
oneAPI is an open specification (see oneapi.io) for accelerator programming that includes a language (SYCL* from The Khronos Group), standardized library interfaces (for neural networks, data analytics, and more), and a close-to-the-metal programming interface (Level Zero). oneAPI is designed to be hardware- and vendor-independent, and has already been demonstrated on CPUs, GPUs, FPGAs, and other accelerators from multiple vendors. oneAPI delivers a standards-based approach to programming that allows developers to unlock high performance without sacrificing portability across hardware and software environments.
oneAPI is made possible by a collection of multiple interoperable standards across many levels of the software stack. Some of these standards (like Level Zero and extensions to SYCL) are part of the oneAPI specification. Others (like SYCL and SPIR-V) are industry standards that provide the foundations for portable programming with oneAPI. Yet others (like OpenMP*, ISO C++, and ISO Fortran) describe alternative syntax for accelerator programming that can be layered on top of oneAPI.
Interoperability between all these standards is crucial, because large applications are very rarely written by a single developer working with a single language at a single level of abstraction. It’s much more common to use a mixture of different techniques, calling libraries written by other developers (e.g., an application written in Fortran and OpenMP using an optimized library written in SYCL). Maintaining interoperability requires constant effort, because it’s not uncommon for different standards to offer their own solutions to new problems. Different standards may target different levels of abstraction, may prefer different coding styles, and must always consider how any new functionality meshes with existing features and established conventions. But standards can still learn from one another, aligning around terminology and cross-pollinating features when appropriate.
Looking back at the last decade of SYCL, C++, and OpenCL* we can clearly see this process of alignment and cross-pollination in action (Figure 1). For example, OpenCL 2.0 adopted the concepts and terminology from the C++11 memory model, extending them with the notion of scopes and multiple address spaces. OpenCL 2.0 features like groups and group functions were then later combined with aspects of the C++17 parallel algorithms to produce SYCL 2020’s group algorithms library, allowing developers to use familiar C++ syntax to access vendor-optimized operations at multiple levels of the hardware hierarchy.
This is an ongoing process, and in our recent IWOCL submission — “Towards Alignment of Parallelism in SYCL and ISO C++” — we proposed some new clarifications to SYCL that are designed to bridge the gap between concepts like SYCL work-items and C++17 threads of execution. These clarifications make it easier to reason about the behavior of C++17 parallel algorithms layered on top of SYCL and are a necessary step towards allowing certain C++17 execution policies to work correctly on SYCL devices.
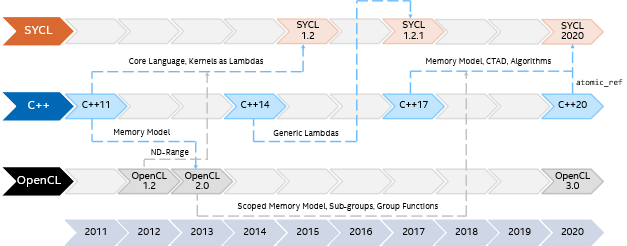
Figure 1. Parallel evolution of SYCL*, ISO C++ and OpenCL*
Looking forward, we see opportunities for SYCL to influence the future of heterogeneous programming in C++. We believe that implementers’ experiences with SYCL can and will feed directly into the design of new, high-level abstractions proposed for C++. But we also believe that SYCL will continue to play an important role for developers long into the future, providing direct access to lower-level and cutting-edge hardware features via mechanisms that are fully interoperable with relevant C++ abstractions.
What might that future look like? Although we can’t say for certain, there are a few ISO C++ proposals that hold some clues: P2300 (“std::execution”) and P2500 (“C++ parallel algorithms and P2300”). If these proposals are accepted — which won’t happen until 2026, at the earliest! — then it would become possible to write code like that in Figure 2.
Figure 2. A glimpse into a future that mixes C++ parallel algorithms and SYCL* with features proposed in P2300/P2500
For those of us who can’t wait until 2026, it’s already possible to mix C++ parallel algorithms and SYCL today using the oneAPI DPC++ Library (oneDPL). oneDPL is an open-source library that enables C++ parallel algorithms to execute on SYCL devices, providing a high-productivity solution to developing applications that can execute anywhere SYCL can. oneDPL also serves as a vehicle to explore possible future extensions to ISO C++—there are already efforts underway to standardize parallel range-based algorithms based on C++20 ranges, and to explore ways to represent asynchronous parallel algorithms. Submitting a C++ parallel algorithm to a SYCL device using oneDPL is straightforward and can be as simple as using a SYCL-aware execution policy (Figure 3). Using experimental features of oneDPL can unlock even higher levels of performance and productivity, by leveraging lazily evaluated views to enable kernel fusion (Figure 4).
Figure 3. Mixing C++ parallel algorithms and SYCL* using features available in oneDPL today
Figure 4. Mixing C++ ranges and SYCL* using experimental features of oneDPL
oneDPL’s current syntax may be a little different to where things end up eventually, but that’s simply the standardization process at work. Whatever ultimately lands in a future C++ standard will be the result of years of work, drawing on the experiences of multiple libraries and multiple hardware vendors, to establish common requirements and best practices.
We’re often asked whether developers should write their programs in OpenMP, SYCL, ISO C++, or ISO Fortran. The answer is simple: Yes! These are all valid approaches to heterogeneous programming, each with unique advantages and disadvantages, and combining these approaches has never been easier thanks to features like Fortran’s ISO_C_BINDING, OpenMP’s interop clause, and SYCL’s backend interoperability interface (Figure 5). The strong focus on interoperability between the standards at the heart of oneAPI enables us to embrace the ability to mix and match, using whichever combination of tools is best for the job at hand.
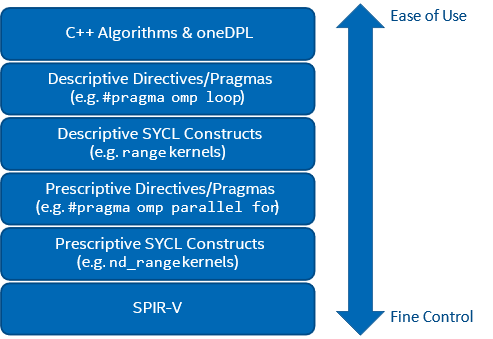
Figure 5. A comparison of approaches to heterogeneous programming: higher-level abstractions deliver a high-productivity solution to writing high-performance programs; lower-level abstractions provide direct control for expert developers