If you use proprietary applications for documentation, you may not be aware of this but a docx is really an archive.
Often, these *.docx documents are used to transfer content to web developers to be placed for online content in Content Management Systems, wikis or blogs. Often, Word documents are the only resource for the images.
Example: 26 images
This example includes 26 images within a docx document. How, when using a proprietary solution, would you extract these images?
Option 1. Click each image and "Save As Picture" for all 26 images.
Option 2. Unzip in GNU Linux*
Option 3. Unzip in Windows*
Extract Images using GNU Linux
To extract images from a *.docx file, run the command in a GNU Linux terminal:
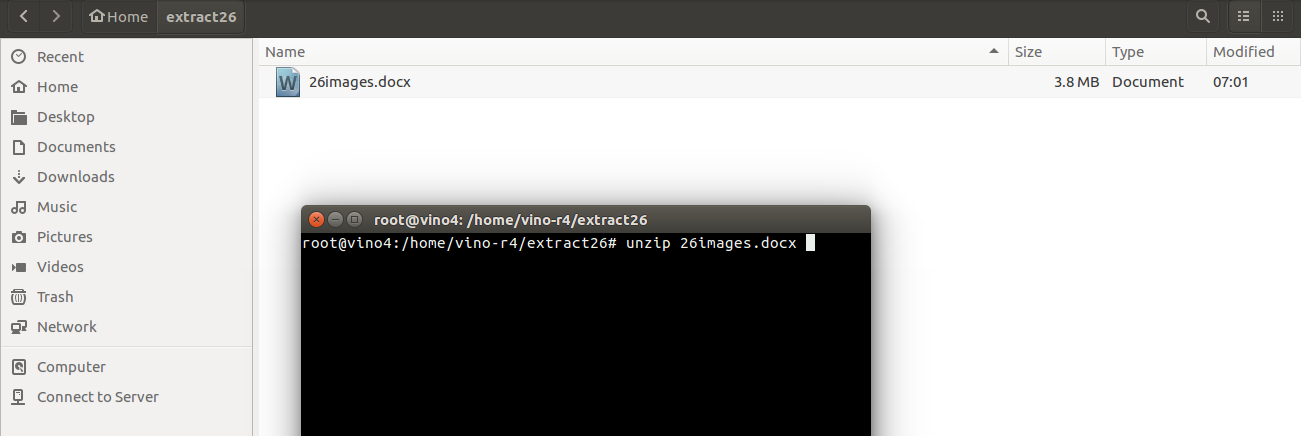
unzip NameofFile.docxIn this case, the document is 26images.docx so the command would be:
unzip 26images.docxThe docx unzips and extracts the xml and images.
![]() Click the images below to open a larger display in a new window.
Click the images below to open a larger display in a new window.
 |
 |
| Extracting |  |
| Extracted files and directories | 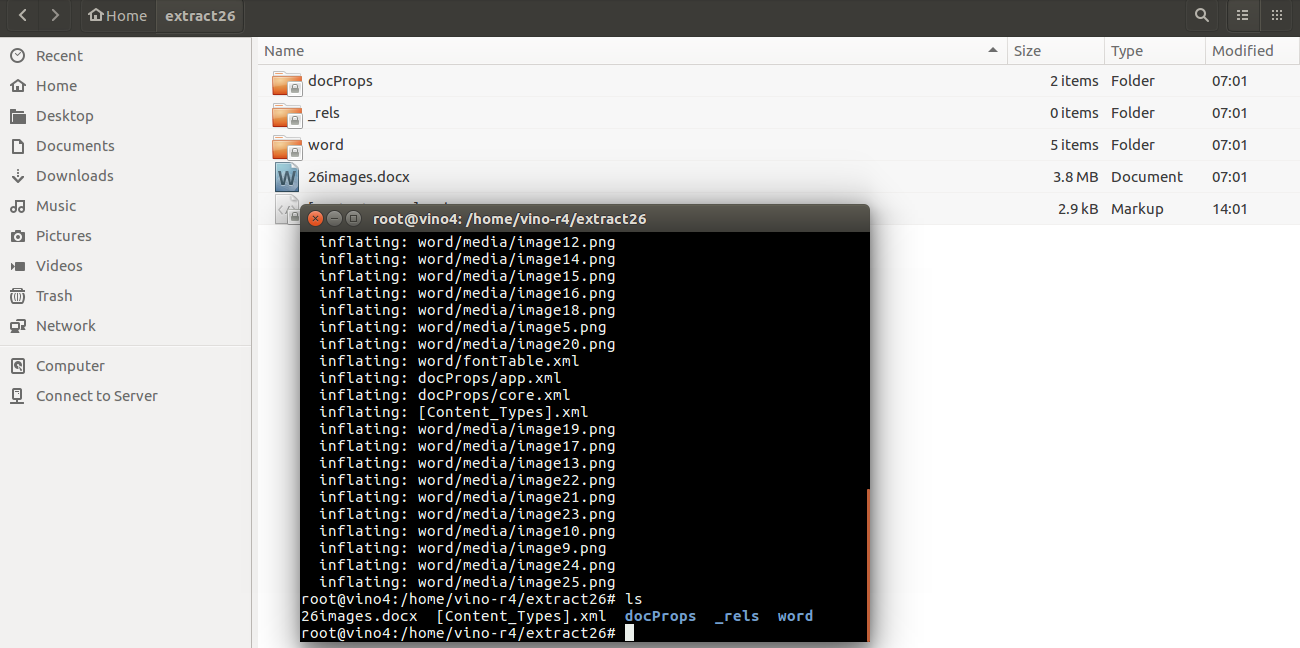 |
| Location of images: /extractiondir/word/media |  |
Proprietary Solution
If you must use proprietary software, WinZip* will extract the images. Click File > Open and select the file. The location of the images is:
word\media\allthepngsarehere.png 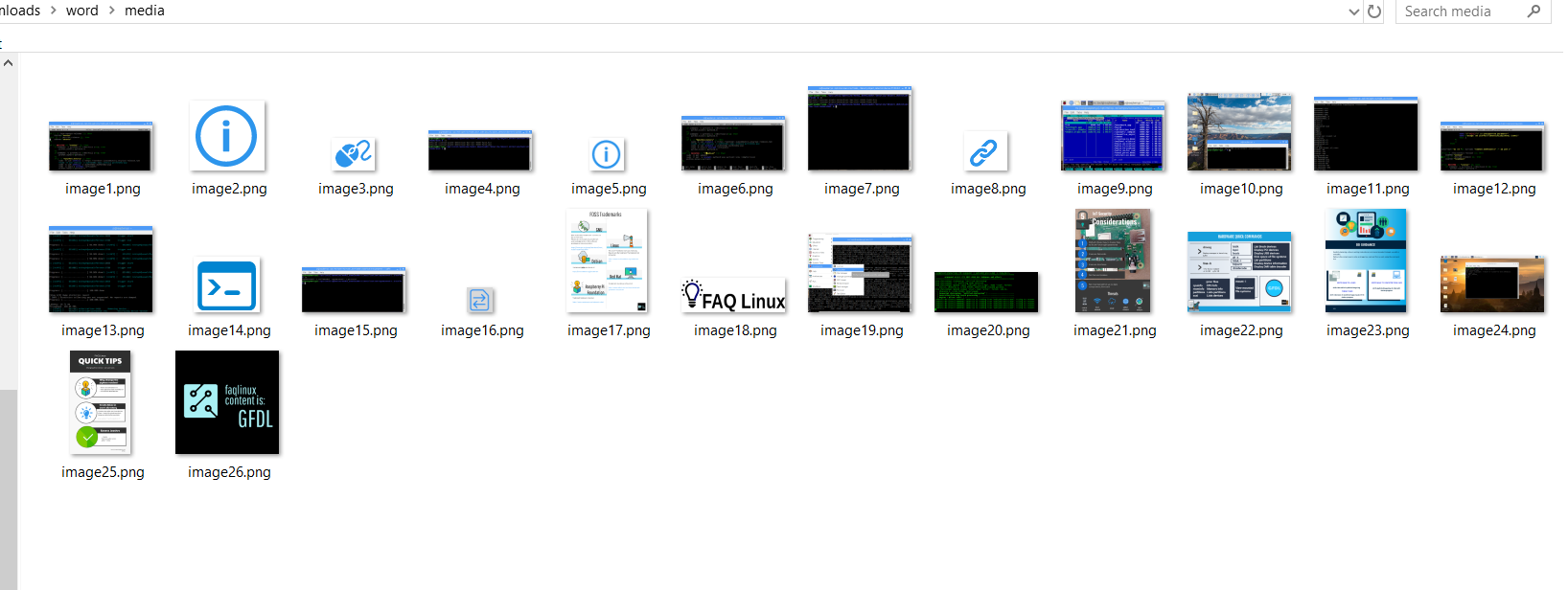
Conclusion
Extracting image files instead of the manual process of saving each image one at at time can save time and dollars for your projects. Streamline your projects using GNU Linux and you can potentially save man hours and dollars.
All images included in this blog post are GFDL. A sample docx is attached so you can try this for yourself.