Introduction
There are several RAS (Reliability Availability and Serviceability) features for volatile memory that can be extended to persistent memory. Still, there are RAS features that require special handling by the application designed for persistent memory. In this article, we introduce the concepts of RAS for persistent memory and the recommendations to include in the error strategy of persistent memory (PMEM) aware application.
RAS Concepts and Recommendations for Application’s Error Strategy
Concept: Power-fail Protected Domain
Systems with persistent memory support a concept of a persistence domain or power-fail protected domain. As shown in figure 1.1, a persistence domain may include the persistent memory controller, Write Pending Queues, and the CPU caches.

Once data has reached the power-fail protected domain, it may be recoverable during a process that results from a system restart. That is, once the data reaches the DIMM’s write pending queues (WPQ) or buffers protected by the power failure domain, applications should assume it is durable. For example, if a power failure occurs, the data will be flushed from the power-fail protected domain using stored energy guaranteed by the platform for this purpose. Data that has not yet made it into the protected domain will be lost. It is the responsibility of the application to ensure data integrity.
Power fail protected domain is the responsibility of a platform and not of the software.
Asynchronous DRAM Refresh (ADR)
ADR is a feature supported on all Intel platforms, which flushes the write-protected data buffers and places the DRAM in self-refresh. This process is critical during a power loss event or system crash to ensure the data is in a safe and consistent state on persistent memory. By default, ADR does not flush the processor caches. A platform that supports ADR includes persistent memory and the memory controller’s write pending queues within the persistence domain.
Enhanced Asynchronous DRAM Refresh (eADR), as shown in Figure 1.1, extends the power of a platform fail-protected domain to include CPU caches.
Application’s Responsibility: Ensuring Data Persistence
Applications must flush the data in the CPU caches to ensure that the data reaches the power-fail protected domain on ADR supported platforms, using the Flush instructions: CLWB, CLFLUSHOPT, CLFLUSH, non-temporal stores, or WBINVD machine instructions.
Applications running on an eADR platform do not need to perform flush operations because the hardware should flush the data automatically. However, they are still required to perform an SFENCE operation to maintain write order correctness. Stores should be considered persistent only when they are globally visible, which the SFENCE guarantees.
Concept: Dirty Shutdown
As described earlier that if a system loses power, there should be enough stored energy within the power supplies and platform to flush the contents of the power-fail protected domain. Data will be considered consistent upon successful completion. If this process fails, due to exhausting all the stored energy before all the data was successfully flushed, the persistent memory modules will report a dirty shutdown.
Dirty shutdown is
- An indication from the persistent memory device that data loss MAY have occurred
- available to Operating Systems through vendor-agnostic ACPI 6.3 interfaces.
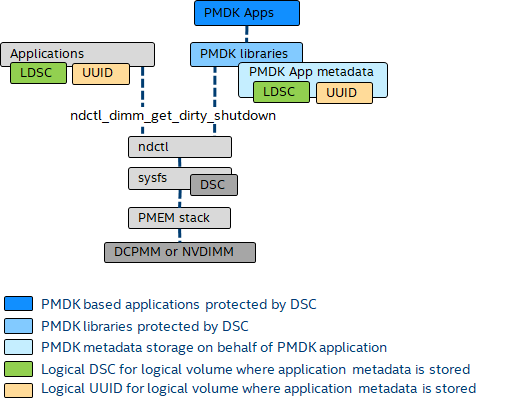
Dirty Shutdown Count (DSC) is a persistent count monotonically incremented whenever a dirty shutdown occurs. ndctl and ipmctl utilities provide a way to retrieve the count (docs.pmem.io)
- ndctl – shutdown_count
- ipmctl latcheddirtyshutdowncount
A Dirty Shutdown is a very rarely occurring event and may or may not result in needing to restore the data from backups. You can find more information on this process – and what errors and signals are sent – in the RAS (reliability, availability, serviceability) documentation for your platform and the persistent memory device. Chapter 17 and the webinar also discusses RAS features further.
Application’s Responsibility: Ensure Data Integrity
Detecting a Dirty Shutdown

Handling Dirty Shutdown
Making use of the Dirty Shutdown Count (DSC) in a persistent memory aware application requires some additional startup logic in the application or libraries like those provided by PMDK. The operating systems provide the essential infrastructure for finding the DSC for the physical persistent memory devices. When multiple persistent memory devices are interleaved together by the memory controller, a logical DSC is created by adding the physical DSCs together. The DSC for the entire interleave set will increment when any persistent memory device in the interleaved set experiences a dirty shutdown. The calculation of the logical DSC happens at the application or library level, not at the OS level.
PMEM applications use of the DSC can be summarized at a high-level as:
- Track the last known logical DSC in application metadata to detect when increment has occurred
- Avoid false positives by tracking clean/dirty information in persistent memory data files
- Force service action when affected by the dirty shutdown
- PMDK Libraries Protected by DSC
Concept: Uncorrectable Errors
An uncorrectable error could occur in the hardware, but the application may or may not have consumed it. The following sections describe the RAS features supported when an
• An undetected uncorrectable error occurred that is already consumed
• An uncorrectable error was detected but not consumed by the application.
What is an Uncorrectable Error?
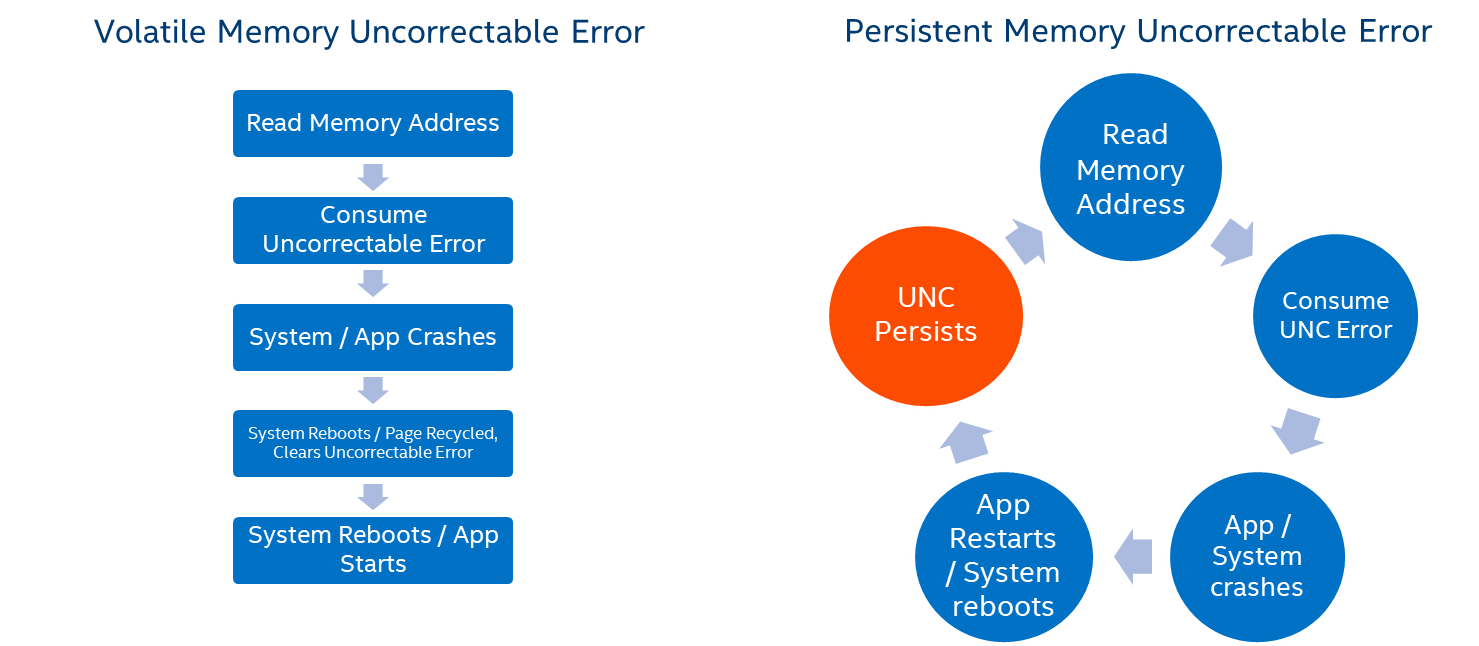
Traditionally, the main memory of a server is protected using error-correcting codes (ECC), where the hardware can automatically correct memory errors that happen due to transient hardware issues, such as power spikes, soft media errors, and so on. If an error is severe enough, it will corrupt enough bits that ECC cannot correct; the result is called an uncorrectable error (UNC).
Typically, uncorrectable errors fall into three categories:
• UNC errors that may have corrupted the state of the CPU and require a system reset.
• UNC errors are recoverable and handled by the application during runtime.
• UNC errors that require no action.
Why do we care
As the name suggests, persistent memory uncorrectable errors are persistent. Unlike volatile memory, if power is lost or an application decides to restart itself, the uncorrectable error will still be on the hardware leading to an application getting stuck in an infinite loop.
Machine Check Exception (MCE)
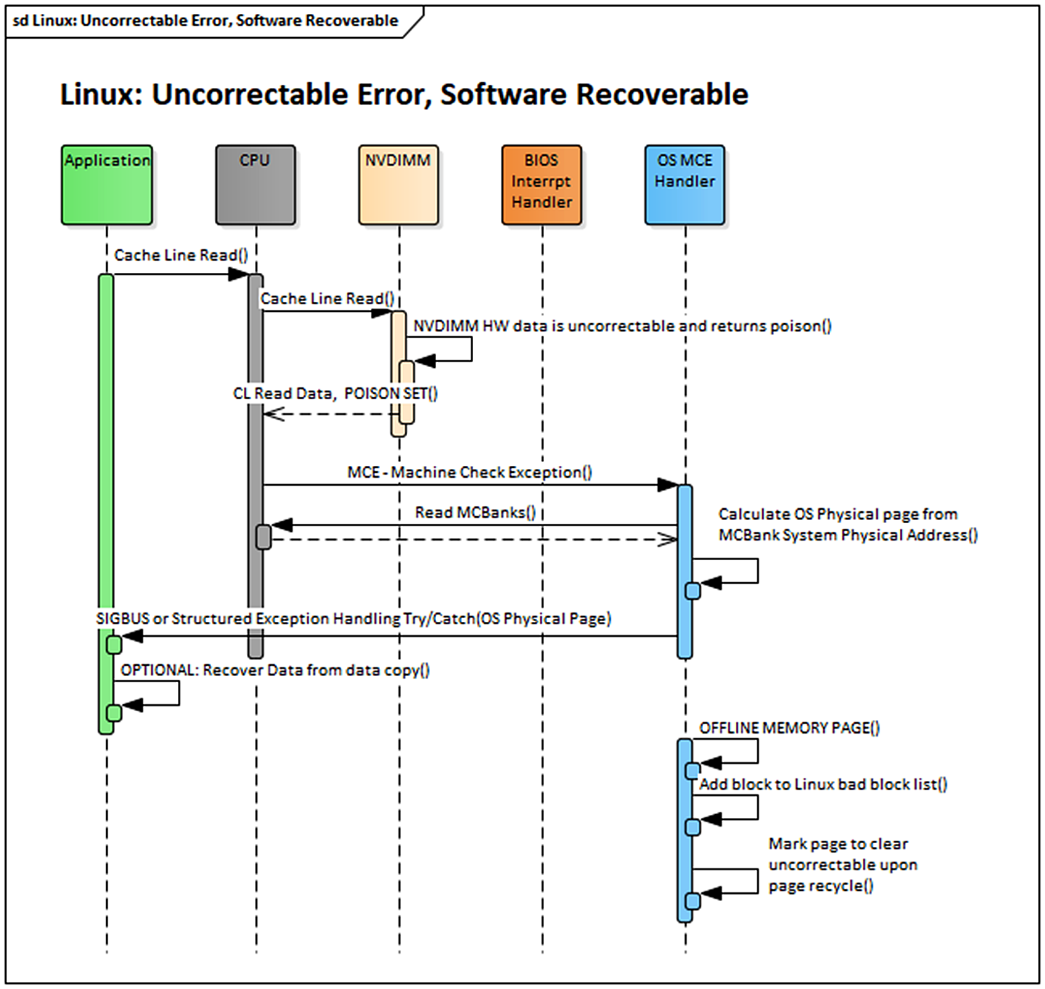
When the hardware detects an uncorrectable memory error, it routes a poison bit along with the data to the CPU. For the Intel architecture, when the CPU detects this poison bit, it sends a processor interrupt signal to the operating system to notify it of this error. This signal is called a machine check exception (MCE). The operating system can then examine the uncorrectable memory error, determine if the software can recover, and perform recovery actions via an MCE handler.
MCE Handling in Operating Systems
Operating system vendors handle MCE in different ways, but some common elements exist for all of them. The following actions take place in the Linux operating system.

RAS Support in PMDK to Handle Consumed Uncorrectable Errors
The Persistent Memory Development Kit (PMDK) libraries automatically check the list of pages with uncorrectable errors in the operating system and prevent an application from opening a persistent memory pool if it contains errors. If a page of memory is in use by an application, Linux attempts to kill it using the SIGBUS mechanism.
Application’s Role: Ensure Data Integrity
At this point, the application developer can decide what to do with this error notification. The simplest way to handle uncorrectable errors is to let the application die when it gets a SIGBUS, so you do not need to write the complicated logic of handling a SIGBUS at runtime. Instead, on the restart, the application can use PMDK to detect that the persistent memory pool contains errors and repair the data during application initialization. For many applications, this repair can be as simple as reverting to a backup error-free copy of the data.
Figure 1-4 shows a simplified sequence of how Linux can handle an uncorrectable (but not fatal) error that was consumed by an application.
Concept: Unconsumed Uncorrectable Errors at Runtime
What is an Unconsumed, Uncorrectable error?
Uncorrectable errors that have been discovered on the persistent memory media before consumed by any application.
Unconsumed, uncorrectable error handling may be implemented differently on different vendor platforms, but at the core, there will be a
- a mechanism to discover the unconsumed uncorrectable error
- Patrol Scrub
- a mechanism to signal the operating system of an unconsumed uncorrectable error
- ACPI Notification - NVDIMM Root Device Notification 0x81
- a mechanism for the operating system to query information about the unconsumed uncorrectable error
- Address Range Scrub
As shown in Figure 1-5, these three mechanisms work together to proactively keep the operating system informed of all discovered uncorrectable errors during runtime.

Patrol scrub
Patrol Scrub is a longstanding RAS feature for volatile memory that can also be extended to persistent memory. It is an example of how a platform can discover uncorrectable errors in the background during regular operation.
A hardware engine on either the platform or on the memory device generates requests to memory addresses on the persistent memory device at a predefined frequency. Given enough time, it will eventually access every memory address. The frequency in which patrol scrub generates requests produces no noticeable impact on the memory device’s quality of service. During the Patrol Scrub, the read requests to memory address provide an opportunity to run ECC at that address and correct any correctable errors before they become UNC. Optionally, upon discovering a UNC, the patrol scrubber can trigger a hardware interrupt and notify the software layer of its memory address.
The ACPI specification describes a method for hardware to notify software asynchronously of unconsumed uncorrectable errors called the Unconsumed Uncorrectable Memory-Error Persistent Memory Root-Device Notification.
Address Range Scrub
Upon receipt of the Root-Device Notification, the operating system can use existing ACPI methods, such as Address Range Scrub (ARS), to
- discover the address of the newly created uncorrectable memory error
- add it to the OS list of uncorrectable errors
- ake appropriate actions.
Summary
This article described some of the RAS features defined for persistent memory devices and that apply to persistent memory aware applications. For a deeper understanding of these concepts, refer to Chapter 17 of the book “Programming Persistent Memory” and the webinar.