SimYog Technology Private Limited is a start-up in the Electronic Design Automation (EDA) space head-quartered in Bangalore, India. SimYog focues on providing “design and sign-off tools for automotive electronics”. SimYog’s vision is a harmonious integration of physical science and data science to enable cost-effective and performance-rich automotive electronics design through early-stage failure detection saving bill-of-materials, time-to-market and improving yield-rate.
SimYog is accelerated by the Intel India Startup Program, a coveted innovation platform for deep tech startups aimed at providing access to advanced technologies, enabling design and assistance to scale and Go To Market (GTM). As part of the engagement, SimYog leverages seasoned mentorship from Intel, connecting industry and ecosystem to validate and improve performance of its technology and create a real impact in the industry.
Compliance-Scope* (CompScope), a virtual laboratory for electromagnetic interference (EMI) and electromagnetic compatibility (EMC), is the flagship product from the SimYog. The tool ultimately solves a linear system of equations with order ranging around million unknowns. Highly optimized code and parallelization are the keys to enable such solutions for practical usage of the tool. Compliance-Scope uses Intel® Math Kernel Library (Intel® MKL) as a core math kernel and OpenMP* for parallelization.
To further take advantage of underlying hardware that supports Single Instruction Multiple Data (SIMD) parallelism, SimYog wanted to explore vectorization opportunities in the code. Applications need to be vectorized to take advantage of SIMD instructions and use the expanded vector width. The team used the Intel® C++ Compiler Classic to take advantage of advanced optimizations and the Intel® Advisor to identify potential bottlenecks and vectorize time-consuming loops/functions. This resulted in a performance speedup of 2x, reducing the standard time for completing simulation from 20 hours to 10 hours. This helped Compliance-Scope users expedite simulation-aided design for EMI/EMC.
Problem Statement
Electromagnetic compatibility (EMC) issues are becoming increasingly important with the growing electrification efforts in the automotive industry. Given the stringent EMC compliance requirements, a simulation tool that can do a system-level analysis and mimic the physical laboratory becomes an essential design-aid to reduce time to market of automotive components. Compliance-Scope (CompScope), a product of the SimYog Technology, is developed to do this. It helps a designer to validate and improve their hardware at an early stage by uploading their design files. CompScope currently supports four test methods: Conducted Emissions (CE), Conducted Immunity (CI), Radiated Emissions (RE), and Radiated Immunity (RI), which any automotive electronic product must go through to be deemed as compliant.
For the analysis, CompScope uses different types of electromagnetic solvers in the backend. The 3D Full-Wave Electromagnetic solver takes a major share in the total analysis time. The analysis involves setting up a matrix and solving a linear equation (Ax=b).
Optimizing the Code
The key objective of the engagement between SimYog and Intel was to vectorize and parallelize the CompScope application. The team used a combination of the Intel C++ Compiler Classic and the Intel Advisor to optimize the existing code.
The effort to improve CompScope performance included the following steps:
1. Code Porting.
First, the team ported the CompScope from the Microsoft Visual C++ Compiler* to the Intel C++ Compiler Classic for Windows* OS to enhance performance by leveraging advanced optimization techniques, SIMD vectorization, and loop and memory transformations. This also allowed for seamless integration with the Intel Advisor, which was used extensively for code optimization. Intel Advisor provides additional information when used with Intel compilers version 15.x or higher.
Porting resulted in a performance boost of 15% from Intel compiler optimizations.
2. Vectorization and Cache Optimization with Intel Advisor.
Vectorization is the technique used to compute simultaneously a set of values undergoing the same operation. To enable vectorization, you can use SIMD Instruction Set Architecture provided by the Intel® processors.
Intel Advisor is a tool that guides a user through vectorizing a loop/function, helps identify performance issues, and provides recommendations to fix it. Roofline analysis visualizes actual performance against hardware-imposed performance ceilings and helps to determine the main limiting factor (memory bandwidth or compute capacity), thereby providing an ideal roadmap of potential optimization steps.
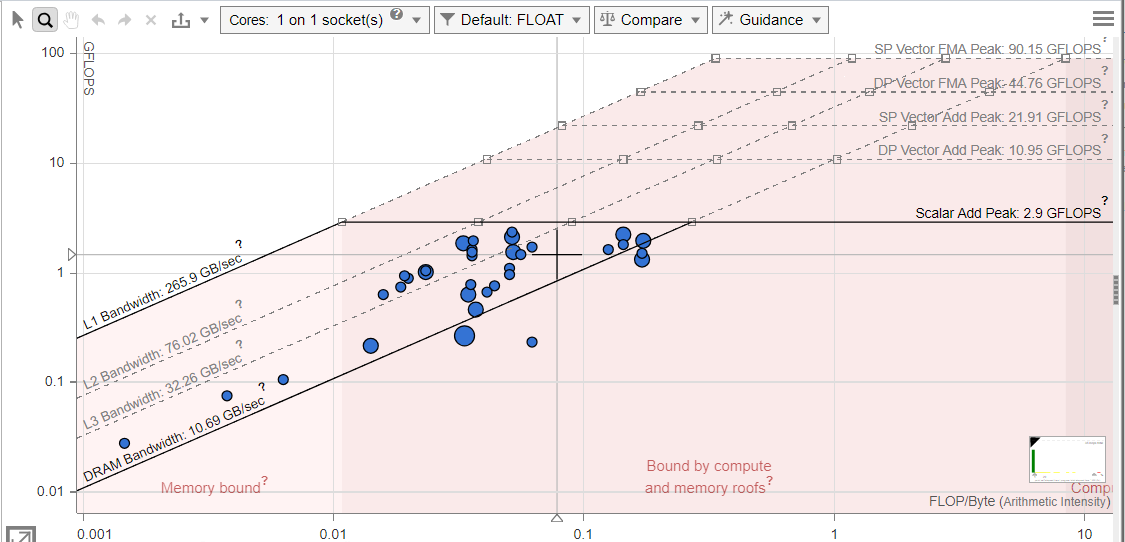
Intel Advisor Roofline Analysis helped understand the actual performance of loops against underlying hardware compute and memory limitations. As the baseline Roofline chart shows (Figure 1), the performance is not optimal, most of the loops are scalar (all the dots are below “Scalar Add Peak” far below from maximum compute capability of hardware) and memory bound (most of the dots are towards left side of the chart). Vectorizing the scalar loops and improving the memory footprint of the CompScope will have a significant impact on improving performance.
By running several analyses supported by Intel Advisor, the team found and resolved data dependencies for loops to enable SIMD architecture. Instead of using class objects to modify, they used arrays to store and manipulate data to enable vectorization. This helps load data in vector registers to undergo SIMD operations.
The team introduced a new algorithm. The algorithm under discussion is a matrix creation process for Computational Electromagnetic Integral Equation-based solver. Creating and filling the matrix go over sources (columns of matrix) and observers (rows of matrix) and perform a series of mathematical operations. Old algorithm follows a simple process of looping over rows and columns and performing these operations for every matrix element entry. The new algorithm, which is vector-friendly, clubs many of these observers and sources that follow a similar set of equations together in arrays to perform these operations in a vector format.
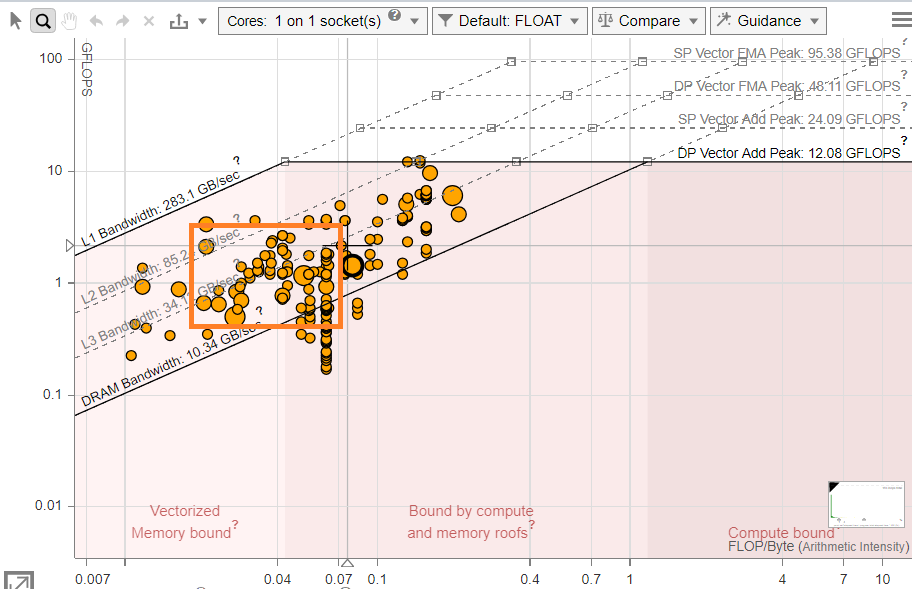
As the Roofline chart shows (Figure 2), with the new algorithm implemented, most loops are vectorized and memory bound (mostly by L3 bandwidth). The Memory Access Patterns (MAP) analysis of the Intel Advisor helped find random memory accesses in the code. As the MAP analysis shows (Figure 3), most of the loops have non-unit stride accesses.
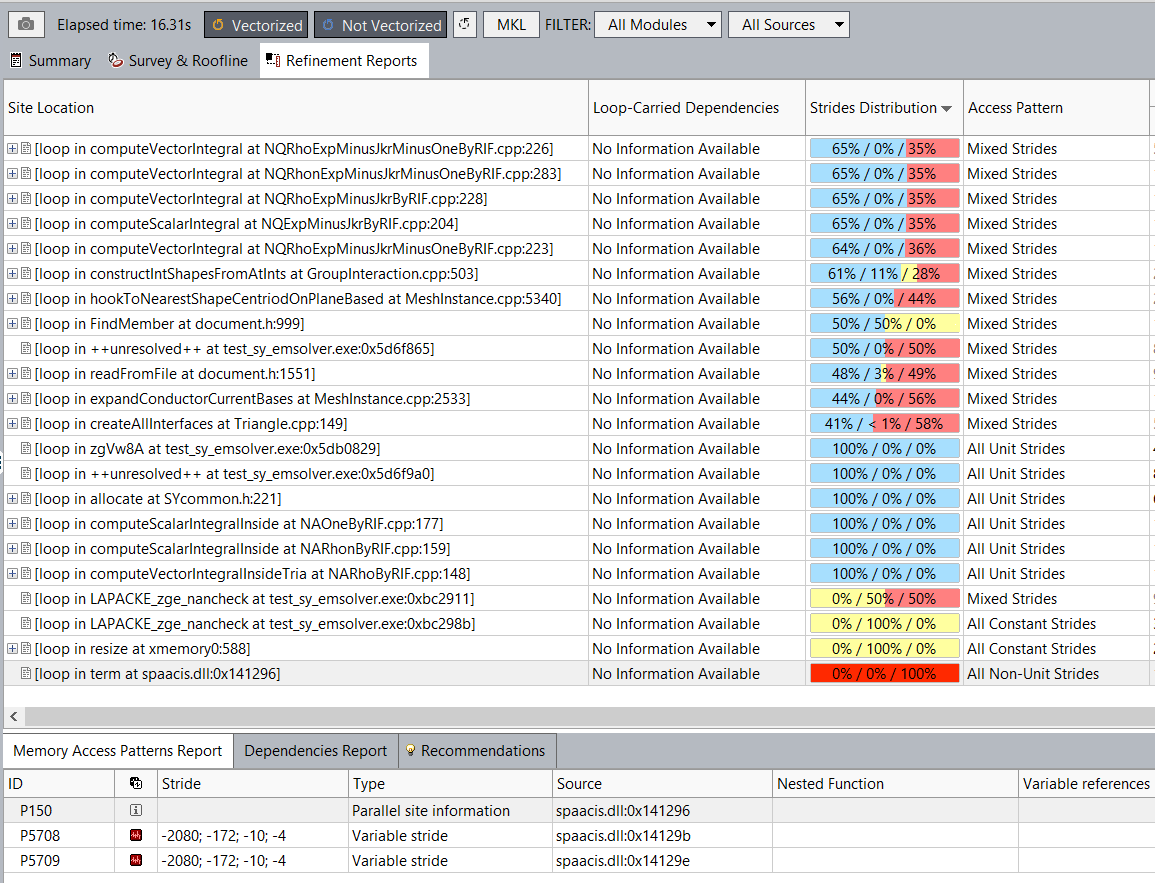
Randomized DRAM access to fetch data is a huge bottleneck in performance. Arrays are contiguous in memory, but they are randomly scattered in the absence of a memory manager. Large arrays fail to fit in caches because their typical size ranges in several MBs. When calculating over large arrays, data goes through the following steps:
- The data is fetched from the DRAM using cache lines.
- It is filled to the cache.
- It is put into vector registers, where it is computed on by the Arithmetic and Logical units.
- It is sent back to the cache.
- It is evicted from the cache and replaced by new data to be computed on.
This process happens for each loop executed in the code. It is extremely time-consuming and affects the performance of the code.
A workaround to this process is to use Bucketing. This means ensuring the length of each array is such that all the input arrays combined fit the L3 cache size. This can speed up execution as transferring data between caches does not take a lot of time. Since all the input arrays at all points are in the cache, there is no need to discard any data and go to the DRAM.
Once all the computations over this data are finished and stored, the next set of data is fetched from the DRAM. Hence, the total pool of data is bucketed over.
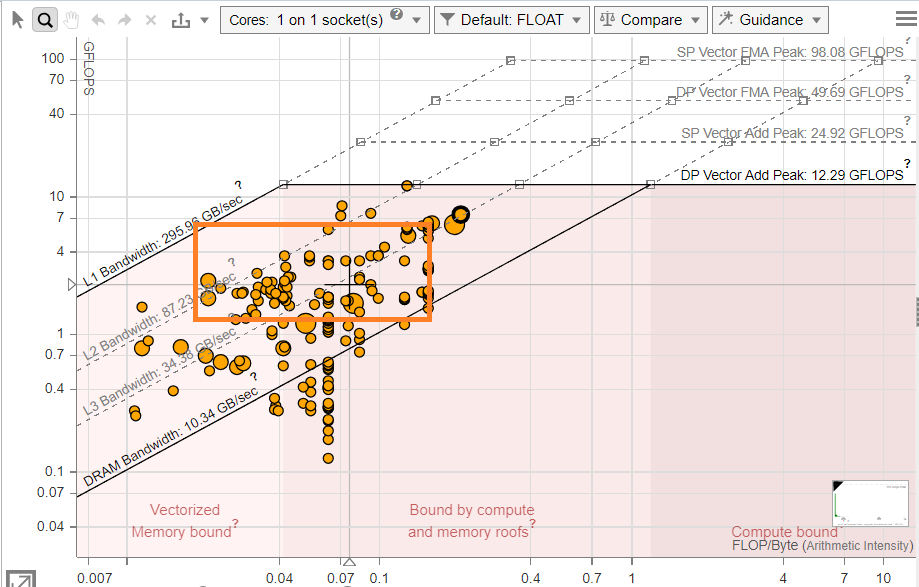
As the Roofline chart shows (Figure 4), with the bucketing, most of the loops have moved up in the graph and are mostly bound by the L2 bandwidth now. The vectorized and cache-optimized loops are both memory and compute bound, which results in a higher arithmetic intensity than for the non-optimized loops. The non-optimized loops are memory bound and depend heavily on memory-based operations. The amount of memory available for them and speed at which they access memory makes them bottlenecks.
Results
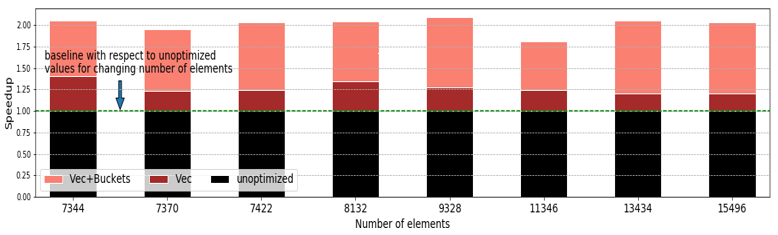
The optimizations described above resulted in 2x performance improvement comparing to the baseline. The chart below shows the timing data (the lower the better) with respect to increasing number of elements in the workload for Baseline (unoptimized), Vectorized (Vec) and Vectorized + Cache optimized (Vec+Buckets) binaries.
The performance runs below were carried out on Intel® Xeon® E5-2678 V3 @ 2.50GHz processor with 128GB of DDR4 memory and internal workload with mesh elements 1689 was used.
Notices and Disclaimers
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.
The products described may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Current characterized errata are available on request.
Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.