Introducing Hyper-Converged Distributed Cache Storage (HDCS)
In this paper, we present a new hyper-converged distributed cache storage (HDCS) solution. It’s an open source project designed to improve application performance with fast devices like Intel Optane SSDs and persistent memory devices to be used as local distributed cache storage. The solution implements a lockless threading model to eliminate complex software stack locking issues. It uses kernel bypass technologies like remote direct memory access (RDMA) and Persistent Memory Development Kit (PMDK) to reduce CPU and memory consumption. We also present a performance evaluation of HDCS with Intel® SSD P3700 Series and Intel Optane SSD P4800x under different usage scenarios. The performance results show that by using Intel Optane SSD P4800x, HDCS delivers up to 40.6x performance improvement and 62.5 percent latency reduction for typical synthetic OTLP workloads simulated by Flexible I/O tester (FIO).
Download Configuration files [2KB]
Background and Motivations
Data centers are adopting distributed storage solutions based on commodity hardware to meet the requirements of cloud computing and big data analytics. These solutions include a large number of nodes working together to provide aggregated capacity and performance with self-managing, self-healing disaster recovery and load balancing.
Several motivations are driving the move of online transaction processing (OLTP) workloads to distributed storage systems. As they migrate workloads to the cloud, e-commerce service providers face new challenges as they work to deliver high performance and low latency storage solutions on large-scale clusters. Service providers are gradually transforming their OLTP workloads from traditional storage to scale out distributed storage solutions. However, OLTP workloads differ in behavior from generic block/object workloads; a typical OLTP workload requires extremely low response time under high concurrency, which requires high performance, low latency, and a scalable storage solution.
The disruptive Intel® Optane™ Solid State Drive based on Intel® 3D XPoint™ technology fills the performance gap between dynamic random-access memory (DRAM) and NAND-based solid-state drives (SSDs). Intel Optane technology delivers an unparalleled combination of high throughput, low latency, high quality of service, and high endurance. It is a unique combination of Intel 3D XPoint Memory Media, Intel® Memory Controllers and Intel® Storage Controllers, Intel® Interconnect IP, and Intel® software. Together, these building blocks are making a revolutionary leap forward in decreasing latency and accelerating systems for workloads that require large capacity and fast storage. Intel Optane technology provides peak bandwidth of over 2000 MB/s for sequential read/write and about 550 k input/output operations per second (IOPS) for random read/write, with an extremely low latency of 0.01 ms.
HDCS Architecture Overview
HDCS acts as a reliable and highly available persistent storage layer between applications and distributed storage systems. It provides extremely low tail latency with limited CPU and memory consumption, and has the capability to fully exploit underlying fast media devices like Intel Optane SSDs and persistent memory.
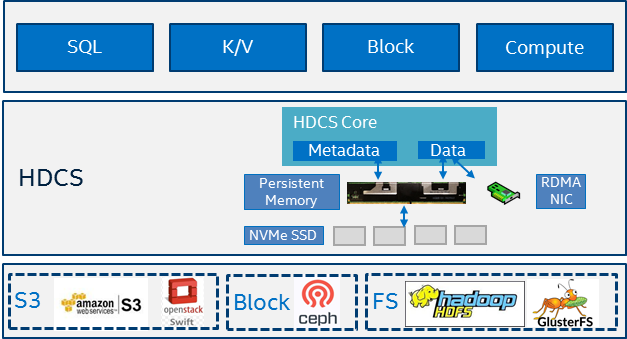
Figure 1. HDCS design overview.
Figure 1 illustrates the general HDCS architecture. It is a distributed cache located on a compute node. HDCS is designed to be fast; it uses persistent memory as a buffer and NVMe* SSD as the warm tier. UNIX* domain socket and RDMA technology is used to bypass kernel TCP/IP overhead and move data from primary to secondary directly when doing replication. HDCS supports various storage backends including S3* object storage systems, Ceph* block systems, and the Apache Hadoop* Distributed File System (HDFS), where HDCS acts as a unified cache layer for storage systems with different interfaces such as S3*, block interface, and distributed filesystem interface.
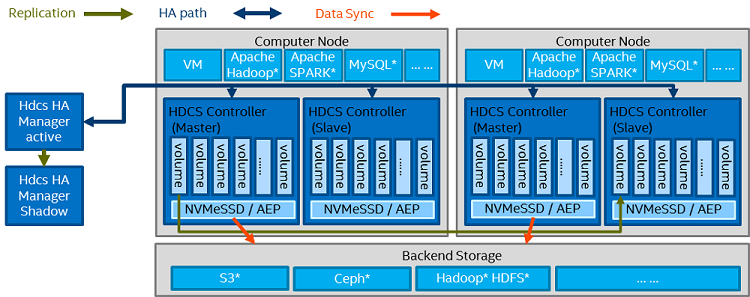
Figure 2. HDCS architecture.
A high-level HDCS design is illustrated in figure 2. HDCS adopts a primary/secondary architecture for data placement. There are two kinds of processes in HDCS: HDCS Controller and HDCS HA Manager. Each compute node should run two HDCS Controller processes: primary and secondary. HDCS HA Manager is a separate process that might be co-located with the controller or on a separate node. It collects all HDCS Controller status and calculates the failure domain for the primary/secondary group. HDCS HA Manager communicates with all HDCS Controller processes, providing heartbeats and the latest failure domain information. HDCS Controllers replicate data to the assigned secondary nodes according to the failure domain algorithm and switches its status due to failure domain changes.
HDCS supports two modes: cache and storage. In cache mode, data is stored in both local storage media (NVMe SSD/persistent memory) and backend storage, providing faster data access for mission-critical workloads or satisfying different SLA requirements. Either a write-through or write-back policy can be applied to cache mode. An unexpected process crash will not result in data loss, since by replication design the dirty data will be continuously flushed to backend storage once the crash occurs. In storage mode, data exists only in the local store before a flush action is triggered manually. In storage mode, HDCS is considered as a hyper-converged, reliable storage solution.
Inside one HDCS Controller, the key module that provides lockless persistent storage is called HDCS Core, which is responsible for handling all input/output (I/O) workflows to/from the virtual volume. As shown in figure 2, one HDCS Core is used to manage one virtual volume. Since HDCS uses volume-level replication, each volume has one primary HDCS Core in the local compute node, and one or more secondary HDCS Cores in separate nodes. The HDCS primary and secondary pairs are calculated by the HA Manager’s failure domain algorithm. HDCS Core directs the PMDK and RDMA libraries to bypass some kernel paths and avoid unnecessary memory copies, which enables HDCS to fully utilize CPU cycles, and maintain low consumption of total CPU and memory for computer nodes.
HDCS Key Designs
HDCS is designed to be a high performance, highly reliable, and highly available persistent storage layer. Here we introduce the detailed design and implementations to achieve this goal: (1) HDCS Core design and implementation, (2) Tiered data storage, (3) Replication and network, and (4) Data reliability and consistency.
HDCS core design and implementation
The design principle of HDCS Core is to build a lockless persistent-storage context for each virtual volume; which is to say, when a volume is opened by a virtual machine or an application, the HDCS Controller opens an HDCS Core context for this volume. A close call will trigger a graceful shutdown of this HDCS Core. HDCS Controller is a process context and a resource manager to all opened HDCS Cores. The HDCS Controller context also includes key information including HA modules, local data storage handlers, network connections, and an HDCS Core stat guardian.
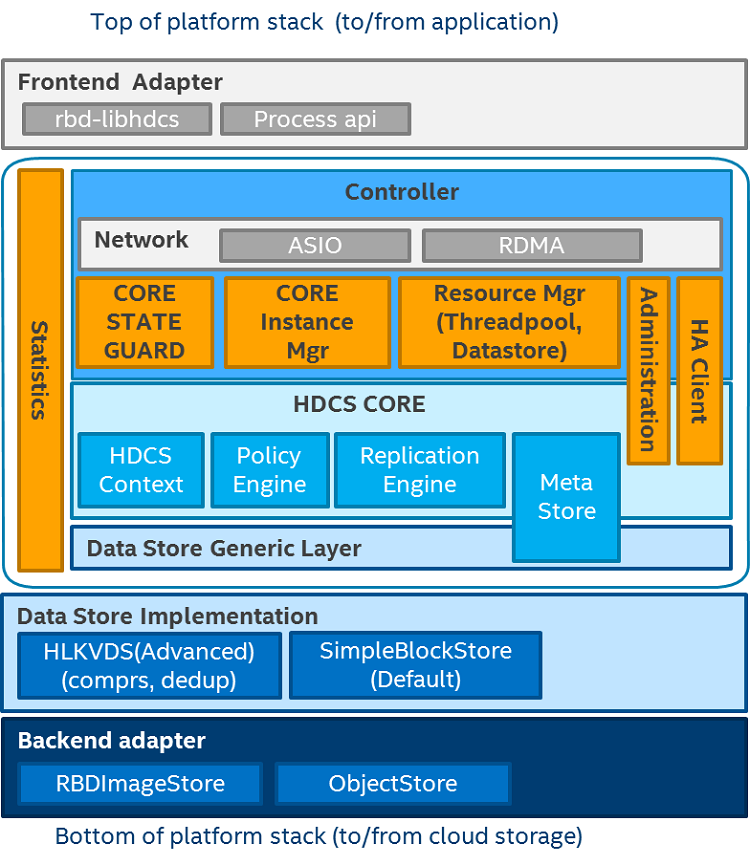
Figure 3. HDCS Core architecture.
Figure 3 shows a detailed architecture of HDCS with all individual modules. Above the HDCS Controller, the Frontend Adaptor module is a lightweight layer used to interact with different interfaces, including the S3* interface, block interface, and filesystem interface, or any third-party interfaces developed following the adaptor API. HDCS Controller contains only an abstract API of the underlying local data storage and backend storage implementations. The HDCS data store is friendly to fast storage devices like NVMe SSDs or persistent memory. By design, it employs two different storage implementations. One is simple block-based storage that can be easily implemented on PMDK, and the other one is a key value data store that supports transactions and will also support advanced features such as compression and deduplication.
Tiered data store
HDCS was designed to be optimized for persistent memory and new non-volatile memory (NVM) technologies. The storage hierarchy is new, and we designed a new architecture to better utilize it.
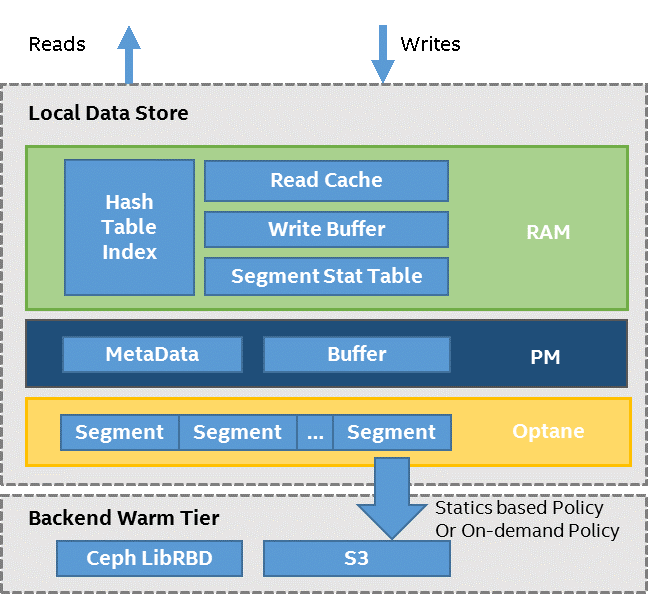
Figure 4. HDCS Data Store architecture.
The HDCS hierarchical storage architecture works in a hybrid storage hardware environment that may include devices such as persistent memory and different types of SSDs with tiering capability. The read/write data are served by the DRAM layer first, then flow to the persistent memory layer as a buffer, and then are merged into segments at the SSD layer.
The key idea is that we provide a layer of semantic abstraction of a storage tier to describe generic primitives for space provisioning functionality, reclamation, data placement, and so on. These primitives allow a highly flexible tiered implementation, and enable us to define a caching or tiering topology across various storage types. We can exploit the capabilities of the underlying media, such as Intel 3D XPoint technology, which provides byte-addressability and comparable latency to DRAM.
HDCS also supports tiering data to remote warm/cold storage in addition to the high performance local hierarchical store. Different storage backend engines are provided in the backend adaptor. The HDCS Controller monitors usage of the datasets over time, and it uses this knowledge to move data between the storage tiers. Either policy-based or statistical models can be applied for statistics-based or user-triggered data movement.
Networking and data replication
HDCS messenger is optimized to reduce network latency. In a traditional 10-GbE network, the roundtrip latency is approximately 15 us. Because the HDCS underlying storage media is NVMe SSD/Intel Optane SSD devices, this would be a big overhead and thus impact the overall throughput. HDCS messenger uses short-circuit communication to further reduce network latency.
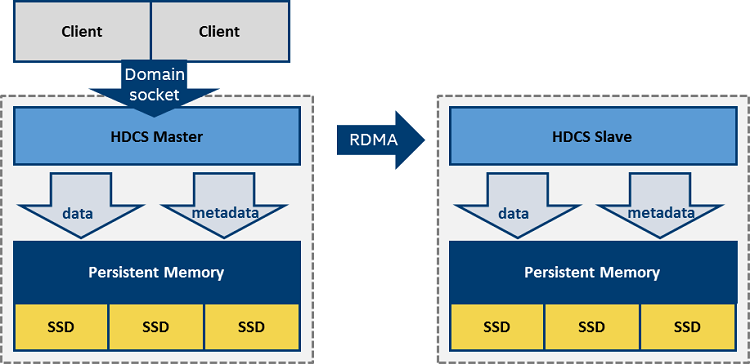
Figure 5. HDCS network.
Since HDCS is deployed as a hyper-converged architecture (the clients and primary are running on the same compute node), a UNIX domain socket can be used to bypass TCP/IP overhead for all local I/O. Replication supports the RDMA protocol, which moves data from primary to secondary directly. RDMA comes in various forms and is already very mature in high-performance computing. In HDCS, our RDMA implementation works both on internet Wide-Area RDMA Protocol (iWARP) and RDMA over Converged Ethernet (RoCE) V2 protocols. Use of RDMA decreases latency compared with TCP/IP, and also saves CPU cycles and memory.
Data Reliability and Consistency
HDCS supports volume-level replication to guarantee data reliability. It supports RDMA for cluster networks, which keeps the overhead of a replicated write relatively low. The replication number and consistency level (the number of replicas on which the write must succeed before returning an acknowledgment to the client application) are configurable to handle requirement tradeoffs between peak performance and good reliability.
The replication group is calculated by the HDCS HA Manager. As shown in figure 6, HA Manager collects information regarding HDCS Cluster map and the health status of all HDCS Controllers. It uses this information with a failure domain algorithm to produce replication pairs.
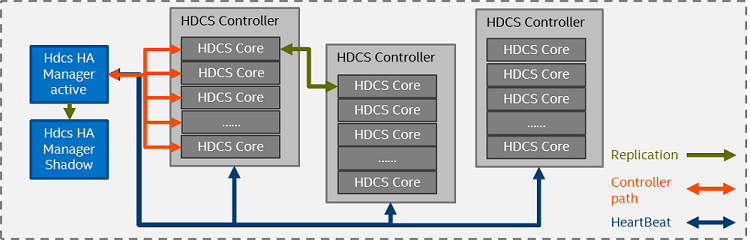
Figure 6. HDCS replication and HA.
One common challenge of replication design is how to keep data consistent between primary and secondary. We chose a strong consistency model in HDCS, so when a crash occurs, a commit log inside the primary is used to make the data recover decision. An HDCS Core Stat Guard (shown in figure 2) is implemented to guard and switch states of all HDCS Cores. The HDCS Core has five states: error, inconsistent, read-only, degraded, and healthy. HDCS serves client requests in read-only, degraded and healthy mode. An error or inconsistent status returns an error code to applications and triggers a data recovery processes.
HDCS Performance
Testing methodology
To simplify the performance testing process, we implemented a new FIO engine called libHDCS for block workload+ testing. For each test case, the benchmark result and system characteristics were measured by a benchmark tool name CeTune*. Volume size is set to be 10 GB. Page cache was dropped before each run to eliminate page cache impact, and each test was configured with a 300-second warm up and 300-second data collection. Detailed FIO testing parameters were included in the software configuration part.
Performance comparison with and without HDCS
| Client | Ceph* | |
|---|---|---|
| CPU | Intel® Xeon® CPU E5-2699 v4 @ 2.20 GHz | Intel Xeon CPU E3-1275 v3 @ 3.5 GHz |
| Memory | 192 GB | 32 GB |
| NIC | Intel® 82599 10 GbE | Intel 82599 10 GbE |
| Storage | 1 * HDD for OS (Ubuntu* 14.04) 1 * 400 GB Intel® SSD S3700 Series |
1 * HDD for OS (CentOS* 7.2) 1 * 400 GB Intel SSD S3700 Series (Journal*) 1 * 400 GB Intel SSD S3700 Series (OSD DATA) |
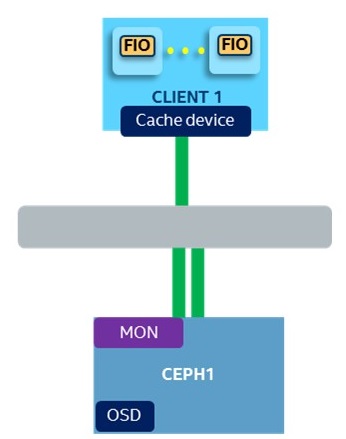
Figure 7. Cluster topology and hardware configuration.
To evaluate HDCS performance in cache mode, we conducted 4k randwrite and randread tests on a single-node Ceph* cluster. Cluster configuration is illustrated in figure 7. Cache device, Ceph* Journal and object storage device (OSD) are using Intel® SSD S3700 Series and Ceph* replication size is set to 1. The only difference between the two comparison cases is use of HDCS.
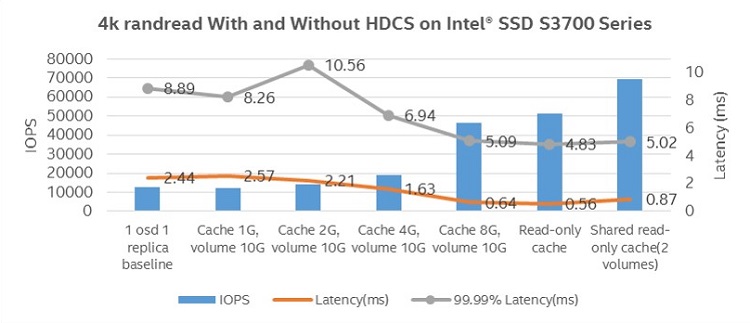
Figure 8. 4k randread with and without HDCS on Intel® SSD S3700 Series.
Figure 8 shows the 4k randread results comparison with and without HDCS. Scaling cache ratio (cache size/volume size) from zero percent to 100 percent, 4k randread throughput increases 3.97 times; from baseline (without HDCS) 12927 IOPS to 51436 IOPS, latency decreases from 2.4 ms to 0.6 ms. With two shared volumes (volumes share the same base snap), the total throughput of two shared volumes reaches 69730 IOPS with a latency of 0.868 ms.
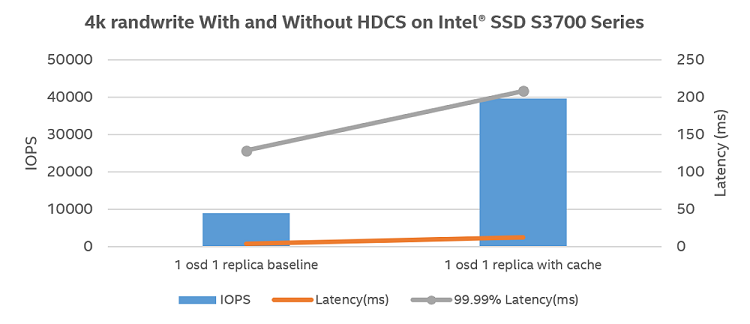
Figure 9. 4k randwrite with and without HDCS on Intel® SSD S3700 Series.
Figure 9 shows the 4k randwrite results comparing with and without HDCS. Throughput increases 4.44 times, from baseline 8920 IOPS to 39643 IOPS, but latency also increases from 3.49 ms to 12.48 ms.
HDCS performance on Intel® Optane™ SSDs
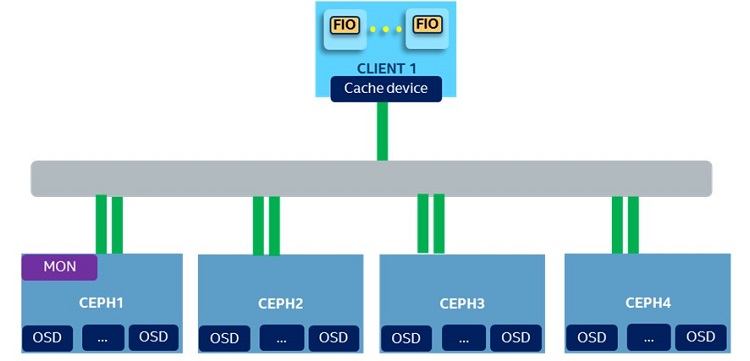
Figure 10. Cluster topology.
| Hardware Configuration | ||
|---|---|---|
| CPU | Client | Ceph* |
| Intel® Xeon® CPU E5-2699 v4 @ 2.20 GHz | Intel Xeon CPU E3-1275 v3 @ 3.5 GHz | |
| Memory | 192 GB | 32 GB |
| NIC | Intel 82599 10 GbE | Intel 82599 10 GbE |
| Storage | 1 * HDD for OS (Ubuntu* 14.04) 1 * 375 GB Intel® Optane™ SSD P4800x 1 * 2 TB Intel® SSD P3700 Series |
1 * HDD for OS (CentOS* 7.2) 2 * 400 GB Intel SSD S3700 Series (Journal*) 8 * 2 TB HDD (OSD DATA) |
Figure 10 showed the performance comparison of a 4k randwrite test with different storage devices (Intel SSD S3700 Series, Intel® SSD P3700 Series, and Intel Optane SSD P4800x) for HDCS in tier mode; backend storage is a Ceph* cluster with 8x HDDs.
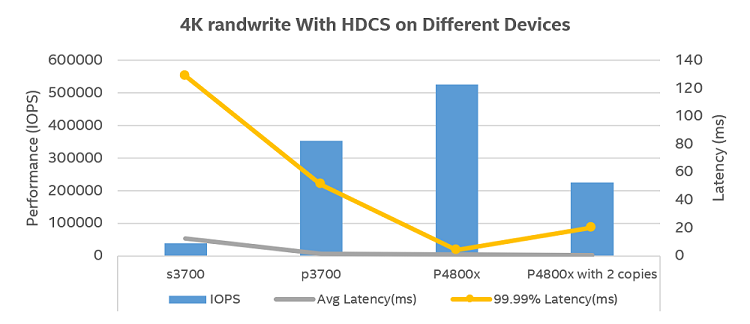
Figure 11. 4k performance with Intel® SSD P3700 Series and Intel® Optane™ SSD P4800x.
Figure 11 shows 4k randwrite performance comparing the Intel SSD S3700 Series, Intel SSD P3700 Series, and Intel Optane SSD P4800x as cache devices. Compared with use of Intel SSD S3700 Series (SATA SSD) as HDCS local storage, using Intel SSD P3700 Series (NVMe SSD) increases up to 8.88x throughput improvement. Moreover, using Intel Optane SSD P4800x shows 1.48x performance advantages over Intel SSD P3700 Series, from 353K to 525K, hitting Intel Optane SSD P4800x spec throughput. Intel Optane SSD P4800x also significantly reduced the tail latency, with 99.99th latency, a critical SLA criteria for OLTP workloads. A 75 percent tail latency reduction was also observed (from 51.07 ms to 4.03 ms), which shows that Intel Optane technology is an excellent choice for compute-side cache to speed up OLTP workloads.
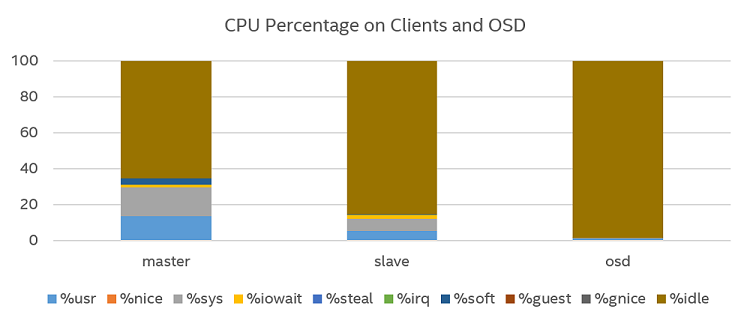
Figure 12. 4k performance with Intel® Optane™ technology, CPU utilization.
Figure 12 shows CPU consumption for Intel Optane SSD P4800x with two copies, with about 35 percent utilization in the primary HDCS node and 15 percent utilization in the secondary HDCS node.
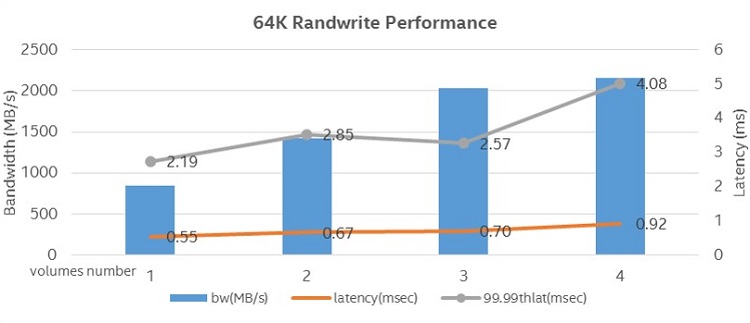
Figure 13. 64k performance with Intel® Optane™ technology.
Figure 13 shows the 64k randwrite performance using Intel Optane SSD P4800x as the HDCS local storage device for bandwidth-intensive workloads. Scaling the volume number from one to four shows a nice scalability from 851 MB/s bandwidth to 2153 MB/s bandwidth with a stable average latency below 1 ms, and 99.99th latency below 5 ms.
Next Steps
Persistent memory support in data store
As the next step, HDCS will use Persistent Memory over Fabric (PMoF) to improve the efficiency of RDMA and persistent memory. This will enable low latency and high-speed remote replication of persistent memory over fabrics. PMDK includes the RPMEMD library, which implements this with a simple set of APIs. Figure 14 shows the architecture of this configuration.
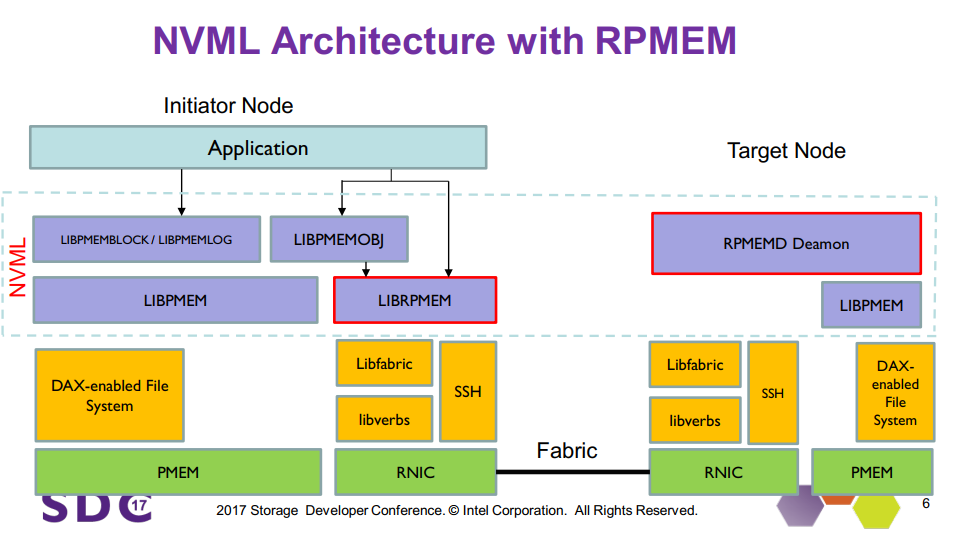
Figure 14. NVML architecture with PRMEM.
Speed up big data analytics workloads
There is a growing trend to run big data analytics workloads on disaggregated storage solutions as in on-premise big data clusters. Both compute and storage are bound to a single physical node and cannot be scaled independently. This brings new challenges since the disaggregated architecture does not have data locality. Using HDCS as temporary storage for big data workloads on the compute site will be a promising approach to improving the performance of the disaggregated storage systems.
Summary
In this article, we presented a hyper-converged distributed cache storage system, HDCS, a hyper-converged cache and storage system for cloud and big data environments. It employs fast storage devices like NVMe SSD and persistent memory, and RDMA to provide highly reliable and highly available persistent storage solutions with extremely low tail latency. Performance testing results show that HDCS with Intel Optane SSD P4800x provides up to 58.9 times performance improvement when testing with and without HDCS. Using Intel Optane SSD P4800x as the cache device provides 1.48 times performance improvement and 75 percent latency reduction compared with the Intel SSD P3700 Series, which demonstrates Intel Optane SSD as an excellent choice to speed up OLTP workloads where tail latency is a critical SLA criterion. As a hyper-converged distributed cache store, there are multiple areas that can influence HDCS to improve the performance or reduce the cost, which remains our future work.
References
- iWARP* RDMA Here and Now Technology Brief
- RoCE v2 Considerations
- xuechendi/fio – GitHub archive
- 01org/CeTune – GitHub* archive
- Persistent Memory Over Fabric (PMOF) - SNIA.org