Overview
Identifying the face of a person to grant access to an application is a recent trend. Facial recognition has become a popular method to unlock phones, tag people on social media, and scan crowds for security threats. It has also gained popularity in gaming, grocery stores, airports, and payment platforms. Facial-recognition login software and biometric technology have set a new standard in security-relevant applications because they eliminate the need to remember passwords without compromising security. Further, facial recognition login can also detect and verify people's faces, regardless of whether they changed their appearance (a new mustache, for example) or are wearing eyeglasses.
According to FaceNet: A Unified Embedding for Face Recognition and Clustering, "FaceNet is a system that directly learns a mapping from face images to a compact Euclidean space where distances directly correspond to a measure of face similarity. Once this space has been produced, tasks such as face recognition, verification and clustering can be easily implemented using standard techniques with FaceNet embeddings as feature vectors."
In addition to the actual face recognition process, which is done by FaceNet, we can add a face alignment stage beforehand. This aligns the face to help improve the recognition accuracy. The addition of this face alignment stage requires FaceNet to perform postprocessing techniques to match the face being viewed with other known faces.
The optimized solution described in this paper is based on the Intel® Distribution for OpenVINO™ toolkit, which can optimize trained models in frameworks like Tensorflow*, Caffe*, and PyTorch*, and then quickly infer.
The FaceNet model discussed here was converted to an optimized intermediate representation (IR) with the help of the Intel Distribution for OpenVINO toolkit and was then used to infer at a higher speed. The experiment was conducted on the Intel® Xeon® Platinum 8256 processor (at 3.80 GHz).
Solution Architecture and Design
The original solution uses a FaceNet model trained on custom images to recognize faces. As the diagram below shows, preprocessing involves face alignment. Postprocessing involves interpreting the feature vector returned by the FaceNet model and matching it against feature vectors of known faces using a distance measure utility.
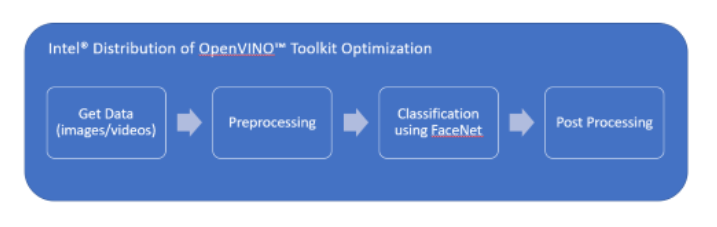
The optimized solution uses the Intel Distribution for OpenVINO toolkit to optimize the FaceNet model using the Model Optimizer tool, which creates an IR of the model. The IR representation, in the form of .xml and .bin files, is used to infer using a classification-inference engine sample from the Intel Distribution for OpenVINO toolkit. The usual postprocessing done in the sample is discarded because the feature vector from the FaceNet stage is directly fed to the postprocessing for the solution. The inferred feature vector is matched against an existing set of feature vectors using the distance measure to correctly identify the faces.
The IR conversion is done on the FaceNet model, as shown in the following example. See the OpenVINO toolkit documentation for code example details.
python /deployment_tools/model_optimizer/mo_tf.py>
--input_model \
--output \
--freeze_placeholder_with_value "phase_train->False"
A snippet of the classification sample source code from the Intel Distribution for OpenVINO toolkit is shown below:
# Start sync inference
log.info("Starting inference ({} iterations)".format(args.number_iter))
infer_time = []
for i in range(args.number_iter):
t0 = time()
res = exec_net.infer(inputs={input_blob: images})
infer_time.append((time()-t0)*1000)
log.info("Average running time of one iteration: {} ms".format(np.average(np.asarray(infer_time))))
if args.perf_counts:
perf_counts = exec_net.requests[0].get_perf_counts()
log.info("Performance counters:")
print("{:<70} {:<15} {:<15} {:<15} {:<10}".format('name', 'layer_type', 'exet_type', 'status', 'real_time, us'))
for layer, stats in perf_counts.items():
print("{:<70} {:<15} {:<15} {:<15} {:<10}".format(layer, stats['layer_type'], stats['exec_type'],
stats['status'], stats['real_time']))
# Processing output blob
log.info("Processing output blob")
res = res[out_blob]
The remainder of the classification sample is skipped because the feature vector obtained in the res variable (line 6) is directly fed into the inference for distance calculations.
Hardware Configuration
Table 1 lists the hardware configuration for the optimized and non-optimized versions of the solution.
Table 1. Hardware configuration for the solution
| Platform | Intel® Server Board S2600BPB |
| # Nodes | 1 |
| # Sockets | 2 |
| CPU | Intel® Xeon® Platinum 8256 processor @ 3.80 GHz |
| Cores/socket, Threads/socket | 4/8 |
| ucode | 0x500001c |
| Hyperthreading (HT) | On |
| Turbo | On |
| BIOS version | SE5C620.86B.02.01.0008.031920191559 |
| System DDR memory configuration: slots / cap / run-speed | 12 slots / 32 GB / 2666 MTs / DDR4 DIMM |
| Total memory/node (DDR+DCPMM) | 376 GB |
| Storage - boot | Intel® Solid State Drive SC2KB48 480 GB (1 GB boot partition) |
| Storage - application drives | Intel® Solid State Drive SC2KB48 480 GB (444 GB application partition) |
| Network interface controller (NIC) | Intel® Ethernet Controller 10 Gigabit X550T |
| Platform controller hub (PCH) | Intel® C621 chipset |
| OS | Ubuntu* 18.04.2 LTS |
| Kernel | Linux* 4.15.0-48-generic |
| Mitigation variants (1,2,3,3a,4, L1TF) | Full mitigation |
Software Configuration
Table 2 lists the software used (and their versions) in the baseline and optimized solution.
Table 2. Software configuration for the solution
| Software | Baseline | Optimized |
| Workload | Custom FaceNet | Custom FaceNet |
| Compiler | n/a | n/a |
| Libraries | Intel® Math Kernel Library (Intel® MKL) 2019.3, NumPy 1.16.13, scikit-learn* 0.20.3, Pillow 6.0.0 | Intel MKL 2019.3, NumPy 1.16.3, scikit-learn 0.20.3, Pillow 6.0.0 |
| Frameworks version | TensorFlow* 1.13.1 (installed using conda*) | Intel Distribution of OpenVINO toolkit R1.133 |
| Python* | Python 3.6.8 | Python 3.6.8 |
| Dataset | Custom | Custom |
| Topology | Custom FaceNet | Custom FaceNet |
| Batch Size | 1 | 1 |
| Streams | 1 | 1 |
Results
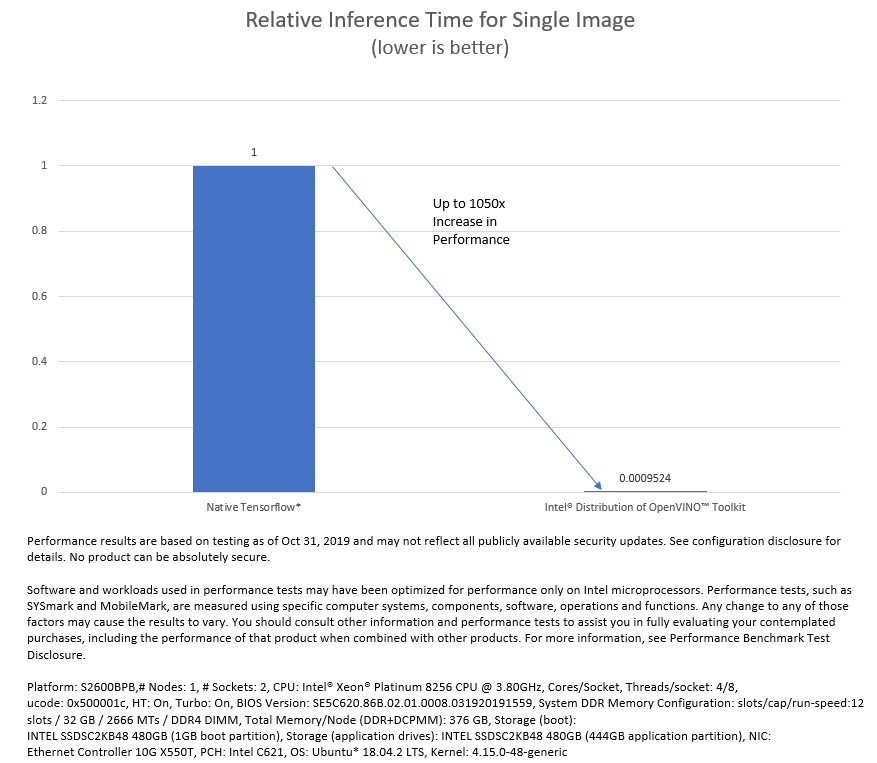
The time for FaceNet topology to infer a single image improved by 1050x. This measure does not consider preprocessing and postprocessing times. With more images, the margin slightly decreases. However, the Intel Distribution of OpenVINO toolkit version also performed significantly better than native TensorFlow inferences in such cases. Because face login applications process one image at a time, a single-image comparison holds good for the comparison.
Conclusion
The inference time for FaceNet showed a 1050x improvement in time with the Intel Distribution of OpenVINO toolkit when compared to the native TensorFlow inference. Because of the optimization and resultant performance gains (less time), inference is a negligible part of the total processing of an image. The optimized solution had no impact on the recognition accuracy, and the feature vector returned in both the optimized and non-optimized versions were nearly identical. Further performance can be achieved by taking advantage of INT8 optimization coupled with Intel® Deep Learning Boost.
References
FaceNet: A Unified Embedding for Face Recognition and Clustering
Intel® Distribution of OpenVINO™ Toolkit
GitHub - davidsandberg/facenet