Overview
The Intel PyTorch* team has been collaborating with the PyTorch Geometric (PyG) community to provide CPU performance optimizations for Graph Neural Network (GNN) and PyG workloads. In the PyTorch 2.0 release, several critical optimizations were introduced to improve GNN training and inference performance on CPU. Developers and researchers can now take advantage of Intel’s AI/ML Framework optimizations for significantly faster model training and inference, which unlocks the ability for GNN workflows directly using PyG.
In this blog, we will perform a deep dive on how to optimize PyG performance for both training and inference while using the PyTorch 2.0 flagship torch.compile feature to speed up PyG models.
Message Passing Paradigm
Message passing refers to the process of nodes exchanging information with their respective neighbors by sending messages to one another. In PyG, the process of message passing can be generalized into three steps:
- Gather: Collect edge-level information of adjacent nodes and edges.
- Apply: Update the collected information with user-defined functions (UDFs).
- Scatter: Aggregate to node-level information, e.g., via a particular reduce function such as sum, mean, or max.
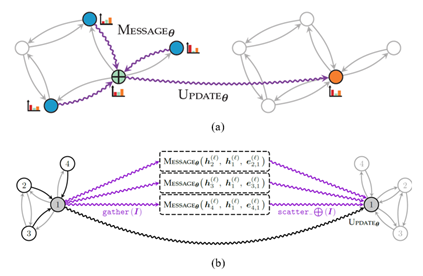
Figure 1. The message passing paradigm (Source: Matthias Fey)
Message passing performance is highly related to the storage format of the adjacency matrix of the graph, which records how pairs of nodes are connected. Two methods for the storage format are:
- Adjacency matrix in COO (Coordinate Format): The graph data is physically stored in a two-dimensional tensor shape of [2, num_edges], which maps each connection of source and destination nodes. The performance hotspot is scatter-reduce.
- Adjacency matrix in CSR (Compressed Sparse Row): Similar format to COO, but compressed on the row indices. This format allows for more efficient row access and faster sparse matrix-matrix multiplication (SpMM). The performance hotspot is sparse matrix related reduction ops.
Scatter-Reduce
The pattern of scatter-reduce is parallel in nature, which updates values of a self tensor using values from a src tensor at the entries specified by index. Ideally, parallelizing on the outer dimension would be most performant. However, direct parallelization leads to write conflicts, as different threads might try to update the same entry simultaneously.
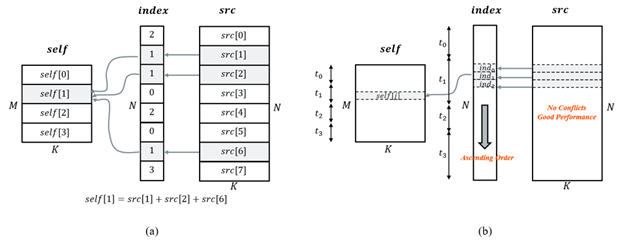
Figure 2. Scatter-reduce and its optimization scheme (Source: Mingfei Ma)
To optimize this kernel, we use sorting followed by a reduction:
- Sorting: Sort the index tensor in ascending order with parallel radix sort, such that indices pointing to the same entry in the self tensor are managed in the same thread.
- Reduction: Paralleled on the outer dimension of self, and do vectorized reduction for each indexed src entry.
For its backward path during the training process (i.e., gather), sorting is not needed because its memory access pattern will not lead to any write conflicts.
SpMM-Reduce
Sparse matrix-matrix reduction is a fundamental operator in GNNs, where A is sparse adjacency matrix in CSR format and B is a dense feature matrix where the reduction type could be sum, mean or max.
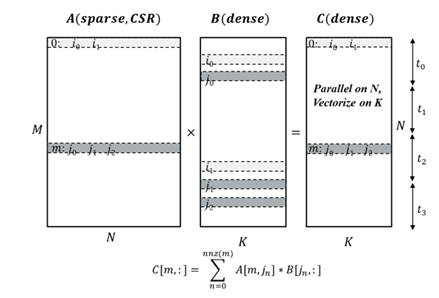
Figure 3. SpMM optimization scheme (Source: Mingfei Ma)
The biggest challenge when optimizing this kernel is how to balance thread payload when parallelizing along rows of the sparse matrix A. Each row in A corresponds to a node, and its number of connections may vary vastly from one to another; this results in thread payload imbalance. One technique to address such issues is to do payload scanning before thread partition. Aside from that, other techniques are also introduced to further exploit CPU performance such as vectorization and unrolling and blocking.
These optimizations are done via torch.sparse.mm using the reduce flags of amax, amin, mean, sum.
Performance Gains: Up to 4.1x Speedup
We collected benchmark performance for both inference and training in pytorch_geometric/benchmark and in the Open Graph Benchmark (OGB) to demonstrate the performance improvement from the above-mentioned methods on Intel® Xeon® Platinum 8380 Processor.
|
Model – Dataset |
Option |
Speedup ratio |
|---|---|---|
|
GCN-Reddit (inference) |
512-2-64-dense |
1.22x |
|
1024-3-128-dense |
1.25x |
|
|
512-2-64-sparse |
1.31x |
|
|
1024-3-128-sparse |
1.68x |
|
|
GraphSage-ogbn-products (inference) |
1024-3-128-dense |
1.15x |
|
512-2-64-sparse |
1.20x |
|
|
1024-3-128-sparse |
1.33x |
|
|
full-batch-sparse |
4.07x |
|
|
GCN-PROTEINS (training) |
3-32 |
1.67x |
|
GCN-REDDIT-BINARY (training) |
3-32 |
1.67x |
|
GCN-Reddit (training) |
512-2-64-dense |
1.20x |
|
1024-3-128-dense |
1.12x |
Table 1. Performance Speedup on PyG Benchmark1
From the benchmark results, we can see that our optimizations in PyTorch and PyG achieved 1.1x-4.1x speed-up for inference and training.
torch.compile for PyG
The PyTorch2.0 flagship feature torch.compile is fully compatible with PyG 2.3 release, bringing additional speed-up in PyG model inference/training over imperative mode, thanks to TorchInductor C++/OpenMP backend for CPUs. In particular, a 3.0x – 5.4x performance speed-up is measured on basic GNN models with Intel Xeon Platinum 8380 Processor on model training2.

Figure 4. Performance Speedup with Torch Compile
Torch.compile can fuse the multiple stages of message passing into a single kernel, which provides significant speedup due to the saved memory bandwidth. Refer to this pytorch geometric tutorial for additional support.
Please note that torch.compile within PyG is in beta mode and under active development. Currently, some features do not yet work together seamlessly such as torch.compile(model, dynamic=True), but fixes are on the way from Intel.
Conclusion & Future Work
In this blog, we introduced the GNN performance optimizations included in PyTorch 2.0 on CPU. We are closely collaborating with the PyG community for future optimization work, which will focus on in-depth optimizations from torch.compile, sparse optimization, and distributed training.
Acknowledgement
The results presented in this blog is a joint effort of Intel PyTorch team and Kumo. Special thanks to Matthias Fey (Kumo), Pearu Peterson (Quansight) and Christian Puhrsch (Meta) who spent precious time and gave substantial assistance! Together, we made one more step forward on the path of improving the PyTorch CPU ecosystem.
References
- Accelerating PyG on Intel CPUs
- PyG 2.3.0: PyTorch 2.0 support, native sparse tensor support, explainability and accelerations