Introduction
A virtual machine (VM) is a compute resource that uses software instead of a physical computer to run programs and deploy apps. One or more virtual “guest” machines run on a physical “host” machine. Chromebooks support Android OS, Windows OS, Arch Linux OS, and Debian Linux OS as virtual machines in ChromeOS. These deployments are sandboxed and hence provide additional security for applications running in ChromeOS. Crosvm is the ChromeOS virtual machine monitor written from the ground up to run lightweight, secure, and performant VM’s. Crosvm [1] is a lot like VirtualBox or QEMU, except for the fact that it’s written in a memory-safe language (RUST [2]) and runs untrusted operating systems along with virtualized devices.
In a virtualized environment, the workload's performance is comparatively lower than the native performance. In the above VM environment, the average performance gap was 5% to 20% on various workloads compared to native due to paravritualized support for devices.
Our work aims to provide better user experience and performance for Android applications by optimizing the instruction flow in the Crosvm module. In this paper, we present the performance gains achieved by supporting profile-guided optimization (PGO) and improved decoded ICache coverage for the Crosvm module (virtual machine monitor).
Our assessment results exhibit that our implementation has achieved the following:
- Improved performance by 2% to 6% in creation / storage / AI ML Android workloads
- Improved performance by 15% to 80% in Android productivity applications using PGO,
- Improved ARCVM (Android OS in VM) workloads by 2% to 4%
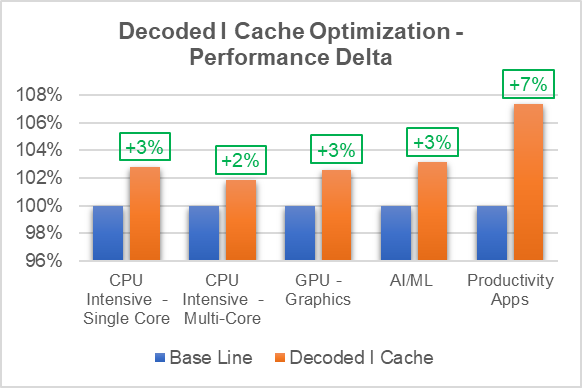
- Reduced cache misses by ~5% by improving decoded ICache coverage.
The overall VM performance gap with native was reduced by 2% to 4% with the above optimizations for various workloads.
Motivation
The virtual machine manager (VMM) or hypervisor, is one of many hardware virtualization techniques that allow multiple operating systems, referred to as guests, to run concurrently on a host computer. It is so named because it is conceptually one level higher than a supervisory program. The hypervisor presents to the guest operating systems a virtual operating platform and manages the execution of the guest operating systems. Multiple instances of a variety of operating systems may share the virtualized hardware resources.
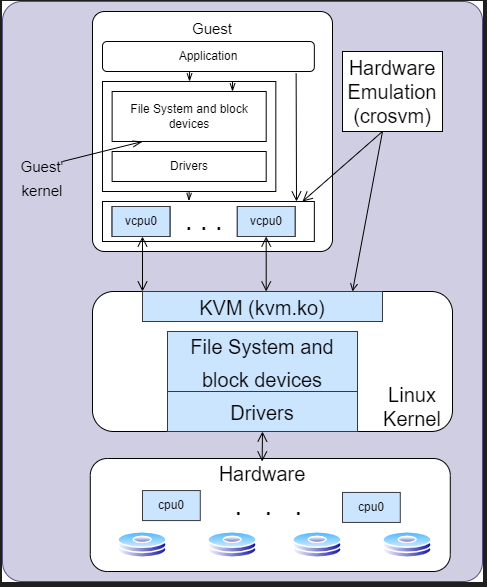
As shown in Figure 1, Crosvm is a VMM, or Type 2 hypervisor that runs entirely in user space and works in tandem with the KVM’s kernel component to set up and execute VMs. Crosvm defines the virtual hardware platform and memory layout of a VM, manages the execution lifecycle of the VM, and most importantly for this article, implements the logic required to handle the device accesses that KVM cannot handle. A kernel-based virtual machine (KVM) is a virtualization module in the Linux kernel that allows the kernel to function as a hypervisor.
Crosvm Optimization 1: Profile-Guided Optimization
Profile-guided optimizations (PGO) [3] is a technique that existed for several years in all major compilers. It collects the profile information or execution pattern of your program, then recompiles the binary by feeding the compiler with profiling feedback. The compiler uses this information to generate a faster binary.
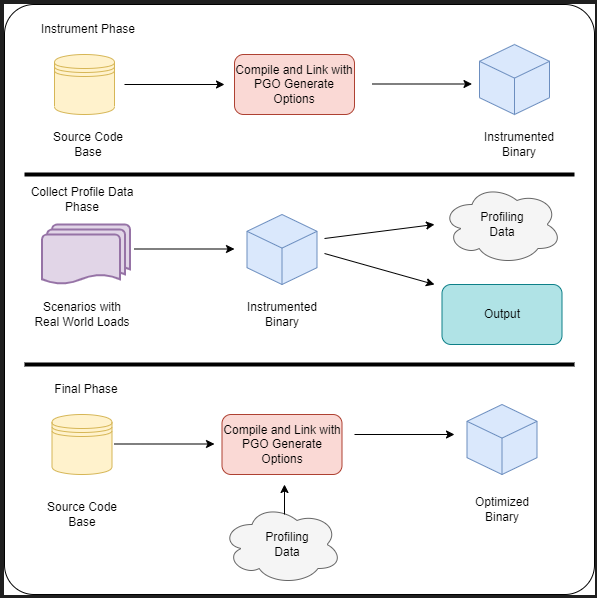
Figure 2 illustrates the following steps:
- In the instrument phase, the program is compiled with PGO-generate options. The produced binary is instrumented in a special way to generate profile information.
- In the collected profile data phase, the binary should be executed with real use cases. It is important to use realistic use cases as bad input can make your program run more slowly.
- As a result of the previous step, the binary creates a file with profile information. It records all function calls, executed for loops, if statements, etc. All the steps of the program are recorded in the profile information.
- In the optimize phase, the program is recompiled with PGO-use options. The compiler uses the profiled information file from the previous step during compilation to create an optimized binary.
This workflow has several advantages over manual tuning: code remains readable and maintainable. If the assumptions are incorrect, it is much easier to replace the data for the input than it is to modify the source code. As mentioned above, the Crosvm binary is developed using the RUST programming language. The steps/options to enable PGO in Crosvm are shown below.
- Compile with instrumentation enabled (with –Cprofile generate=/tmp/pgo-data).
- Profile Crosvm to improve runtime performance of ARCVM and Crostini Workloads.
- Run the instrumented program, which generates a default_<id>.profraw file.
- Convert the .profraw file to a .profdata file using the llvm-profdata tool.
- Run the program again, this time making use of the profiling info (with –Cprofile-use).
The performance results of enabling PGO in the Crosvm module is shared in the Results section.
Crosvm optimization 2: decoded ICache [4] coverage
The micro-op (lower-level instructions) queue can get micro-ops from the following sources: a) Decoded ICache, b) Legacy decode pipeline and c) microcode sequencer (MS). Refer to Figure 3 below.
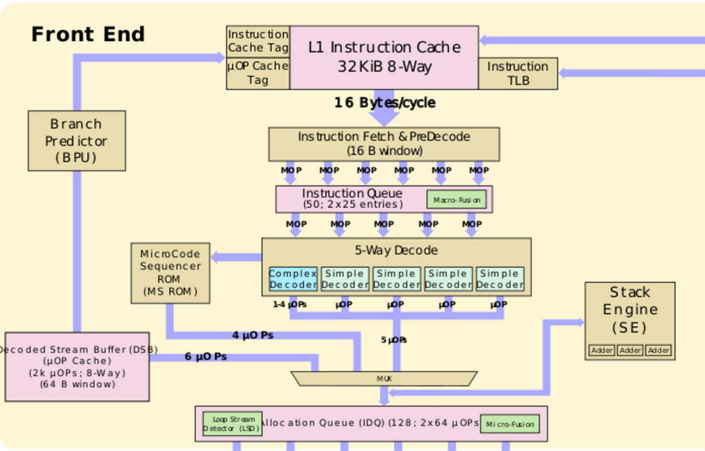
The decoded ICache is essentially an accelerator of the legacy decode pipeline. This cache stores micro-ops (μops) that have already been decoded, avoiding many of the penalties of the legacy decode pipeline. The next time the processor accesses the same code, the decoded ICache provides the μops directly, speeding up program execution.
Improving decoded ICache hits
As recommended by the Intel® Software Optimization Manual, we can aim to improve the decoded ICache coverage to be closer to 80%. But there are some prerequisites for a decoded ICache hit:
- There can be no partial hits in the decoded ICache.
- uOPS must be in a 32-byte aligned window.
- Only three ways are allowed per 32 Byte window.
- Entry to a DSB must be an unconditional branch.
- If LSD is enabled, all uOps must be in DSB.
- DSB can hold only two branches in a way.
- JMP must not cross or end on the 32-byte boundary.
Here are the primary reasons for missing micro-ops in the decoded ICache:
- Portions of a 32-byte chunk of code were not able to fit within three ways of the decoded ICache (“code alignment”).
- The “hot” portion of your code section is too large for the decoded ICache.
- The decoded ICache is getting flushed, such as when an ITLB entry is evicted.
- The front-end incurs a penalty as a uOp issue switches from the DSB to the MITE.
- The “DSB Switches” metric measures this penalty.
To effectively use µop cache, the code/branches should be aligned to 32 Bytes. In addition, the smaller loops (iterative code) can be stored in decoded ICache. Here are the RUST compiler flags that help improve decoded ICache coverage:
● unroll-threshold=300
● align-all-nofallthru-blocks=5
● x86-branches-within-32B-boundaries.
The performance results of enabling compiler flags for improving decoded ICache coverage in the Crosvm module are shared in the Results section.
Results
Our evaluation platform is an Asus Chromebook, which uses an 11th Gen Intel® Core™ i7-1165G7 @ 2.80GHz processor with 8 cores. The processor base frequency is 2.8 GHz and can reach up to 4.7 GHz in Turbo mode. The memory available in the device is 16 GB. ChromeOS version R93 with Android R is loaded in the device. We have ensured that “Internet Speed Test” is executed before collecting the data to confirm that the internet bandwidth is the same while executing the tests. The apps are side loaded to the system and tests are applied. For all performance and power assessment, the median of three iterations is used with variance removed.
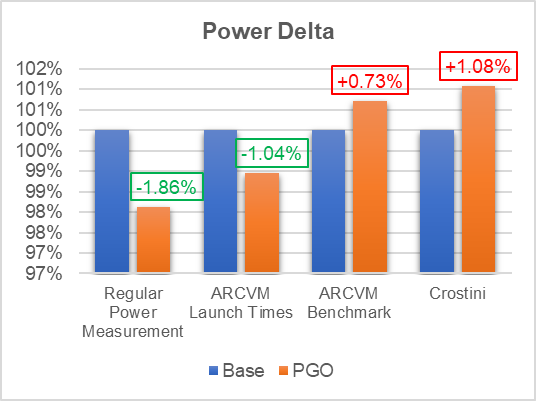
In our analysis, we selected different kinds of workloads to generate, such as the profraw file that exercises the complete paths in the Crosvm module for PGO. Later, the profraw file was included in the release binary of Crosvm. By Implementing profile-guided optimization, we have obtained significant performance gains in ARCM workloads (refer to Figure 3: Benchmark Results and Figure 4: Productivity App Results) with no impact in power (refer to Graph 5: Power Results).
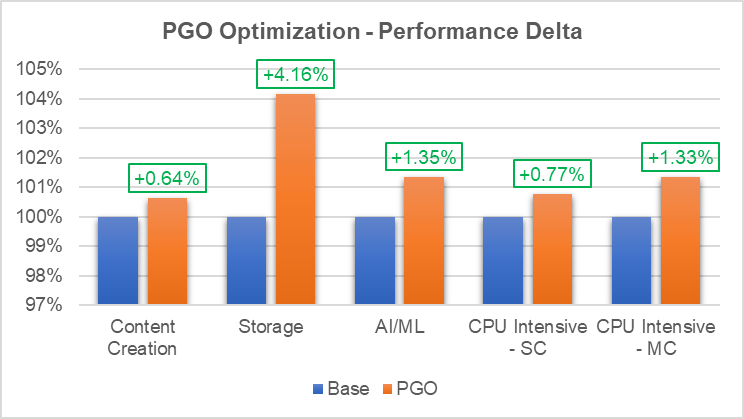
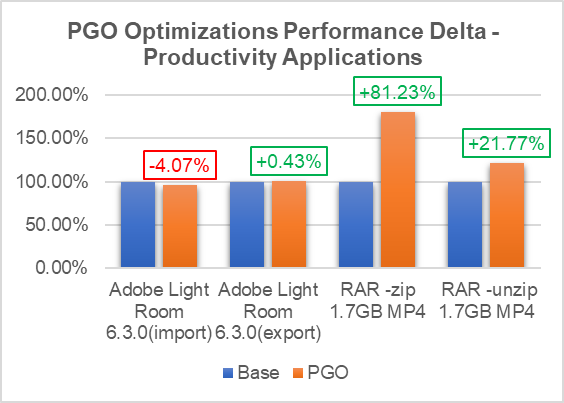
By introducing the align-all-nofallthru-blocks, the x86-branches-within-32B-boundaries, and the unroll-threshold=300 compiler flags in the RUST environment to compile Crosvm module, the performance results shown below were obtained by the improving decoded ICache:
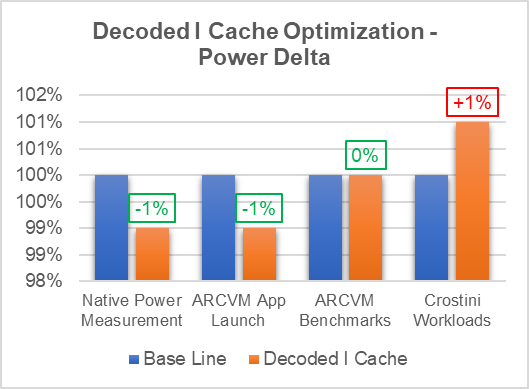
Created additional profiles to study the Decoded I Cache improvement by monitoring the below performance counters: Refer to the table below that provides information on Decoded I Cache Improvement percentage.
| Base Line - Performance Counters | With Optimization to Improve Decoded ICache Coverage - Performance Counters |
|
| Benchmarks | Decoded I Cache (%) | Decoded I Cache (%) |
| GeekBench | 17% | 19% |
| Mlx-Bench | 14% | 16% |
| RAR-unzip* | 27% | 36% |
*RAR-unzip – Unzipping video file using RAR
Note: Formulae for computing Decoded I Cache Coverage:
ALL_IDQ_UOPs = idq.dsb_uops+idq.ms_uops+idq.mite_uops
Decoded I Cache Coverage (%) = idq.dsb_uops/ ALL_IDQ_UOPs
Summary
In this paper, we outlined the VM performance gap compared to native, and the experiments carried out to support profile-guided optimizations, improving decoded ICache and their performance, and the power impact on workloads executed in VM on ChromeOS.
Our implementation has achieved a 2% to 6% performance content gain in creation / storage / AI ML Android workloads, a 15% to 80% gain in Android productivity applications using PGO, and a 2% to 4% improvement in ARCVM (Android OS in VM) workloads with a reduction of ~5% of cache misses by improving decoded ICache coverage. The overall VM performance gap with native was reduced by 2% to 4% with the above optimizations.
These optimizations are under review by Google, and they are in process of being integrated in ChromeOS. Subsequent work in this area is to support improving decoded ICache compiler flags in the entire ChromeOS tool chain and support PGO optimizations in Android OS and ChromeOS.
About the authors
This article was written by Jaishankar Rajendran, Prashant Kodali and Biboshan Banerjee.
Jaishankar Rajendran and Prashant Kodali are members of the CCG CPE Chrome and Linux Architecture Department and Biboshan Banerjee is a member of the Android Ecosystem Engineering Department.
Thanks to Bodapti Shalini Salomi, Priyanka Bose, Shyjumon N, Sajal K Das, Erin Park, Mahendra K Reddy, and Vaibhav Shankar for their support and guidance in reviewing this article.
Notices and disclaimers
Tests document performance of components on a particular test, in specific systems. Differences in hardware, software, or configuration will affect actual performance. Consult other sources of information to evaluate performance as you consider your purchase. For more complete information about performance and benchmark results, visit www.intel.com/benchmarks.
Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
© 2022 Intel Corporation. Intel, the Intel logo, Intel Core, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Test configuration
Software: Android 11.0, OpenGL ES 3.1 Mesa Support
Hardware: Asus Chromebook, Intel® Core™ i7-1165G7 processor, 4 Core 8 Threads, 16 GB Ram
Intel technologies’ features and benefits depend on system configuration and may require enabled hardware, software or service activation. Performance varies depending on system configuration. No computer system can be absolutely secure. Check with your system manufacturer or retailer or learn more at www.intel.com.