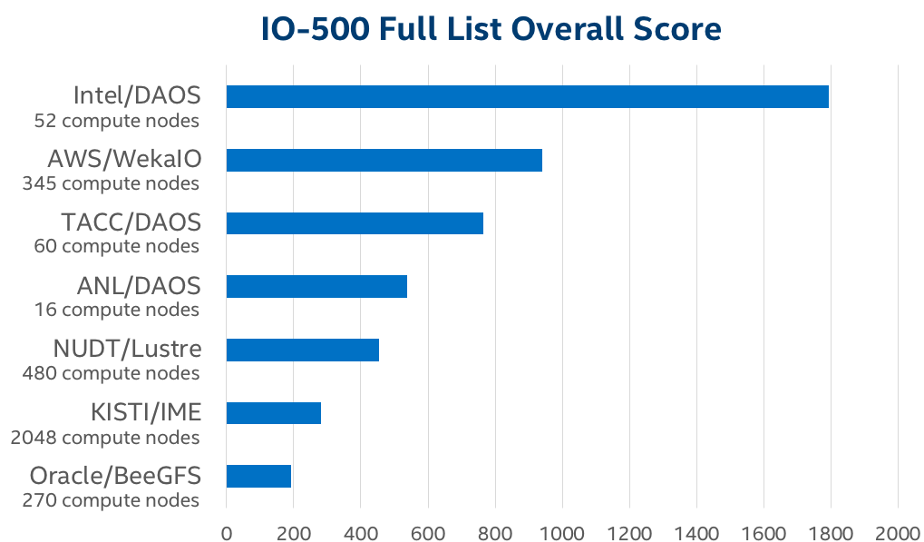
We are excited to announce a new world record for filesystem performance in the International Supercomputing 2020 IO500 list using only 30 storage servers equipped with 2nd Gen Intel® Xeon® Platinum processors and Intel® Optane™ persistent memory (PMem) running Distributed Asynchronous Object Storage (DAOS), beating today’s best supercomputers and ranking #1. The IO500 ranks the top file systems in the world based on balanced industry benchmarks so the industry can better compare the performance of different systems and technologies. This performance is made possible due to the unique hardware capabilities of Intel® Optane™ PMem, combining low-latency byte-granular memory access with data persistence for small I/Os, and the new DAOS software stack built from the ground up to leverage these capabilities. This year, we were pleased to be joined by two customers, Texas Advanced Computing Center (TACC) and Argonne National Laboratory (ANL), who also contributed IO500 submissions using DAOS with Intel® Optane™ PMem, and secured positions #3 and #4 on the list, respectively.
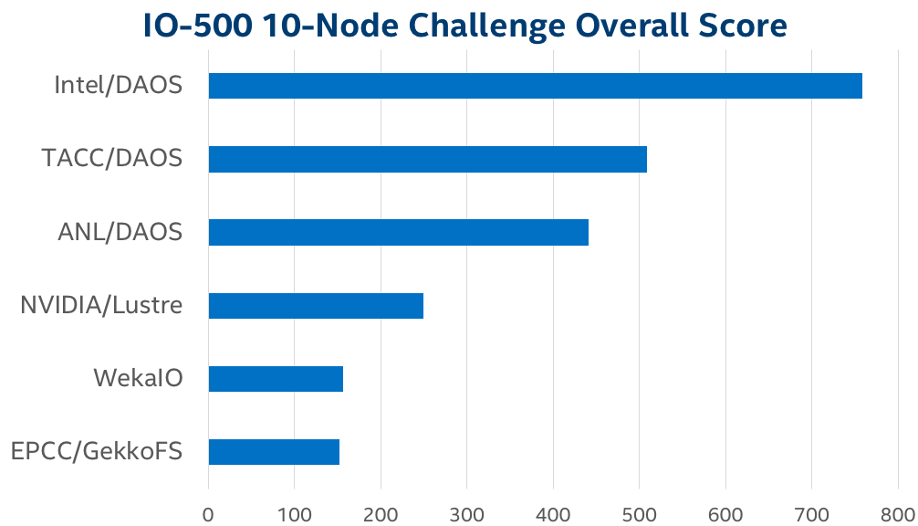
The IO500 has an additional 10-node challenge, where all entries must have exactly 10 clients, enabling a more direct comparison of filesystem efficiency and per-server performance. In the 10-node challenge, the three systems equipped with 2nd Gen Intel® Xeon® Scalable processors, Intel® Optane™ PMem and the DAOS file system took all top-3 rankings, and set a new bar for storage performance, with the first-place submission scoring more than three times the top competing non-DAOS system.
All-Flash Storage architectures are evolving towards hybrid, tiered models. For many designs today, that includes a combination of high-performance Intel® Optane™ SSDs and high-capacity NAND based SSDs. However, the block interfaces in the existing storage software stacks of all SSDs and HDDs present fundamental limitations to IO performance that DAOS with Intel® Optane™ PMem improve upon. Let’s take a quick look at what happens to our application’s data as it is converted to blocks. Consider the below diagram.
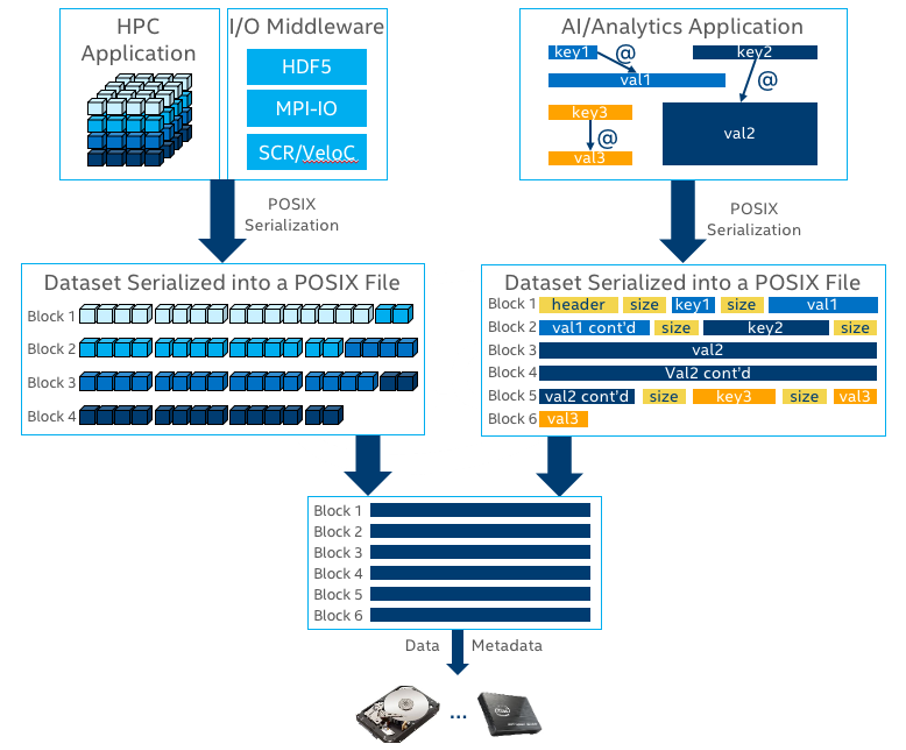
First, on the top, a traditional HPC modeling and simulation application, represented by the three-dimensional matrix to the left. This application may use a layer of middleware to do its I/O, such as HDF or MPI-IO. Below it, an AI or Data Analytics application, which may store its data in a semi-structured or unstructured manner – such as a key:values, or perhaps a more domain specific data structure that preserves semantic meaning of the data. There are several middleware options for AI and Analytics applications as well, such as Apache Spark and Tensorflow. In either case, the application, or middleware, must take all the data and convert that data into a series of blocks. When the data does not perfectly align with the size of the block, now we have a choice – either leave a portion of a block empty, which will over time waste a huge amount of capacity for the system, or combine it with another piece of data so that we can utilize the whole block.
For large I/Os, this is not as much of an issue – we can more easily well-utilize the blocks. But for small I/Os, such as file metadata, we may have to combine several pieces of data into a single block. Or, if an application is generating I/O that is unaligned to the blocks, as real applications do, we’ll also end up with different data sharing blocks.
Now, when an application needs to have a lock on one piece of that data, it’s going to have to lock the entire block on which that data resides, or more than one block, if the piece of data is split across multiple blocks. If the application, whether from the same client or a different client, needs to lock a different piece of data that resides in the same block, it has to wait for the first activity to complete, effectively serializing the actions. Build millions of these interactions over time, and you are losing a lot of performance waiting for blocks to be free. The more data you have cohabitating in the same blocks, the bigger a problem this creates on your cluster.
As the data explosion continues to expand, this bottleneck will become a more and more serious problem. With the continued rise of AI and data analytics, there will be more small and unaligned I/O on storage systems than ever and at the same time data access time will be more critical than ever. Enter Intel® Optane™ Persistent Memory, which combines low-latency and byte-addressable data access with persistence. For the first time in decades of storage technology development, storage systems do not have to be constrained by block-based IO.
But, the existing distributed storage software of today is a bottleneck, optimized for storage media with latency measured in milliseconds, and built around POSIX standards. The performance impact of these software bottlenecks is so dramatic, they leave the majority of the performance benefits Optane™ PMem offer on the table. These shortfalls cannot be accounted for by tweaking existing solutions alone – instead, scale out storage needed to be re-built from the ground up for new non-volatile memory technologies. We at Intel have been building this new open source storage stack, including the Persistent Memory Development Kit (PMDK), Storage Performance Development Kit (SPDK), and DAOS, and these IO500 results demonstrate just how powerful this combination can be.
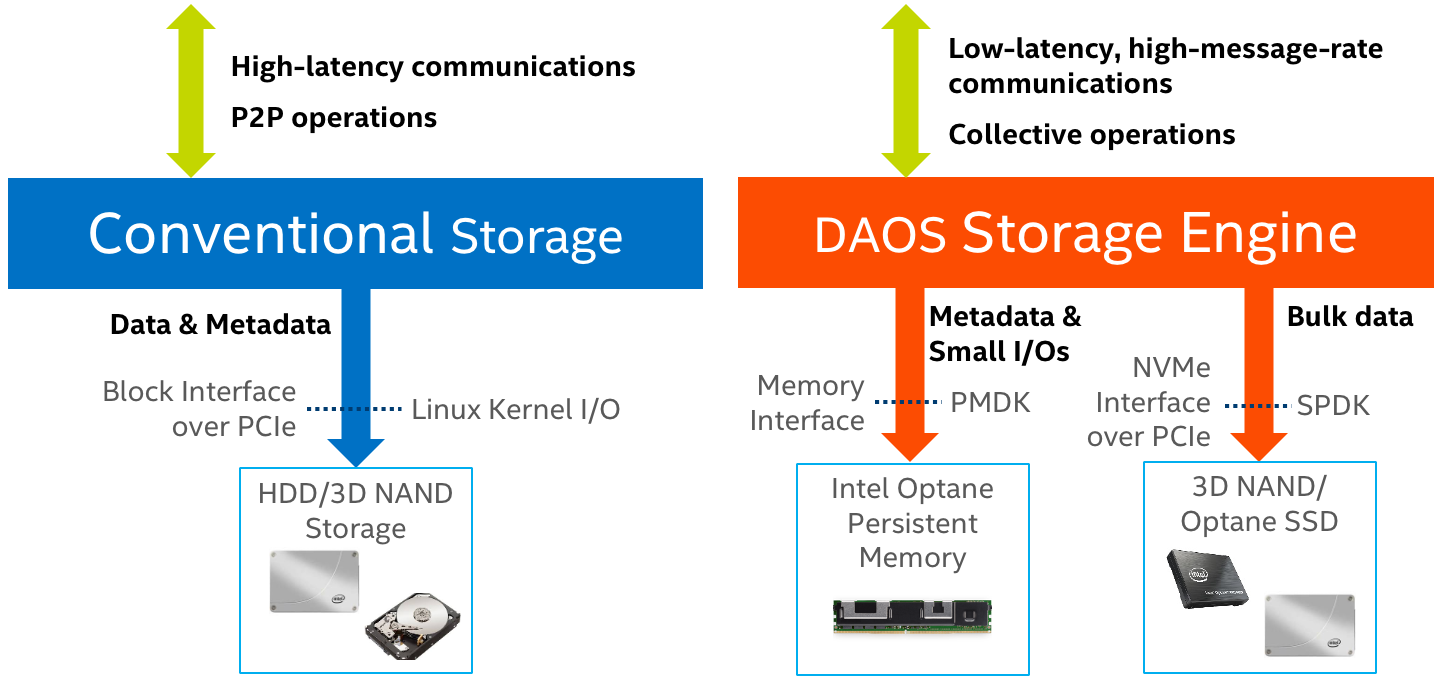
The DAOS architecture is built on two fundamental building blocks. For all small IO, including metadata, the IO is stored directly on Intel® Optane™ PMem. This is not a cache or buffer solution; the persistent memory is a first-class storage device. Larger, more block-friendly IO will be stored directly on the NVMe SSDs. This division, storing the small IO on the persistent memory while the large IO is stored on disk, is what enables DAOS to set new records for bandwidth and IOPs at arbitrary alignment and size, with significantly fewer systems, while still offering an attractive performance per dollar.
DAOS additionally breaks through other common industry bottlenecks, improving the performance even further. DAOS is entirely in userspace, utilizing the PMDK and SPDK open source libraries, not only bypassing the performance limitations of I/O through the kernel, but also alleviating other issues such as jitter, ease of administration, etc. DAOS also breaks free from the performance limitations of the POSIX interface, relying on the more performant optimistic concurrency control rather than the pessimistic concurrency control of POSIX. While applications can still use POSIX over DAOS, they are not limited to it.
All of this is done transparently to the end user – the application need not be conscientious of the tiering happening underneath within the DAOS servers. DAOS instead provides applications with a selection of interface options, such as the traditional POSIX interface or a key:value interface. Additionally, many common middleware and application frameworks have been enabled to run on DAOS. Applications using MPI-IO, HDF5, and Apache Spark can enjoy the full performance benefits of a DAOS back-end without having to re-write their applications. This list will continue to grow over time, with upcoming support for SEGY and ROOT formats as well.
This ecosystem is being cultivated so that there is a rich array of options for applications to gain the performance and other benefits of an Intel Persistent Memory DAOS solution, without having to significantly alter their applications. This enables a wide variety of applications to benefit, including modeling and simulation, life sciences and genomics, electronic devices and automation, financial services, AI solutions, high performance data analytics, and enterprise solutions.
DAOS 1.0 is newly released in June, targeted at partner integration and the DAOS Proof of Concept program. If you are interested in more information or test-driving Intel® Optane™ Persistent Memory with DAOS for yourself, please visit the resources below.
Resources:
-
DAOS Community Site: https://daos-stack.github.io/
-
Intel® Optane™ Persistent Memory: https://www.intel.com/content/www/us/en/architecture-and-technology/optane-dc-persistent-memory.html
-
IO500 [Virtual Institute for I/O]: https://www.vi4io.org/io500/start
-
Liang, Zhen & Lombardi, Johann & Chaarawi, Mohamad & Hennecke, Michael. (2020). DAOS: A Scale-Out High Performance Storage Stack for Storage Class Memory. 10.1007/978-3-030-48842-0_3: https://www.springerprofessional.de/en/daos-a-scale-out-high-performance-storage-stack-for-storage-clas/18042492?fulltextView=true
-
DAOS Solution Brief: DAOS Revolutionizes High Performance Storage: https://www.intel.com/content/www/us/en/high-performance-computing/