Abstract
Hyperscan, an advanced regular expression matching library, is suitable to apply to network solutions such as deep packet inspection (DPI), Intrusion Prevention System (IPS), intrusion detection software (IDS), and next-generation firewall (NGFW).
Snort* is one of the most widely used open source IDS/IPS products, the core part of which involves a large amount of literal and regular expression matching work. This article describes the integration of Hyperscan to Snort to improve its overall performance. The integration code is available under Downloads at 01.org's Hyperscan site.
Snort* Introduction
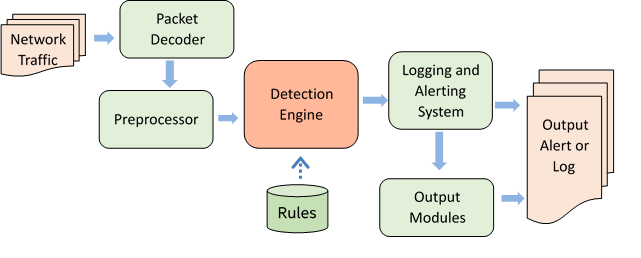
Figure 1: The Architecture of Snort*.
As shown in Figure 1, Snort has five major parts. The packet decoder is responsible for receiving packets from different network interfaces and conducting initial analysis of packets. The preprocessor is a plug-in for further processing of the decoded packets. Its functions include HTTP URI normalization, packet defragmentation, TCP flow reassembly, and so on. The core of Snort is the detection engine, which can match the packets according to the configured rules. Rule matching is critical to the overall performance of Snort*. Once matching is successful, it notifies the logging and alerting system based on the behavior defined in the rules. Then the system will output the alert or log accordingly. Users can also define the output module to save alerts or logs in a specific form, such as a database or XML file.
Integration of Hyperscan
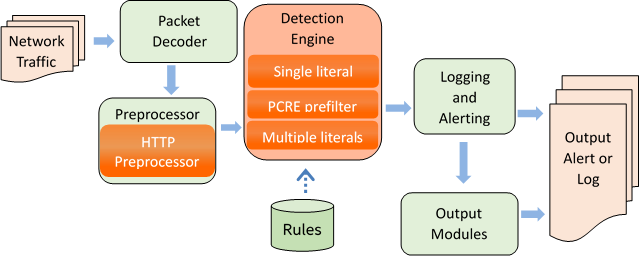
Figure 2: Hyperscan and Snort* Integration.
As shown in Figure 2, Hyperscan and Snort integration focuses on four aspects:
Literal Matching
Users define the matching of specific literals in rules, and Snort searches the packets, using the Boyer-Moore algorithm to match literals. We replaced this algorithm with Hyperscan to improve its matching performance.
PCRE Matching
Snort uses Perl compatible regular expressions (PCRE) as its regular expression matching engine. Hyperscan is compatible with PCRE rules, but it does not support a few backtracking and assertion syntaxes. However, Hyperscan itself comes with a PCRE preprocessing function (PCRE prefiltering). It can be made compatible with Hyperscan by transforming the PCRE rules. The matching produced by the actual rules is a subset of the matching generated by the transformed rules; therefore, you can use Hyperscan as a prefilter. If it doesn't produce matches, the actual rules will not generate any matches either. If there is a match, you can use PCRE scan to confirm whether there is a real match. Because the overall performance of Hyperscan is higher than PCRE, the prefiltering of Hyperscan can avoid the excessive time cost of PCRE matching.
Multiple Literal Matching
Another important matching process in Snort is the matching of multiple literals. Multiple literal matching can filter out rules that are not possible to match to reduce the number of rules to check individually in detail, therefore improving overall matching performance. Snort uses the Aho-Corasick algorithm for multiple literal matching. We replaced this algorithm with Hyperscan and improved the performance significantly.
HTTP Preprocessing
In addition to the integration of matching algorithms for the detection engine, Hyperscan is also applied in the preprocessor. When doing HTTP preprocessing, we use Hyperscan to search keywords to further accelerate the preprocessing.
Performance
| Snort Version | 2.9.8.2 |
| Hyperscan Version | 4.3.1 |
| Snort Ruleset | Snortrules-snapshot-2983 |
Table 1: Snort and Hyperscan software setup.
Our performance testing was done on Snort 2.9.8.2 and Hyperscan 4.3.1, as shown in Table 1 with the default Snort ruleset Snortrules-snapshot-2983, which has 8863 rules. HTTP enterprise traffic is sent from an IXIA* traffic generator to Snort during testing. Figure 3 shows the single core, single-thread performance comparison between the original Snort and the Hyperscan accelerated Snort on Intel Xeon® processor E5-2658 v4 @ 2.30GHz. We can see that Hyperscan improves the matching performance of Snort greatly. The overall performance is about six times higher than that of the original Snort.
We compared the memory footprint of the original Snort and the Snort optimized by Hyperscan. The original Snort has to convert all the rules into a Trie structure for the Aho-Corasick algorithm, and this takes up a lot of memory. Hyperscan has its own optimized matching engine, which greatly reduces memory consumption during the matching process. As shown in Figure 4, in this test the overall memory footprint of the original Snort is more than 12 times larger than that of Snort optimized by Hyperscan.
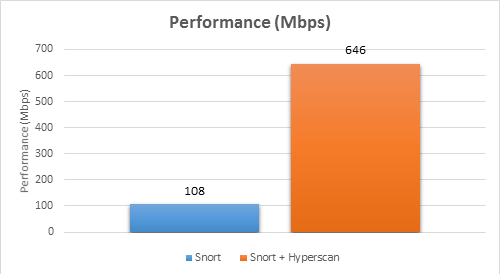
Figure 3: Performance comparison between original Snort and Hyperscan integrated Snort.
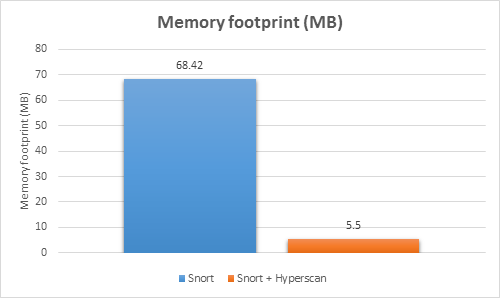
Figure 4: Memory consumption comparison between original Snort* and Hyperscan integrated Snort.
Conclusion
Hyperscan-integrated Snort is much better than the original Snort in both overall performance and memory footprint. Hyperscan has shown its powerful ability of large-scale rule matching, which makes it very suitable for products based on rule matching, such as DPI/IDS/IPS/NGFW.
About the Author
Xiang Wang is a software engineer working on Hyperscan at Intel. His major areas of focus include automata theory and regular expression matching. He works on a pattern matching engine optimized by Intel architecture that is at the core of DPI, IDS, IPS, and firewalls in the network security domain.