Overview
There are many subsystems that contribute to the excessive amount of resume time in the x86 kernel, but the worst offender by far is the ata subsystem, which is responsible for hard disks. The standard mechanical hard disk takes a few seconds to spin down while it suspends, and even longer to spin back up on resume. Even with SSD (Solid State Device) Disks the resume time can be upwards of a second because of all the device layers that comprise a full disk suspend. First there's the AHCI controller which is connected via PCI and is resumed in the noirq phase. An AHCI controller can support several SATA drives, each using a single port, so next each of those ports must be awakened. This happens at the beginning of the general resume phase and is just the tip of the iceberg.
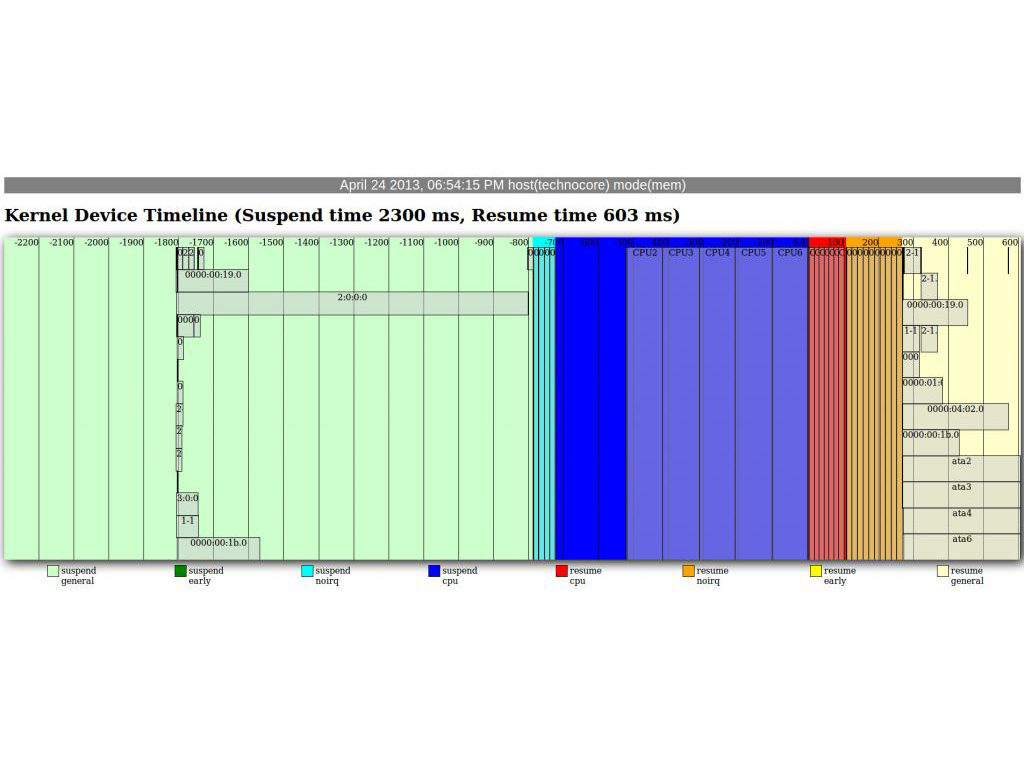
Each port is comprised of 3 individual devices: a port, a link, and a physical device, and each of these devices have transport classes that are treated as child devices. Then each ata port is given a scsi host device, and each ata physical device a scsi target device. Then on top of that a block device is used to allow the disk to be mounted and used. So in a system with 6 ata ports that comes out to 54 devices that have to be resumed in order for the disks to come back online. Needless to say, this can take a while. See the following AnalyzeSuspend output to see the effects visually:
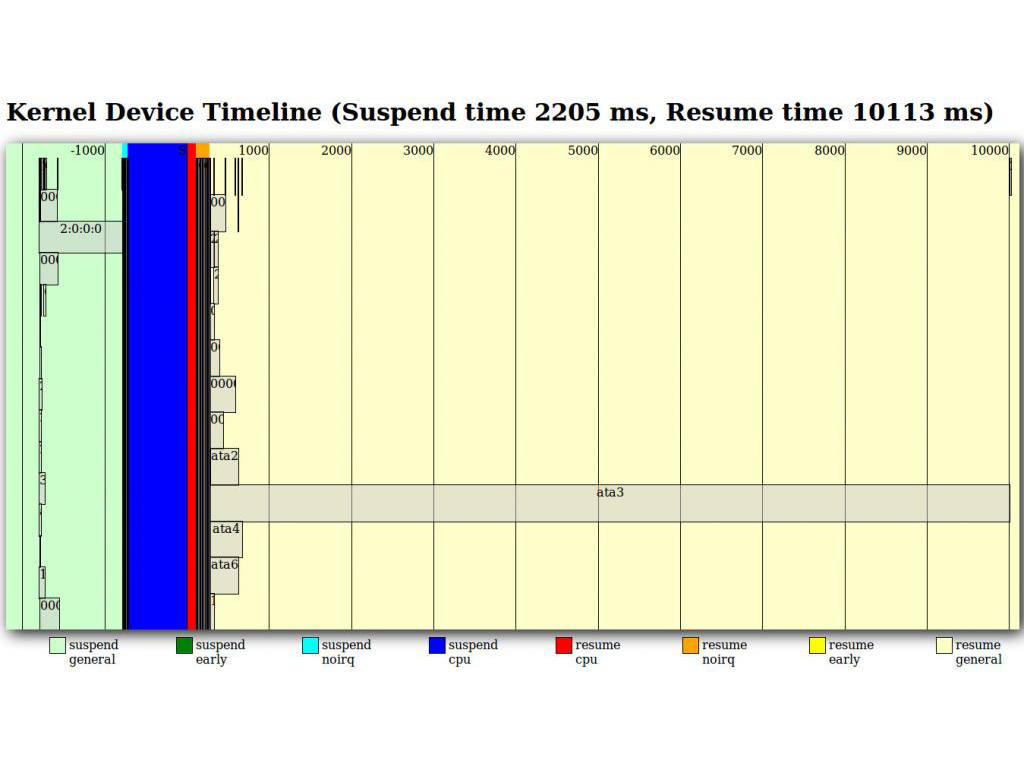
The system this test was run on had two SATA drives attached. A 480GB SSD on AHCI port ata4, and a 3TB hard disk on AHCI port ata3. Note that the 3TB disk takes nearly 10 seconds to resume.
Proposed Solution
Currently, the power management subsystem supports only two kinds of resume behavior: synchronous blocking, and asynchronous blocking. Each device decides whether it needs to be resumed synchronously or asynchronously at pm registration. During resume, an ordered list of all the async devices is traversed and each device is queued for asynchronous resume. Then the pm subsystem moves on to the sync device list, and resumes them one at a time while waiting for each to complete. In general this works ok, but it can lead to hazards if the devices in a particular subsystem's resume path are not all added to the same queue. The sync and async resume queues operate in parallel, and any devices in one queue that are dependant on devices in the other can force the queue to wait. In the case of the ata subsystem, some devices are asynchronous and some are synchronous.
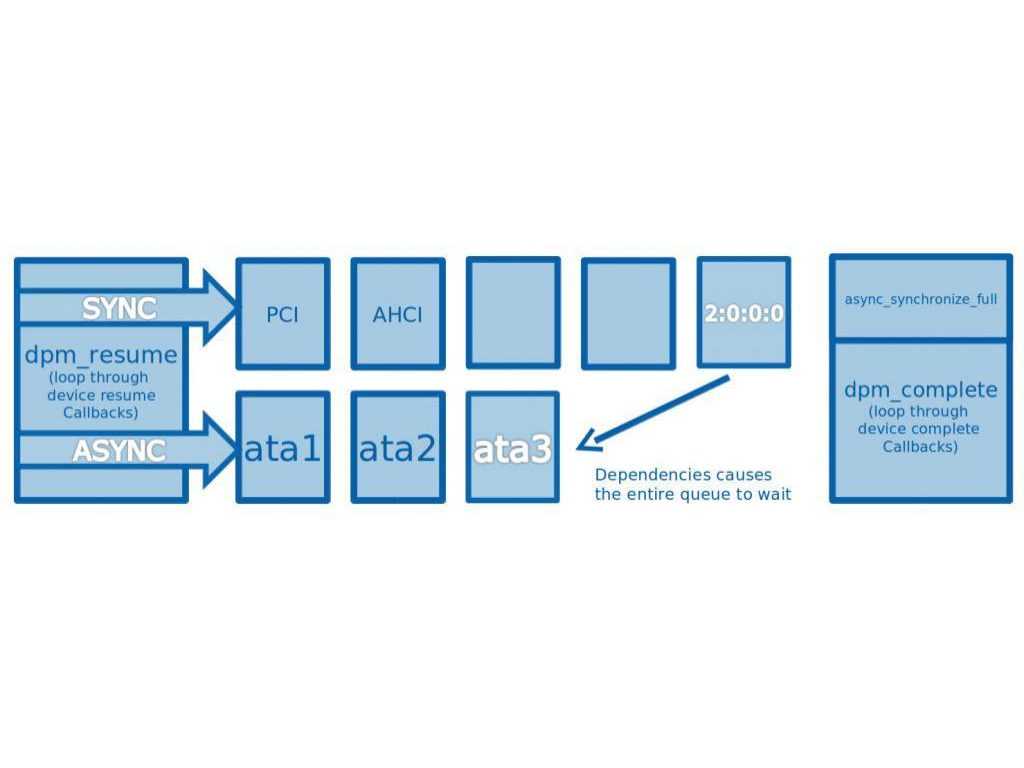
So the first step is to create a patch that configures all devices in the ATA resume path to resume asynchronously, thus preventing either of the queues from getting backed up. But this only reduces ata resume time by a few hundred milliseconds, which is a drop in the bucket. We could try to focus on optimizing the low level ATA resume itself, but this isn't really practical. The majority of the ATA resume time comes from the massive amount of time needed to wake up the ata port. According to the SATA spec, software is supposed to initiate the ata port wakeup, then wait for the status register's busy bit to turn off. Any attempt to issue commands before the ata port is done resuming will cause a failure and a series of interrupt handlers will be invoked to retry over and over. So the solution is going to have to be more general.
To find a better approach we have to look at what resume truly means to the user. The user sees the system as resumed when the display is back online and user input is being accepted. It'll be a few seconds before the user needs anything from the disk, since most of what's being executed is in cache and RAM. So what if we just finished system resume before ATA resume is complete and allowed it to finish quietly in the background?
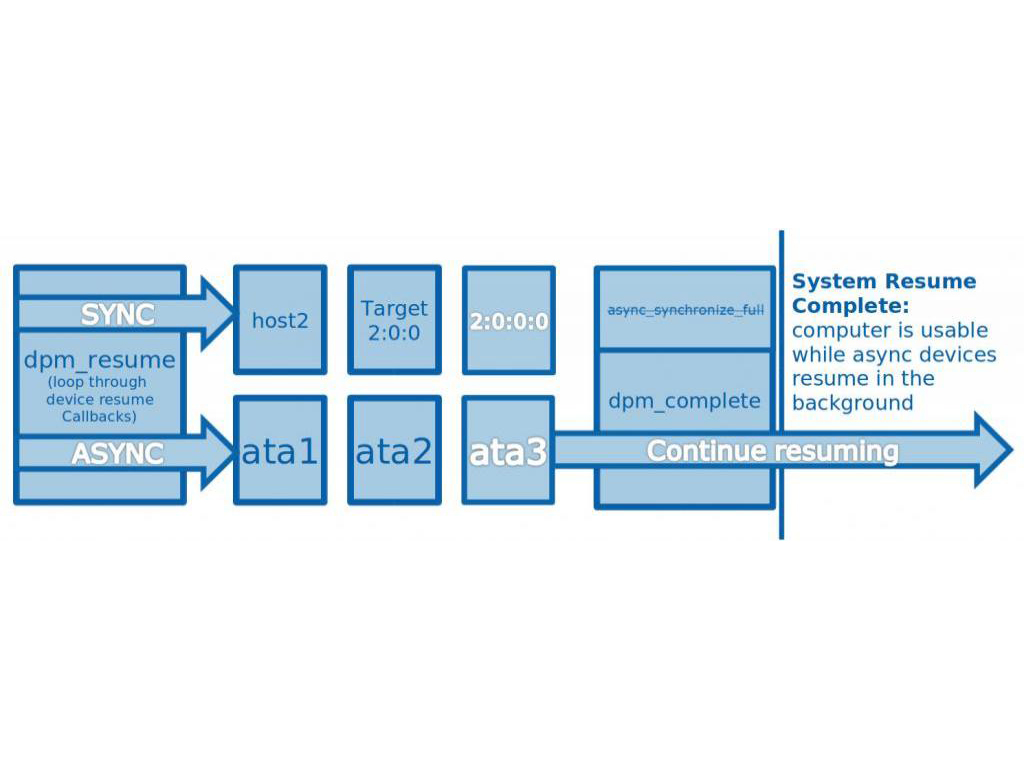
In most cases the disks wouldn't be accessed for a few seconds anyway, so they would be fully resumed before the user noticed anything. But there are cases where the disks are needed immediately, such as when the user is playing a video from the hard drive. In this case, the system would come back and would be responsive, but the video would not continue playing for a few seconds until the disk was back online. So in the worst case scenario the user still has to wait the same amount of time, but they can at least do other things while they wait. In the best case scenerio the user will get a massive resume time boost with no noticeable side effects.
The Patch
I've created a patch which implements this functionality and have put it in the pm-graph repo in the dev folder:
https://github.com/01org/pm-graph/blob/master/dev/ata_resume_async.patch
I've updated the kernel/power subsystem to allow any devices which have registred as asynchronous and who have not registered "compete" callbacks to be non-blocking. As it happens, the ATA subsystem devices don't register complete callbacks, so this is a simple way of adding the new functionality and getting ATA to conform immediately. I've also moved the async_synchronize_full() call from the end of dpm_resume to the beginning of dpm_suspend. This call is intended to block resume until all async devices are finished resuming, and taking it out allows them through. They're blocked after this point only if they have a complete callback. I put the call at the beginning of dpm_resume to handle the case where a suspend is initiated before the non-blocking asynchronous devices have finished resuming. In this case, the dpm_suspend call will wait for them to finish, and only continue once the system is in the resumed state.
Testing thus far has proved quite positive and I'm ready to move on to submitting the patch to lkml.
Results
The following are the improvements resulting from the patch being applied. It effectively reduces resume time to 640ms by taking ata resume out of the system resume path. In the extreme situation of the above 3TB SATA disk, this is a 15x improvement in resume speed!