Purpose
Floating point operations (FLOP) rate is used widely by the High Performance Computing (HPC) community as a metric for analysis and/or benchmarking purposes. Many HPC nominations (e.g., Gordon Bell) require the FLOP rate be specified for their application submissions.
The methodology described here DOES NOT rely on the Performance Monitoring Unit (PMU) events/counters. This is an alternative software methodology to evaluate FLOP using the Intel® SDE.
Methodology
- We split the FLOP (Floating point Operations) count into two categories:
- Unmasked FLOP: For Intel® Architectures that do not support masking feature
- Unmasked + Masked FLOP: For Intel® Architectures that do support masking feature
Example of some Intel® Architectures that do not support masking feature Processor Name Code Name 2nd gen Intel® Core™ processor family Sandy Bridge 3rd gen Intel® Core™ processor family Ivy Bridge 4th gen Intel® Core™ processor family Haswell Example of some Intel® Architectures that do support masking feature Processor Name Code Name Intel® Xeon Phi™ coprocessor Knights Landing
- There is some debate on what is considered to be a floating point instruction/operation.
- Provided below is the list of general floating point instructions used in this method: ADD, SUB, MUL, DIV, SQRT, RCP, FMA, FMS, DPP, MAX, MIN (each has many flavors)
- The high level idea is:
- Decode every floating point instruction to identify the following:
- Vector (packed) vs. Scalar
- Data Type (Single Precision vs. Double Precision)
- Register Type Used (xmm – 128 bits, ymm – 256 bits, zmm – 512 bits)
- Masking – masked vs. unmasked instruction
- Use the above information with its “dynamic execution” count to evaluate the FLOP count for that instruction.
Example: vfmadd231pd zmm0, zmm30, zmm1 executed 500 times- p – packed instruction (vector), without any mask
- d – double precision data type (64 bit)
- zmm – operating on 512 bit registers
- fma – fused multiply and add (2 floating point operations)
- The FLOP count for the above instruction = 8 * 2 (fma) * 500 (execution count) = 8000 FLOP.
- Decode every floating point instruction to identify the following:
- You do not need to parse/decode all of the above for every floating point instruction to evaluate the FLOP count for your application.
- Intel SDE’s instruction mix histogram and dynamic mask profile provide a set of pre-evaluated counters (using the methodology described above + more) that can be used to evaluate the FLOP count on your application.
The next section describes the details on this.
Instructions to Count Unmasked FLOP
- This is applicable for all Intel architectures (Sandy Bridge, Ivy Bridge, Haswell, Knights Landing, etc.)
- Obtain the latest version of Intel SDE here.
- Generate the instruction mix histogram for your application using Intel SDE as follows:
- sde -<arch> -iform 1 -omix myapp_mix.out -top_blocks 5000 -- ./myapp.exe
- <arch> is the architecture that you want to run on(e.g ivb,hsw,knl)
- Compile the binary correctly for the architecture you are running on.
- Supports multi-threaded runs
Example:
sde -knl -iform 1 -omix myapp_knl_mix.out -top_blocks 5000 -- ./myapp.knl.exe
- sde -<arch> -iform 1 -omix myapp_mix.out -top_blocks 5000 -- ./myapp.exe
- In the instruction mix output (e.g., myapp_mix.out),under the “EMIT_GLOBAL_DYNAMIC_STATS” section, check for the following pre-evaluated counters:
- *elements_fp_(single/double)_(1/2/4/8/16)
- *elements_fp_(single/double)_(8/16) _masked
- The different counters mean the following:
elements_fp_single_1 – floating point instructions with single precision and one element (probably scalar) and no mask elements_fp_double_4 – floating point instructions with double precision and four elements and no mask (ymm) elements_fp_double_8 – floating point instructions with double precision and eight elements and no mask (zmm) …...... elements_fp_single_16_masked – similar as above but now with masks (Note: you will see the mask counts only on architectures + ISA that support masking) - The above by itself is not sufficient since the Fused Multiply and Add instruction (FMA) is counted as 1 FLOP by the above counters.
- “EMIT_GLOBAL_DYNAMIC_STATS” section also prints dynamic counts of every type/flavor of FMA executed in your application. Look for the following:
VFMADD213SD_XMMdq_XMMdq_XMMdq scalar, double precision, on xmm (128 bit) = 1 element VFMADD231PD_YMMdq_YMMdq_YMMdq packed, double precision, on ymm (256 bit) = 4 elements VFMADD132PS_ZMMdq_ZMMdq_ZMMdq packed, single precision, on zmm (512 bit) = 16 elements
......
Other flavors of FMA like VFNMSUB132PD_YMMqq_YMMqq_MEMqq, VFNMADD231SD_XMMdq_XMMq_XMM, etc. may also be present. - Counting FLOPs
Step 1- For each data type (single/double); use the “dynamic” instruction count corresponding to each of the above counters and multiply by the “elements (1/2/4/8/16)” to get the FLOP count.
Example:
Intel SDE (Haswell) Instruction Mix output (snapshot) of a Molecular Dynamics code from Sandia Mantevo Suite (look for the below section under EMIT_GLOBAL_DYNAMIC_STATS).

Unmasked FLOP (Double Precision) =
(23513724690 * 1 + 274320019 * 2 + 37317021308 * 4) = ~173.3304 GFLOP - Note/Caveats:
- The above by itself is not sufficient since the Fused Multiply and Add instruction (FMA) is counted as 1 FLOP (see “Step 2” on how to take that into account).
- For Intel® AVX-512 (KNL) instruction mix output you may see “*elements_fp*_masked” counters as well. Counting masked FLOP is covered in the next section.
- Also the “masked” counters above do not specify the actual mask values, so can’t take them into account anyways.
- For each data type (single/double); use the “dynamic” instruction count corresponding to each of the above counters and multiply by the “elements (1/2/4/8/16)” to get the FLOP count.
- Step 2
- Taking into account FMA and its flavors
- For each FMA flavor, based on data type (single vs. double), packed vs. scalar, and register type as described above + the “dynamic” instruction count corresponding to each FMA, compute and add the corresponding FLOP “just one more time” to the above FLOP count computed in Step 1.
Example:
Intel SDE (Haswell) Instruction Mix output (snapshot) of a Molecular Dynamics code from Sandia Mantevo Suite (look for the VFM* section under EMIT_GLOBAL_DYNAMIC_STATS).
VFMADD213PD_XMMdq_XMMdq_XMMdq 1728000 VFMADD213PD_YMMqq_YMMqq_YMMqq 47496488 VFMADD213SD_XMMdq_XMMq_MEMq 825422220 VFMADD213SD_XMMdq_XMMq_XMMq 5733116808 VFMADD231PD_XMMdq_XMMdq_XMMdq 432000 VFMADD231PD_YMMqq_YMMqq_YMMqq 3189961568 VFMADD231SD_XMMdq_XMMq_MEMq 4 VFMADD231SD_XMMdq_XMMq_XMMq 475482133 VFMSUB213PD_YMMqq_YMMqq_YMMqq 1594141168 VFMSUB231PD_YMMqq_YMMqq_YMMqq 47064488 VFMSUB231SD_XMMdq_XMMq_XMMq 1656723Unmasked FMA FLOP (Double Precision) =
(1728000 * 2 + 47496488 * 4 + 825422220 * 1 + 5733116808 * 1 + 432000 * 2 + 3189961568 * 4 + 4 * 1 + 475482133 * 1 + 1594141168 * 4 + 47064488 * 4 + 1656723 * 1) = ~26.5546 GFLOP
Note/Caveats:- The multiplier used above (1,2,4..) is based on the type of FMA instructions (PD - packed double on XMM/YMM ; SD – scalar double on XMM …)
- For Intel AVX-512 (KNL/SKL) instruction mix output all FMA (and its flavors) instructions (masked or full vectors) will be marked as masked (e.g., VFMADD132PD_ZMMf64_MASKmskw_ZMMf64_MEMf64_AVX512).
- The next section “Instructions to Count Masked FLOP” will cover that.
- Add the FLOP counted in step 1 and step 2.
Example (for the Advection routine):
Total Unmasked FLOP (Double Precision) = 173.3304 + 26.5546 = 199.885 GFLOP - If running on an architecture that does not support masking, then you have your total FLOP count (can skip the next section).
- For floating point operation per second (FLOPS), divide the FLOP count computed using the above method by the application run time measured on appropriate hardware.
- On another note, the FLOP count of an application will most likely be the same irrespective of the architecture it is run on (unless the compiler generates completely different code impacting FLOP count for the two different binaries–which is very rare). Thus, to find the FLOP count for an application, compute as described above on Ivy Bridge (or Haswell) with no hardware masking feature and use the same count for other architectures (like Knights Landing, etc.). Thus you do not have to deal with masking at all while evaluating FLOP count.
- But if you still need to evaluate the FLOP count on architecture with masking support, refer to the next section, which describes how to count masked FLOP using the dynamic mask profile feature from Intel SDE.
Instructions to Count Masked FLOP
- Intel SDE has a dynamic mask profile feature that evaluates and prints the number of operations for each executed instruction with a mask.
- Generate the dynamic mask profile for your application using Intel SDE as follows:
- sde -<arch> -iform 1 -odyn_mask_profile myapp_msk.out -top_blocks 5000 -- ./myapp.exe
- <arch> is the architecture that you want to run on (e.g. ivb,hsw,knl).
- Compile the binary correctly for the architecture you are running on.
- Supports multi-threaded runs.
Example:
sde -knl -iform 1 -odyn_mask_profile myapp_knl_msk.out -top_blocks 5000 -- ./myapp.knl.exe
- sde -<arch> -iform 1 -odyn_mask_profile myapp_msk.out -top_blocks 5000 -- ./myapp.exe
-
The dynamic mask profile is an XML output, with a summary table per thread of the different categories of instructions with and without masking and their total instruction and operation count.
-
In addition, the mask profile also prints the dynamic instruction count and operation count per instruction.
-
Summary Table (Dynamic Mask Profile)
Example: Intel® SDE (Knights Landing) dynamic mask profile output (snapshot below):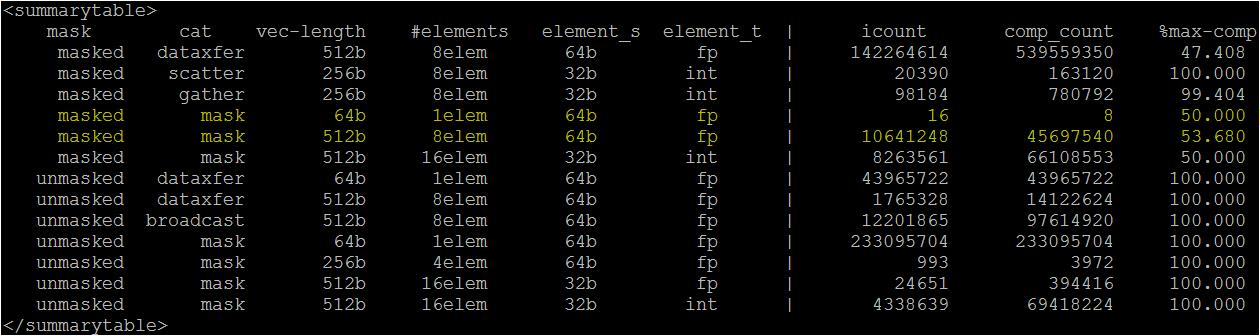
Column Header Description First mask Classifies the masked instructions vs. unmasked instructions Second cat Classifies categories of the instruction (e.g. memory instructions (data transfer), sparse (gather/scatter) and computational (mask) Third vec-length Specifies the vector register width Fourth #elements Specifies maximum number of elements possible in the vector register (with vec-length in third column) and with element size (specified in fifth column) Fifth element_s Specifies size of element (or data type) in bits (e.g. 64b = 64 bits = 8 byte) Sixth element_t Classifies based on element type (e.g. fp - floating point vs. int – integer) Seventh icount Total Instruction count of each category/type Eighth comp_count Corresponding computation count for the executed instructions of each category/type Ninth %max-comp Shows % vector lane utilization for each category/type - For example in the above snapshot only the rows highlighted have to be used for “masked” FLOP count
- Please note (in your run) you need to mainly look for “masked” instructions with “mask” category and “element_t = fp” for masked FLOP count.
- The “comp_count” number is basically the masked FLOP count.
- But again FMA is counted as only one FLOP in the comp_count counter.
- See the next section on how to take into account masked FMA (to count them as 2 FLOP).
- For example in the above snapshot only the rows highlighted have to be used for “masked” FLOP count
- Per Instruction Details (Dynamic Mask Profile)
- In addition to the “summary table” per thread, the dynamic mask profile also prints the computational count on a per instruction basis.
- Below is a snapshot of it.
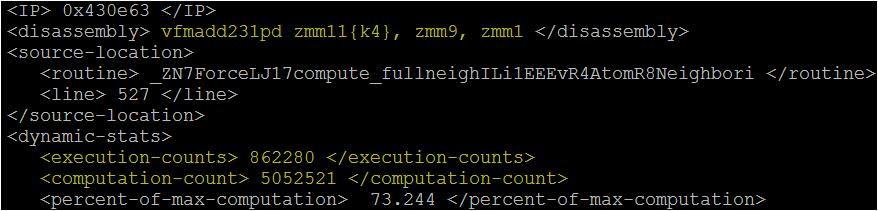
- In this case, the masked “vfmadd213pd” instruction has an execution count = 862280 and the computation count = 5052521. Thus all the executions of this instruction are NOT using all the vector lanes in this case.
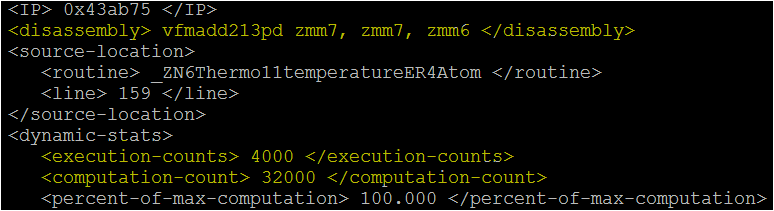
- In the snapshot above, the “vfmadd213pd” instruction has an execution count = 4000 and the computation count = 32000 (4000 * 8). Thus all the executions of this instruction are using all the vector lanes in this case (no mask).
- Since the summary table accounts for the FMA instructions (and its flavors) as only 1 FLOP, you have to add the computation count for all the masked FMA instructions from the instruction-details (as above) “one more time” to account for 2 FLOP per FMA.
- Counting Masked FLOP
Step1
- From the summary table add the “comp_count” value from all “masked” instructions with “mask” category and “element_t = fp”.
- Step2
- Parse all the FMA instructions with mask, from per instruction-details and add the “computation-counts” to the above sum evaluated in Step 1 one more time.
- Thus you have the total Masked FLOP count.
Note/Caveats:- As mentioned in the previous section, in Intel AVX-512 (KNL/SKL) instruction mix output all FMA (and its flavors) instructions (masked or full vectors) are marked as masked (e.g. VFMADD132PD_ZMMf64_MASKmskw_ZMMf64_MEMf64_AVX512).
- Thus you can use the dynamic mask profile “instruction-details” to evaluate the “computation-count” for all FMA instructions (masked or unmasked – full vectors).
Validation
The above methodology may look a bit overwhelming at first, but the reason for such detailed instructions is so that you can write your own simple scripts to parse the above information. We hope to provide the scripts (currently used internally) to evaluate FLOP count as part of the Intel SDE releases in the future.
Below is a summary of the FLOP count validation on some applications.
- The error margin is basically the difference in count between the Reference count and the FLOP count evaluated using Intel SDE.
- The reason for the difference can be due to reasons like theoretical evaluation vs. actual code generation, instructions counted as FLOP, etc. We have not looked into the details for this difference.
- But you can see the error margin is very minimal.
| Workloads | Reference FLOP (from NERSC) |
MPI ranks | FLOP Count (using Intel® SDE) |
Error Margin |
|---|---|---|---|---|
| MiniFE | 5.05435E+12 | 144 | 5.18039E+12 | 1.03 |
| miniGhost | 6.55500E+12 | 96 | 6.85624E+12 | 1.05 |
| AMG | 1.30418E+12 | 96 | 1.43311E+12 | 1.10 |
| UMT | 1.30211E+13 | 96 | 1.38806E+13 | 1.07 |
Footnotes:
Masking: Even on Intel® AVX/AVX2 (IvyBridge/Haswell) the compiler supports "masking" internally with blends and so forth. Thus in vectorized loops with conditionals there will be unused computations (e.g., compiler computes both the true and false branches and then blends them, throwing away the unused parts). This means that FLOP will be an overestimate of useful computation. Arguably the masked version (KNL/SKL) will be more accurate since the pop count of the mask is exact (assuming the compiler uses masks everywhere).