Introduction Series for Intel® Software Optimization for Chainer*
Vol 1: Getting Started - Introduces installation instructions of Intel® Software Optimization for Chainer* and getting started guide.
Vol 2: Performance considerations - Introduces hardware and software configuration to fully utilize CPU computation resources with Intel Software Optimization for Chainer.
Vol 3: Performance number [In Progress] - Introduces performance number of Intel Software Optimization for Chainer.
To fully utilize the power of Intel® architecture and thus yield high performance, Chainer* can be powered by Intel’s highly optimized math routines for deep learning tasks. The Chainer Backend for Intel architecture is a Chainer module providing NumPy-like API and deep neural network acceleration using Intel® Deep Neural Network Library (Intel® DNNL).
To setup Intel® Software Optimization for Chainer* on your system, see Volume 1 in this series which includes an installation guide.
Maximum Throughput vs. Real-time Inference
Deep learning inference can be done with two different strategies, each with different performance measurements and recommendations. The first is Max Throughput (MxT) and aims to process as many images per second, passing in batches of size larger than 1. For Max Throughput, best performance is achieved by exercising all the physical cores on a socket. This solution is intuitive in that we simply load up the CPU with as much work as we can and process as many images as we can in a parallel and vectorized fashion. Real-time Inference (RTI) is an altogether different regime where we typically want to process a single image as fast as possible. Here we aim to avoid penalties from excessive thread launching and orchestration between concurrent processes. The strategy is to confine and execute quickly. The following best known methods (BKMs) differ where noted with MxT RTI.
Hardware/BIOS Configuration
- BIOS configurations
- Intel® Xeon® processor
- Turbo Boost Technology: on
- Hyper-treading (HT): off
- NUMA: off
- Intel® Xeon Phi™ processor
- Turbo Boost Technology: on
- Hyper-treading (HT): on
- NUMA: off
- Memory mode: cache
- Intel® Xeon® Scalable processors (formerly SkyLake)
- Turbo Boost Technology: on
- Hyper-treading (HT): on
- NUMA: on
- Intel® Xeon® processor
- Optimize hardware in BIOS: set CPU max frequency, set 100% fan speed, check cooling system.
Software Configuration
- It is recommended to use Linux* CentOS* 7.2 or newer for Intel Software Optimization for Chainer.
- Make sure that there are no unnecessary processes during training and scoring. Intel Software Optimization for Chainer is using all available resources and other processes (like monitoring tools, java processes, network traffic etc.) might impact performance.
- Please clean up cache to make the test result stable before each test.
sudo sh -c 'sync; echo 3 > /proc/sys/vm/drop_caches'
Non-Uniform Memory Access (NUMA) Controls Affecting Performance
Recommended settings ? --cpunodebind=0 --membind=0
Usage (shell)
numactl --cpunodebind=0 --membind=0 pythonRunning on a NUMA-enabled machine brings with it special considerations. NUMA is a memory layout design used in data center machines meant to take advantage of locality of memory in multi-socket machines with multiple memory controllers and blocks. In most cases, inference runs best when confining both the execution and memory usage to a single NUMA node.
Concurrent Execution
You can optimize performance by breaking up your workload into multiple data shards and then running concurrently on more than one NUMA node. On each node (N), run the following command:
Usage (shell)
numactl --cpunodebind=N --membind=N pythonFor example, you can use the & command to launch simultaneous processes on multiple NUMA nodes:
numactl --cpunodebind=0 --membind=0 python & numactl --cpunodebind=1 --membind=1 pythonIntel® DNNL Technical Performance Considerations
Intel® DNNL Technical Summary: The library takes advantage of Single Instruction Multiple Data (SIMD) instructions through vectorization, as well as multiple cores through multi-threading. The technique of vectorization effectively utilizes cache and computation ability of modern CPUs, and the effectiveness of instruction sets. A single calculation could process up to 16 single-precision numbers (512-bit long). Meanwhile, up to two multiply and add (Fused Multiply Add, FMA) operations can be finished in a single cycle. Moreover, the technique of multi-threading helps in performing multiple independent operations simultaneously. Since computation of deep learning tasks is often best served by avoiding sequential execution, getting available cores working in parallel is the obvious choice to speed up deep learning tasks. Intel® DNNL utilizes OpenMP* to leverage Intel® architecture.
To ensure robustness, Intel developed a number of optimized deep learning primitives in Intel® DNNL. In addition to matrix multiplication and convolution, the following building blocks are implemented for vectorization-friendly data layout:
- Direct batched convolution
- Inner product
- Pooling: maximum, minimum, average
- Normalization: local response normalization across channels (LRN), batch normalization
- Activation: rectified linear unit (ReLU)
- Data manipulation: multi-dimensional transposition (conversion), concat, sum and scale
Intel® DNNL utilizes the following environment variables for vectorization and multi-threading. Thus, changing values of these environment variables affects performance of the framework. These environment variables will be described in detail in the following sections. We highly recommend users tuning these values for their specific neural network model and platform.
- KMP_AFFINITY
- KMP_BLOCKTIME
- OMP_NUM_THREADS
- KMP_SETTINGS
KMP_AFFINITY
Recommended settings ? KMP_AFFINITY=granularity=fine,verbose,compact,1,0
usage (shell)
export KMP_AFFINITY=granularity=fine,compact,1,0
Intel® DNNL has the ability to bind OpenMP threads to physical processing units. KMP_AFFINITY is used to take advantage of this functionality. It restricts execution of certain threads to a subset of the physical processing units in a multiprocessor computer.
Usage of this environment variable is as below.
KMP_AFFINITY=[<modifier>,...]<type>[,<permute>][,<offset>]
Modifier is a string consisting of keyword and specifier. type is a string indicating the thread affinity to use. permute is a positive integer value, controls which levels are most significant when sorting the machine topology map. The value forces the mappings to make the specified number of most significant levels of the sort the least significant, and it inverts the order of significance. The root node of the tree is not considered a separate level for the sort operations. offset is a positive integer value, indicates the starting position for thread assignment. We will use the recommended setting of KMP_AFFINITY as an example to explain basic content of this environment variable.
KMP_AFFINITY=granularity=fine,verbose,compact,1,0
The modifier is granularity=fine,verbose. Fine causes each OpenMP thread to be bound to a single thread context. Verbose prints messages in runtime concerning the supported affinity, and this is optional. These messages include information about the number of packages, number of cores in each package, number of thread contexts for each core, and OpenMP thread bindings to physical thread contexts. Compact is value of type, assigning the OpenMP thread <n>+1 to a free thread context as close as possible to the thread context where the <n> OpenMP thread was placed.
NOTE The recommendation changes if Hyperthreading is disabled on your machine. In that case, the recommendation is:
KMP_AFFINITY=granularity=fine,verbose,compact if hyperthreading is disabled.
Fig. 1 shows the machine topology map when KMP_AFFINITY is set to these values. The OpenMP thread <n>+1 is bound to a thread context as close as possible to OpenMP thread <n>, but on a different core. Once each core has been assigned one OpenMP thread, the subsequent OpenMP threads are assigned to the available cores in the same order, but they are assigned on different thread contexts.
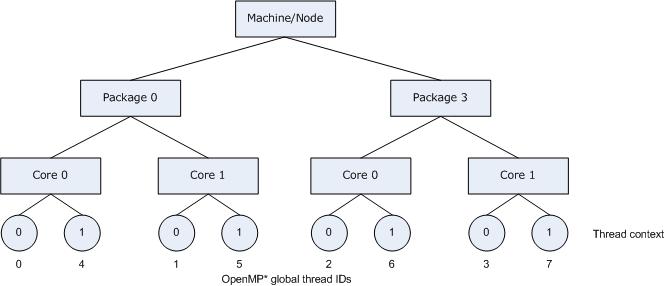
Figure 1. Machine topology map with setting KMP_AFFINITY=granularity=fine,compact,1,0
The advantage of this setting is that consecutive threads are bound close together, so that communication overhead, cache line invalidation overhead, and page thrashing are minimized. Suppose the application also had a number of parallel regions which did not utilize all of the available OpenMP threads, it is desirable to avoid binding multiple threads to the same core and leaving other cores not utilized.
For a more detailed description of KMP_AFFINITY, please refer to Intel® C++ Compiler developer guide.
KMP_BLOCKTIME
Recommended settings for CNN? KMP_BLOCKTIME=0
Recommended settings for non-CNN? KMP_BLOCKTIME=1 (user should verify empirically)
usage (shell)
export KMP_BLOCKTIME=0 (or 1)
This environment variable sets the time, in milliseconds, that a thread should wait, after completing the execution of a parallel region, before sleeping. The default value is 200ms.
After completing the execution of a parallel region, threads wait for new parallel work to become available. After a certain period of time has elapsed, they stop waiting and sleep. Sleeping allows the threads to be used, until more parallel work becomes available, by non-OpenMP threaded code that may execute between parallel regions, or by other applications. A small KMP_BLOCKTIME value may offer better overall performance if application contains non-OpenMP threaded code that executes between parallel regions. A larger KMP_BLOCKTIME value may be more appropriate if threads are to be reserved solely for use for OpenMP execution, but may penalize other concurrently-running OpenMP or threaded applications. It is suggested to be set to 0 for convolutional neural network (CNN) based models.
OMP_NUM_THREADS
Recommended settings for CNN? OMP_NUM_THREADS = num physical cores
Usage (shell)
export OMP_NUM_THREADS=num physical coresThis environment variable sets the maximum number of threads to use for OpenMP parallel regions if no other value is specified in the application.
The value can be a single integer, in which case it specifies the number of threads for all parallel regions. The value can also be a comma-separated list of integers, in which case each integer specifies the number of threads for a parallel region at a nesting level.
The first position in the list represents the outer-most parallel nesting level, the second position represents the next-inner parallel nesting level, and so on. At any level, the integer can be left out of the list. If the first integer in a list is left out, it implies the normal default value for threads is used at the outer-most level. If the integer is left out of any other level, the number of threads for that level is inherited from the previous level.
The default value is the number of logical processors visible to the operating system on which the program is executed. This value is recommended to be set to the number of physical cores.
KMP_SETTINGS
Usage (shell)
export KMP_SETTINGS=TRUEThis environment variable enables (TRUE) or disables (FALSE) the printing of OpenMP run-time library environment variables during program execution.
Examples
With Intel® Xeon Phi™ processor, we recommend the following configurations:
Boot with nohz_full=1-287 rcu_nocbs=1-287 to enable adaptive-ticks in kernel, for example boot with command linux16 /vmlinuz-3.10.0-514.el7.x86_64 root=/dev/mapper/cl-root ro crashkernel=auto rd.lvm.lv=cl/root rd.lvm.lv=cl/swap rhgb quiet LANG=en_US.UTF-8 nohz_full=1-287 rcu_nocbs=1-287 in grub.cfg
Run test with the following environments:
export KMP_HW_SUBSET=1T
export OMP_NUM_THREADS=72
export KMP_AFFINITY=granularity=fine,compactWith Intel® Xeon® Scalable processors (formerly SkyLake) , we recommend the following configurations:
Set CPU frequency:
sudo cpupower frequency-set -d 2.4G -u 3.7G -g performanceDisable numa balancing after reboot:
sudo echo 0 > /proc/sys/kernel/numa_balancingRun test with the following environments:
export KMP_HW_SUBSET=1T
export OMP_NUM_THREADS=56
export KMP_AFFINITY=granularity=fine,compactRun with numactl:
numactl -l python performance.py -a ${arch} -b ${batchsize} -i ${insize} -d ${datasize} -e ${epoch}