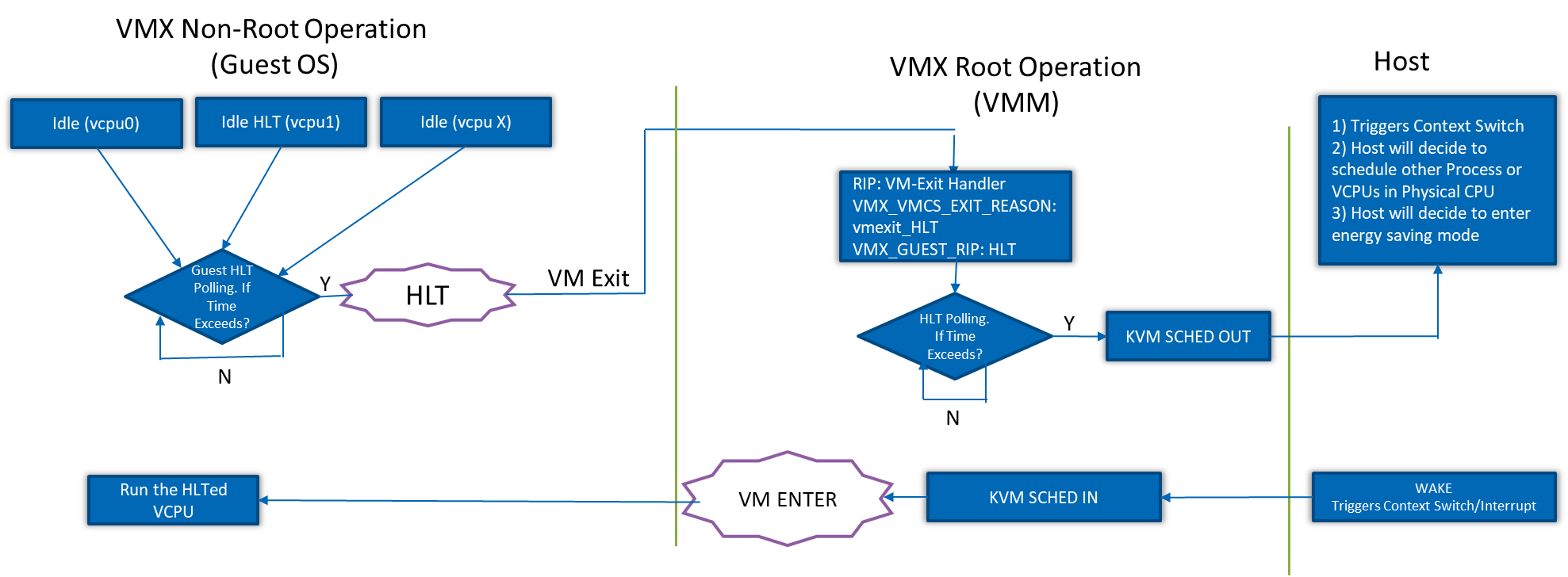
VM exit HLT [2]
One or more virtual central processing units (vCPUs) are assigned to every virtual machine (VM). The threads inside the VM are assigned to the vCPUs and then they are processed. vCPU threads are scheduled on physical CPUs. The physical CPU goes into sleep states when it is not active. When a vCPU has no threads to process and is in idle state, the guest OS sends a request to halt the vCPU. When the vCPU is halted, there will be a switching from the VM to the VMM. Subsequently, the VMM would schedule out the vCPU and run another vCPU thread on the physical CPU in which the halted vCPU thread was running. Processors support advanced programmable interrupt controller virtualization (APICv) that enables the system to introduce interrupts in the VM without causing switching between VM and VMM for MSR writes to the interrupt command register (ICR). If a wakeup interrupt is generated for a halted vCPU, the VMM needs to stop the other vCPU thread running on the physical CPU. This introduces a switch between VM and VMM to run the halted vCPU to process the interrupt. Switching between the VMM and the host, additional context switching, and expensive wakeup IPI interrupts when crossing sockets are expensive. Physical CPU idle and vCPU idle have a significant performance difference. Frequent sleeps and wakeups cause high scheduling overhead and switching between VM and VMM that, in turn, negatively impact performance.
Approach
Fulfilling each root request as it comes would be very expensive, and hence the VM exits polling mechanism is available. There are two ways to minimize overhead due to a VM exit HLT event: KVM halt polling technique, and guest halt polling technique.
KVM halt polling technique [3]
With the KVM halt polling technique, when an HLT VM exit is triggered in the guest, the VMM may poll the vCPU for a time and wait for an interrupt for vCPU to arrive instead of scheduling the vCPU. The pCPU triggers a context switch. This polling time is pre-set. Our work here is to determine the optimal value for KVM polling parameters that provide significant performance for VM workloads and power savings. Refer to Figure 3 below.
The KVM module has four tunable module parameters (halt_poll_ns, halt_poll_ns_grow, halt_poll_ns_grow_start, and halt_poll_ns_shrink) to adjust the global max polling interval as well as the rate at which the polling interval is grown and shrunk. These module parameters can be set from the debugfs files in: /sys/module/kvm/parameters/. Based on the behavior of VM workloads, we had determined the optimal values for tunable parameters and the results obtained are shown in the Results section.
Guest halt polling technique [4]
As shown in Figure 3, guest halt polling technique implements polling in the guest even before control is handed over to the VMM. The guest idle halt polling parameter enables the vCPU to wait for a period (i.e., polling) when it is idle, delaying the execution of HLT instructions. If the business process on the vCPU is woken up during the short waiting time, subsequent scheduling is not required. The technique guarantees performance with a small marginal cost. At the same time, the technique uses an adaptive algorithm. This ensures that the additional cost generates effective benefits (performance improvement), so that guest idle halt polling can not only solve the performance problems of special scenarios, but also ensure that performance recovery will not occur in general scenarios. guest_halt_poll_ns is a hard limit of the guest idle halt polling technique. We recommend configuring the interval time reasonably according to the frequency of workload sleep and wake-up. The five parameters guest_halt_poll_ns, guest_halt_poll_allow_shrink, guest_halt_poll_grow, guest_halt_poll_shrink, and guest_halt_poll_grow_start are used to adjust the adaptive algorithm. These five parameters are optimally tuned for Android and Crostini (Linux VM) workloads to obtain significant performance and power savings by reducing VM exits due to HLT events.
Results
Our evaluation platform is an Asus Chromebook. It uses an 11th Gen Intel® Core i7-1165G7 @ 2.80GHz processor with 8 cores. The processor base frequency is 2.8 GHz and can reach up to 4.7 GHz in Turbo mode. The memory available in the device is 16 GB. ChromeOS version R93 with Android R is loaded on the device. We have ensured that Internet Speed Test is executed before collecting the data to confirm the internet bandwidth is the same while executing the tests. The apps are side loaded to the system and tests are applied. For all performance and power assessment, a median of three iterations is used with variance removed.
In our first-level analysis, we studied the behavior with default polling values. Refer to the graph below.
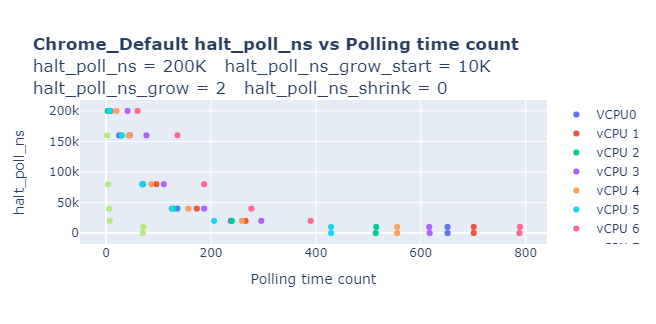
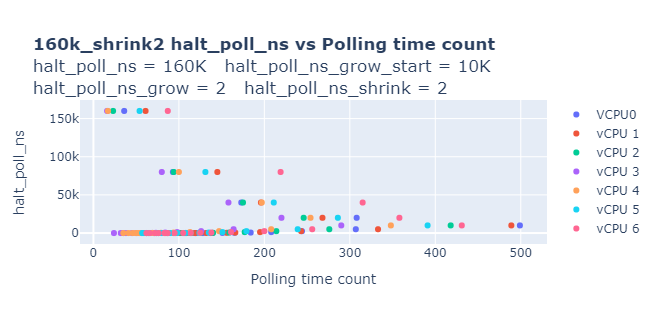
Refer to Graph 1 and observe that for 200000 ns, it was polled for a very minimal count and the maximum number of counts are polled for 0ns. We decided to reduce the maximum poll time to 160000ns and modified halt_poll_ns_shrink value to 2 (to reduce polling for 0ns).
In the kernel code, we also limited the polling time not to go below 10000ns. With these changes, we got significant performance gains as shown below:
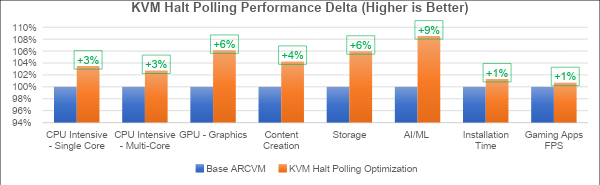
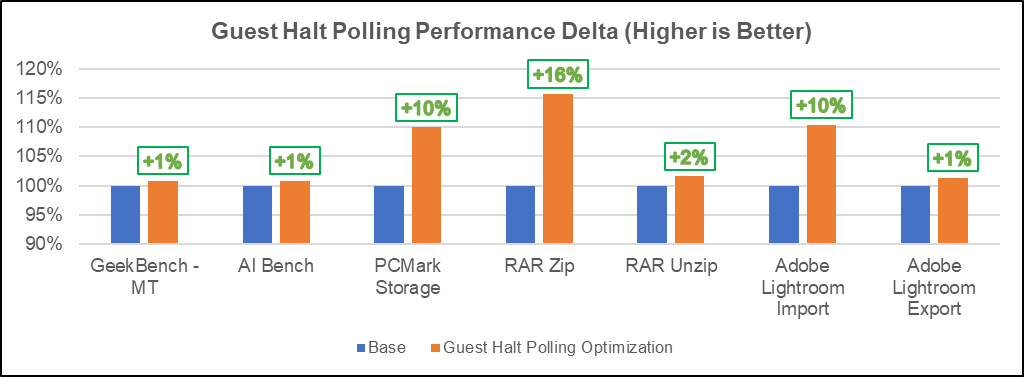
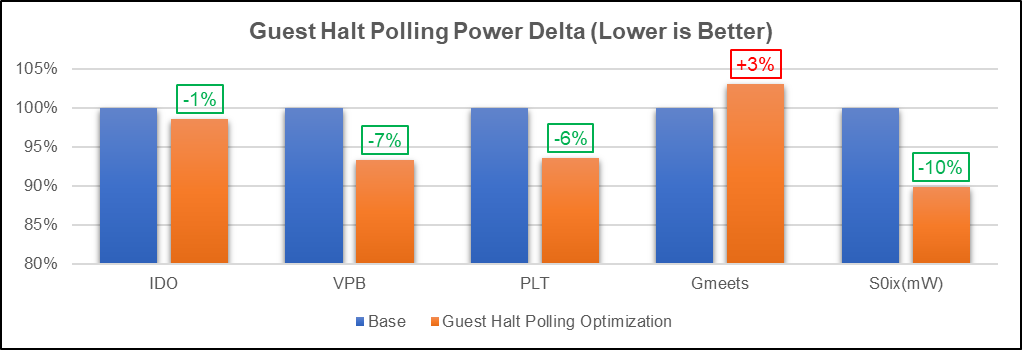
A similar exercise has been carried out using the guest halt polling technique and the performance and power results are shown below:
Summary
In this paper, we outlined the VM performance gap compared to native and overheads due to VM exits. In addition, we conducted experiments in KVM halt polling and guest halt polling optimizations, and their performance and power impact on workloads executed in VM on ChromeOS. Our implementation has achieved a 2% to 5% performance improvement for Android and Crostini VM Workloads and an average 18% reduction in context switches for Android workloads using KVM halt polling optimization. Our implementation achieved a 7% to 10% performance improvement for Android storage and productivity workloads, with an average 10% reduction in VM exits due to HLT, and a 19% reduction in cycles per second for all workloads using guest halt polling technique. An average 10% power savings is also observed that would improve battery life. The overall VM performance gap with native was reduced by 2% to 4% with the above optimizations. These optimizations were accepted by Google and merged in ChromeOS. Subsequent work in this area is to build a software/hardware logic to determine the polling time dynamically by studying the characteristics of the workload and reducing Gmeet power delta. Also, these techniques can be used in different VM environments in current and future generations of platforms for performance gains/power savings.
About the authors
This article was written by Jaishankar Rajendran, Prashant Kodali, and Biboshan Banerjee.
Jaishankar Rajendran and Prashant Kodali is a member of the CCG CPE Chrome and Linux Architecture Department, and Biboshan Banerjee is a member of the Android Ecosystem Engineering Department
Thanks to Sangle Parshuram, Sonecha Ruchita, Shyjumon N, Sajal K Das, Erin Park, Mahendra K Reddy, and Vaibhav Shankar for their support and guidance in reviewing this article.
Notices and disclaimers
Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Consult other sources of information to evaluate performance as you consider your purchase. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
© 2021 Intel Corporation. Intel, the Intel logo, Intel Core, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Test configuration
Software: Android 11.0, OpenGL ES 3.1 Mesa Support
Hardware: Asus Chromebook, Intel® Core™ i7-1165G7 processor, 4 Core 8 Threads, 16 GB Ram
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at www.intel.com.