Why do we need to know this? As computers get more and more powerful we always see hierarchies emerge in designs that may require us to modify our coding practices when we are intent on extracting maximum performance. In the case that motivates this article, when an accelerator (e.g., GPU) becomes more powerful by having more execution units than fit on a single tile, there are performance differences between tile local activities and activities that span across tiles. To maximize our flexibility as programmers, we are given multiple ways to present the hardware to our applications. In FLAT mode, we have multitile components presented to the application as if they were multiple devices. This approach matches this newer multitile non-uniformity to the roughly equivalent situation of dealing with the non-uniformity of multiple devices. For more sophisticated programming approaches, other modes of operation exist to expose the full details of the hierarchy which allows us to customize our code to manage the different levels of non-uniformity at each level of the hierarchy. The choice is ours, and the default (as of late 2023) FLAT mode starts us with a mode that mimics the non-uniformity that many applications already address. As mentioned late in this article, we also have ways to divide accelerators between multiple applications.
Managing GPU tile hierarchy and affinity with environment variables
Key environment variables exist to help control two factors:
- Whether multitile devices are viewed as a combined device with sub-devices, or as multiple devices.
- Which devices/sub-devices are visible at all.
The use of the environment variables means that we control what an application “sees” without changing the application. This gives us controls that we can put into scripts to divide up our system exactly as we wish and expose each specific application to the hierarchy that is best for that application’s performance. We can also restrict what one application can use while concurrently giving different restrictions to another application.
Controls for the GPU/Level Zero driver affect what and how devices appear to the run-times which by default will pass them along to an application. Additional runtime-based controls complement these device driver controls. Run-time controls help further control which device drivers and devices are visible to applications. The following figure illustrates the possible filtering that can be used to affect an application.
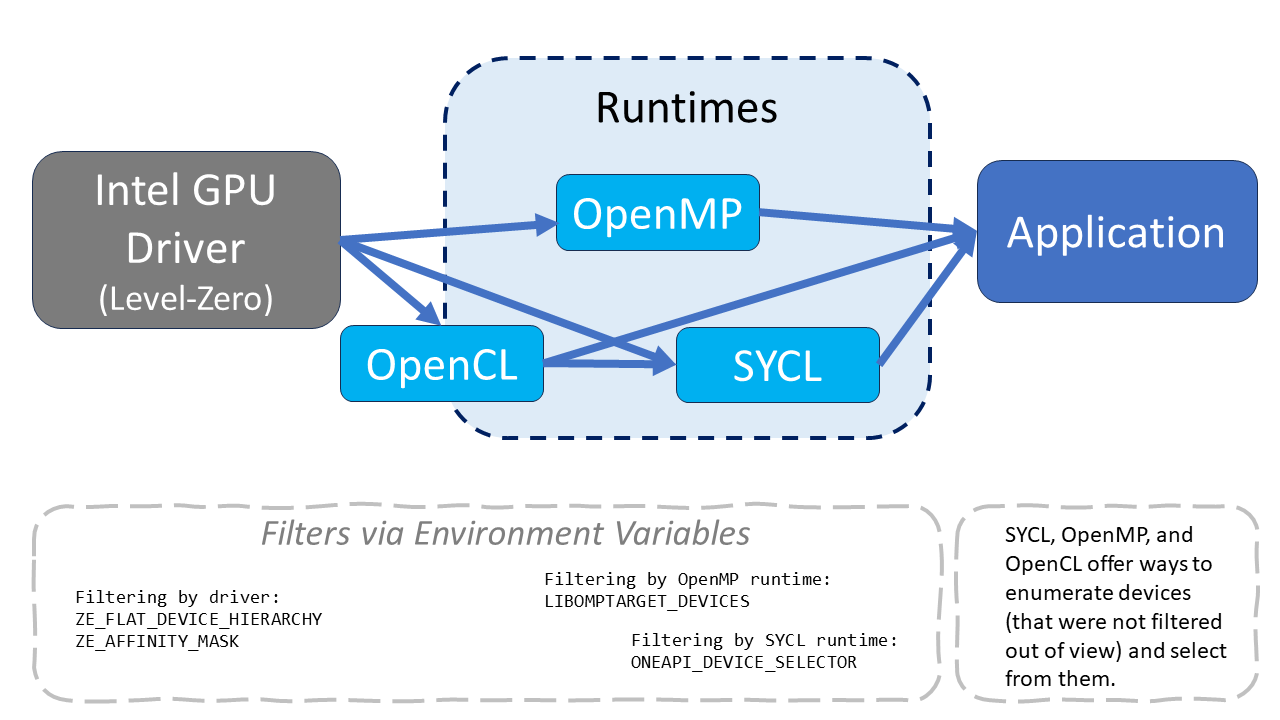
Environmental Variables for the GPU Driver
The Level Zero driver implements two environment variables of interest to us:
- ZE_FLAT_DEVICE_HIERARCHY
- ZE_AFFINITY_MASK
These are both documented in the Level Zero Specification documentation for Environment Variables.
ZE_FLAT_DEVICE_HIERARCHY
The default mode has shifted (phased in during late 2023) from COMPOSITE to FLAT mode. This works better for programs that have previously been tuned for single-tile architectures. It also supports that approach better than COMPOSITE mode without requiring application code changes for multitile architectures. Setting ZE_FLAT_DEVICE_HIERARCHY=FLAT selects explicit scaling, where the devices seen by an application will be sub-devices. Applications that use multiple devices will often see better performance results using this mode since it minimizes the asymmetry that cross-tile communications would introduce in the default mode.
If we set ZE_FLAT_DEVICE_HIERARCHY=COMPOSITE, our application will see a hierarchy that reflects the actual internals of the hardware – in a mode called implicit scaling. Each “root” device (a physical device in general) will appear as a device, possibly with sub-devices. The advantage here is that when a program uses a device, it will effectively see that device as large as it can be. This is particularly useful for programs that only try to use a single device. A possible disadvantage comes from any asymmetries present when spreading work uniformly across multiple tiles in a device. Depending on the algorithms used in an application, this may not scale as well as using FLAT mode (next option). Fortunately, we can try both and see which we prefer based on actual results!
NOTE: For best performance, we cannot assume what the default is for ZE_FLAT_DEVICE_HIERARCHY. Instead, we should purposefully set it in our environment. Most likely, the default will be FLAT for the foreseeable future. While it was COMPOSITE originally (the change to FLAT was phased in during Q4 2023), the trend to growing device sizes (thanks to massively multitile approaches to packaging) has favored the default becoming FLAT to best match common programming methods used by default.
ZE_AFFINITY_MASK
We will use ZE_AFFINITY_MASK only when we do not want to use all the devices in a system. If we want our application to see all devices, then we will not use ZE_AFFINITY_MASK (although we can if we just specify all the devices). The format of ZE_AFFINITY_MASK depends on the setting of ZE_FLAT_DEVICE_HIERARCHY.
The mask is simply a list of devices we do want our application to “see.”
If we have ZE_FLAT_DEVICE_HIERARCHY set to COMPOSITE, we can have an AFFINITY of “1” for our application to only see device #1 – making system devices 0, and 2+, invisible. Of course, the application will think of the exposed device as logical device #0 (it has no idea we hid anything). We can also choose to limit ourselves to a single tile by setting affinity to “0.1” which would expose a single device that was really only using tile #1 on system device #0. In COMPOSITE mode, the numbers are specified in ZE_AFFINITY_MASK using a device[.sub-device] numbering. The only way to expose a single tile as a device using COMPOSITE mode is to mask to only a single tile in a device. As soon as our list specifies more than one tile in a device it will be combined in a way that is consistent with the intent of the COMPOSITE mode. If we want an arbitrary collection of tiles all presented as devices, we want the FLAT mode.
If we have ZE_FLAT_DEVICE_HIERARCHY set to FLAT, we can have an ZE_AFFINITY_MASK of “1” for our application to only see the second tile in the system as logical device #0. If the system has four dual-tile GPUs installed, this would be the second tile in the first GPU. In FLAT mode, the numbers use a system-wide-sub-device-number from a flat numbering perspective. Therefore, we could use the second tile in each of four dual-tile GPUs with ZE_AFFINITY_MASK=1,3,5,7.
Additional examples to illustrate this are in the detailed documentation for ZE_AFFINITY_MASK.
Open source is great. The open discussion that arrived at adding this support, along with insights into why this was needed, are all open and visible as “Expose sub-device exposed by ZE_AFFINITY_MASK” in Expose sub-device exposed by ZE_AFFINITY_MASK as devices and Add support for flexible device hierarchy model.
Environmental Variables for the Runtimes
In the prior discussion, I said those environment variables affected what our application would see. It would have been more correct to say “what the runtimes will see” since there are also runtime options to prune even more devices at the runtime level.
C++ with SYCL and OpenMP users can use ONEAPI_DEVICE_SELECTOR=level_zero:*.* to achieve the same results on systems with multi-tile GPUs as using ZE_FLAT_DEVICE_HIERARCHY=FLAT.
OpenMP users can use LIBOMPTARGET_DEVICES=SUBDEVICE to achieve the same results on systems with multi-tile GPUs as using ZE_FLAT_DEVICE_HIERARCHY=FLAT.
ONEAPI_DEVICE_SELECTOR
The ONEAPI_DEVICE_SELECTOR environment variable is used to limit the choice of devices available when an application using OpenMP or C++ with SYCL is run. It can limit devices to a certain type (like GPUs, CPUs, or other accelerators) or backends (like Level Zero or OpenCL). The many variations for specification are covered in the oneAPI environment variable documentation.
OpenMP – many options
I shared the LIBOMPTARGET_DEVICES=SUBDEVICE above, but consistent with the richness of OpenMP there is a non-trivial set of controls for affinity and device choices. They are all covered in the OpenMP environment variable documentation. It is worth surveying the capabilities of LIBOMPTARGET_DEVICES, LIBOMPTARGET_DEVICETYPE, LIBOMPTARGET_PLUGIN, OMP_TARGET_OFFLOAD, GOMP_CPU_AFFINITY, KMP_HW_SUBSET, and OMP_DEFAULT_DEVICE.
In Our Applications
While I will not explain application-level possibilities here, it should be noted that applications using OpenMP and C++ with SYCL have the ability to filter further by being selective in which device(s) they actually use.
OpenMP users should start with Offload Target Control Pragmas.
C++ with SYCL users should look at Chapter 12 of the Data Parallel C++ with SYCL book (a free download) combined with the ability to split devices into sub-devices.
Summary
The performance and capabilities of an application may be affected by the hierarchy with which it is presented. Fortunately, there are a rich collection of options to select the best choice for our application. These options also allow us to run multiple applications concurrently with full control over whether they utilize the same resources or not. The choice is ours.
These options are easy to try, so it is worthwhile to experiment with them to very which combinations give your application(s) the best results.