Considerations for Edge Inference Solutions
When building an edge inference platform, consider the following factors, especially to support IoT services that need low latency, local data processing, and local data storage:
- Operating systems that support real-time applications and management techniques such as support for containers.
- Ability to run image processing through an accelerator.
- Compute and storage resource optimization.
- Communications frameworks to allow edge systems to co-operate on control and data processing.
Hardware and Software Requirements
Edge requirements are driving more compact, powerful converged solutions.
| Hardware |
|
| Software |
|
Intel offers silicon platforms as well as tailored purpose-built platforms specifically for edge AI. The general purpose CPUs include Intel® Xeon processor, Intel® Core processor, and Intel® Atom processor.
- New second generation Intel® Xeon scalable processors have a built-in accelerator that can replace almost any kind of specific AI accelerator for any kind of AI algorithm including video analytics, speech, and natural language.
- New Intel® 11th generation core processors have DL boost and an embedded XE GPU architecture that gives extra optimization for AI in a low cost, general purpose platform expected with the core CPU.
- Intel® Movidius™ VPUs offer great performance efficiency at an optimal cost.

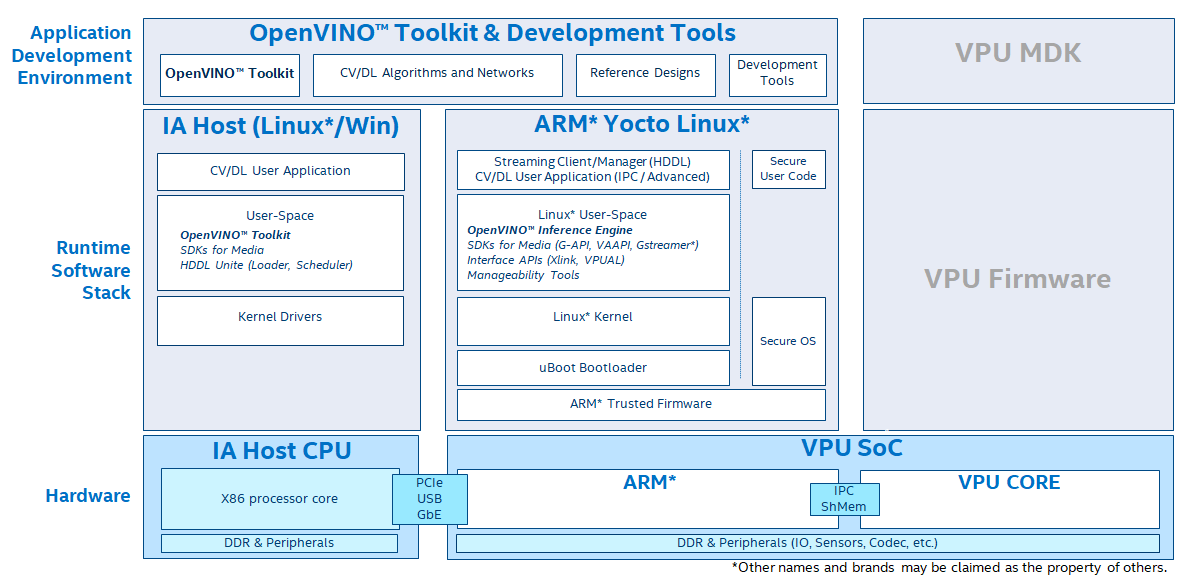
- Intel also utilizes OpenVINO™, a tool suite that allows the optimization and deployment of AI with much better performance. Using the OpenVINO™ toolkit to optimize your inference solution, you can upgrade your products and have new partner offerings, without changing your hardware. The example below shows the software hierarchy for Gen 3 Intel® Movidius™ VPU.
Edge Inference Solutions in the Market
There are several edge inference solutions in the market:
- Gen 3 Intel® Movidius™ VPU
- Intel® Movidius™ Myriad™ X VPU
- Nvidia* Jetson TX2
- Nvidia* Jetson NX Xavier
- Huawei* Atlas 200 Ascend 301
| Products | Usage | ResNet-50 Performance | Performance per Watt | Gen 3 Intel® Movidius™ VPU Efficiency is: |
|---|---|---|---|---|
| Gen 3 Intel® Movidius™ VPU (SKU 3400VE) |
IP Camera, AI Appliance | 406 inferences/second | 139 inferences/second/watt | – |
| Nvidia* Xavier NX | IP Camera, AI Appliance | 344 inferences/second | 69 inferences/second/watt | 2.0x vs. Nvidia* Xavier NX |
| Nvidia* Jetson Nano | AI Appliance | 20.3 inferences/second | 5.1 inferences/second/watt | 27x vs. Nvidia* Jetson Nano |
| HiSilicon Ascend 301 | AI Appliance | 319 inferences/second | 40 inferences/second/watt | 3.5x vs. HiSilicon Ascend 310 |
Note: Intel Performance results are based on testing as of 31-Oct-2019 and may not reflect all publicly available updates. No product or component can be absolutely secure. Intel Configuration: DL inference performance on ResNet-50 benchmark measured using INT8, batch size = 1, employing Gen 3 Intel® Movidius™ VPU’s native optimizations. ResNet-50 performance shown reflects low-level optimizations for max performance capability measured as of 31-Oct-2019, with pre-production silicon and tools. Measurement using single ResNet-50 network as standalone workload. ResNet-50 model trained using weight sparsity at 50%. Indicated max performance benchmark expected to change, and customer results may vary based on forthcoming tools releases. Power efficiency (inferences/sec/W) measured as of 31-Oct-2019 for Gen 3 Intel® Movidius™ 3400VE SKU. All performance and power efficiency measurements may be updated with further changes to software tools. Competitor performance shown is measured performance for ResNet-50 (using INT8, Batch Size=1); power efficiency calculated as peak performance divided by power. HiSilicon measured as of 29-Aug-2019 and Nvidia measured as of 20-Aug-2020. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks. See below for more configuration details.
| Product | Gen 3 Intel® Movidius™ VPU | Nvidia* Xavier NX | Nvidia* Jetson Nano | HiSilicon Ascend 301 |
|---|---|---|---|---|
| Tested | 10/31/2019 | 8/20/2020 | 8/20/2020 | 8/29/2019 |
| Precision | INT8 | INT8 | INT8 | INT8 |
| Batch Size | 1 | 1 | 1 | 1 |
| Product Type | Gen 3 Intel® Movidius™ VPU (pre-production) | Jetson Xavier NX developer kit | Jetson Nano developer kit | Atlas 200 developer kit |
| Memory (GB) | 65536 MB DDR-4-2666 | 8 | 8 | 15.5 |
| Processor | N/A | 6-core NVIDIA Carmel ARM v8.2 | 4-core ARM A57 | ARM* A53 x 8 |
| Graphics | N/A | NVIDIA Volta architecture with 384 NVIDIA CUDA cores and 48 Tensor cores | 128-core Maxwell | N/A |
| OS | N/A (CPU core not used) | Ubuntu 18.04 LTS (64-bit) | Ubuntu 18.04 LTS (64-bit) | Ubuntu 16.04 |
| Hard Disk | N/A | N/A | N/A | N/A |
| Software | Performance demo firmware | JetPack: 4.4 | JetPack: 4.4 | MindSpore Studio, DDK B883 |
| Listed TDP | N/A | 15W | 10W | 20W |
Why Intel?
- Intel uniquely offers OEMs a vendor that can supply silicon platforms end to end (camera/gateway/cloud/client) with many common software tools, memory, networking components, FPGAs, OSs, security and computer vision software components. Intel is delivering the Gen 3 Intel® Movidius™ VPU, which is a purpose-built, integrated SoC providing unparalleled computer vision performance efficiency with a flexible architecture for workload partitioning and optimization.
- Disruptive in-camera computer vision technology (both traditional Video Analytics and emerging Neural Net inferencing), enabling new use cases, like intelligent traffic solutions, retail analytics, digital safety and security, industrial automation, and VR/AR.
- VPUs: World-leading CV+DL performance / watt as pre- or co-processor to AP in cameras, and as offload engine in NVRs/servers (up to many in arrays – with better performance/watt and performance/cost than most competitors).
- SoCs: Performance, power and cost optimized for leading edge CV+DL performance per watt per dollar and high-volume smart DSS cameras.
- A scalable VPU-based architecture - Smart Camera SoCs, plus VPU co/pre-processors in IA gateways and cloud servers - allows for the ability to develop distributed computer vision and media workloads across optimized systems, camera to cloud.
- Cross-platform, cross-generation APIs which allow customers & ecosystem partners to consolidate software development focus, saving money and allowing them to focus on higher levels of application software value.
- Solution ecosystem of external partners that help developers to find or create missing parts of the overall solution such as board vendors, software providers for the cloud, and storage providers.
- Community support: Multiple forums that developers can share and learn from others.
- Robust software development tools and support.
- Uncompromised performance with hardened security.
Intel® Tools
| Tools | Description | What you can do? |
|---|---|---|
| Intel® DevCloud for the Edge |
|
|
| OpenVINO™ Deep Learning Workbench |
|
|
| OpenVINO™ Toolkit |
|
|
| Intel® Software Hub |
|
|
| Developer kits and ready-to-use hardware |
|
|
Gen 3 Intel® Movidius™ VPU (coming soon...)
Gen 3 Intel® Movidius™ VPU is the latest generation of Intel® Movidius™ VPU, a compute-efficient SoC with the following advantages:
- More than 10 times inference performance compared with previous generation Intel® Movidius™ Myriad™ X VPU.
- Focused on Deep Learning Inference and supported by the OpenVINO™ toolkit.
- Provides high performance per watt per dollar.
- Has optimized hardware Codec with acceleration for computer vision (CV) and deep learning (DL) as one-chip solution.
- Delivers flexible architecture with the new Neural Compute engine.
Gen 3 Intel® Movidius™ VPU supports both accelerator and standalone use.
| Features | 3400VE | 3400VE | 3700VE |
|---|---|---|---|
| Summary | Edge AI processor (Accelerator mode) | Smart camera SoC (Camera mode) | Performance optimized, Edge AI processor |
| Process VPU Clock Frequency |
12 nm TSMC |
12 nm TSMC |
12 nm TSMC |
| ResNet-50 Performance; Max TOPS (AI Inference) |
406 inference/sec |
240 inference/sec |
565 inference/sec |
| Computer Vision Support | CV/Warp Acceleration 1.0 GP/s |
CV/Warp Acceleration 1.0 GP/s |
CV/Warp Acceleration 1.4 GP/s |
| Video Codec | 4K75 (encode) 4K60 (decode); |
4K75 (encode) 4K60 (decode); |
4K75 (encode) 4K60 (decode); |
| ISP | – |
Up to 4 cameras |
– |
| SHAVE (Processors included) |
16 | 12 | 16 |