Ahmed Ayyad, Amr Nasr, Ehab Nasr, Ingy Mounir and Mennatallah Samier, Brightskies Inc.
Philippe Thierry, Sunny Gogar, and Belinda Liviero, Intel Corporation

The Advantages of oneAPI
The choice of programming model is a critical decision when embarking on a new development project. This decision has only gotten more difficult with the proliferation of parallel programming approaches and hardware accelerators, from vector CPUs to GPUs, FPGAs, DSPs, ASICs, and even dedicated AI chips. These accelerators often require proprietary programming approaches that lock the software to a particular vendor's architecture. The new oneAPI industry initiative aims to reduce the complexity of software development on heterogeneous hardware while eliminating vendor lock-in1.
Data Parallel C++ (DPC++), a key component of oneAPI, is an attractive programming language because it builds on standard C++11 by adding new constructs to offload data parallel computations to hardware accelerators. DPC++ borrows heavily from SYCL, a standard, cross-platform abstraction from the Khronos Group, but it adds new features like Unified Shared Memory (USM) and subgroups2. Like SYCL, it also allows a "single source" development style where host and kernel code can exist in the same source file. An open-source DPC++ compiler, initially created by Intel, is available on GitHub*.
Migrating to DPC++ From Other Parallel Programming Approaches
DPC++ is designed to run the same codebase efficiently across different processor architectures (e.g., CPU or GPU). Maintaining separate codebases for each architecture is no longer necessary, though some tweaking may still be required to get the best performance. DPC++ workgroup size is the main tuning parameter because different devices have different hardware limits. For example, some devices are aligned in such a way that powers-of-two are the preferred group size. However, the program flow remains the same.
Migrating from other parallel programming approaches like OpenMP* or OpenACC is straightforward; once you shift your thinking to the kernel-based abstraction of DPC++. This abstraction, mainly C++ lambda expressions, is intuitive to C++11 programmers. Lambdas are used in the submission of kernel calls and are, therefore, an essential part of DPC++.
In addition to parallel constructs, memory management (allocation and data movement) in a heterogeneous hardware environment is also an important consideration. Memory allocation has a similar syntax to C++, so allocating memory is done almost the same way. Memory management functions such as malloc, memset are all supported by DPC++. The difference is that they are submitted within a kernel call with all the parameters necessary to specify where exactly allocations are to be made. Specifically, in a heterogeneous environment, programmers must decide whether data should reside on the host, devices, or both. DPC++ memory management is like other heterogeneous parallel programming approaches. Both implicit and explicit memory allocation on hosts and devices are supported. Implicit memory management lets the DPC++ runtime library handle data allocation and migration between the host and devices. Explicit memory management gives the programmer finer control over data allocation and movement when it is advantageous. Programmers who are already using other heterogeneous parallel programming approaches will find DPC++ memory management familiar4.
Choosing a Suitable Test Application
Brightskies' goal was to implement a full Reverse Time Migration (RTM) application using DPC++, and compare it to their existing OpenMP implementation on the CPU. This work was done both to provide a variety of implementation options, but also to evaluate developer productivity, code portability, and performance. RTM is an important computational technique in seismic imaging. Wave equation-based seismic depth migration techniques such as RTM are considered optimal for today's imaging objectives, particularly in complex environments such as subsalt exploration. RTM provides high-resolution depth images of the subsurface that are critical for oil and gas exploration. In terms of computation, RTM contains several parallel patterns that stress all hardware components8 (i.e., compute, memory and I/O subsystems, and network interconnect), making it a good candidate for oneAPI evaluation.
RTM is implemented as a 2D isotropic acoustic time domain. The time-domain finite-difference (TDFD) approach is based on explicit finite difference schemes in time and space. It's quite popular due to its simple stencil-based implementation on a Cartesian grid and its natural parallelism. This RTM 2D application serves as a good test of DPC++ programmability because a mix of implementations is possible: geophysical boundary conditions, numerical approaches (stencil length, wave equation order), and I/O management with or without compression. In this case study, the memory-bound propagation, random velocity boundary, and second-order wave equation kernels were implemented using DPC++.
Evaluating DPC++ in Application Development
Wave propagation in the 2D model using TDFD equation solvers is compute-intensive because a forward-propagated source wavefield is combined at regular time steps with a back-propagated receiver wavefield. Synchronization of both wavefields results in significant I/O, which disrupts the computational flow. Fast compression/decompression using Intel® Integrated Performance Primitives helps to reduce I/O. Still, the solvers are also memory bandwidth-limited due to low flop-per-byte ratio and non-contiguous memory access, resulting in low resource utilization.
Brightskies embarked on a journey to develop a functionally correct DPC++ implementation of RTM capable of achieving high bandwidth and does so considering the diverse computational power, memory, and bandwidth requirements of potential targets (CPUs and accelerators).
Starting from a working OpenMP version of RTM that was tuned for Intel® CPUs, Brightskies created a DPC++ version that offloads only the critical hotspots to accelerators and leaves the rest of the codebase (up to 70% in this case) unchanged. The amount of code change was ascertained by counting the lines of code in the original open-source release from Brightskies12, and comparing it to the total lines of code in the programs under the DPC++ (dpcpp) specific folder.
They intended to write performant code with minimal hand-tuning. DPC++ is based on modern C++ and is LLVM-compliant, so the additional overhead to develop and maintain the code changes is minimal (resulting in a shallow learning curve).
The most compute-intensive parts of RTM are the imaging condition kernel and the finite difference scheme used to solve the wave equation, as they run per timestep for each seismic shot. This roughly corresponds to the standalone iso3dfd benchmark5.
Starting from the 2D constant velocity isotropic acoustic wave equation that describes a wave propagating through time and space
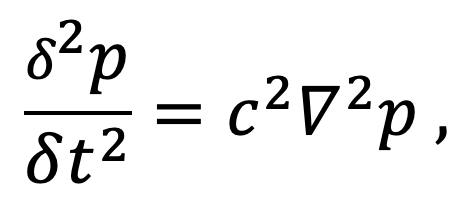
where ∇ is the Laplacian operator, p denotes the pressure fields and c the p-wave velocity field and using a central finite difference scheme (second order in time and various order in space)
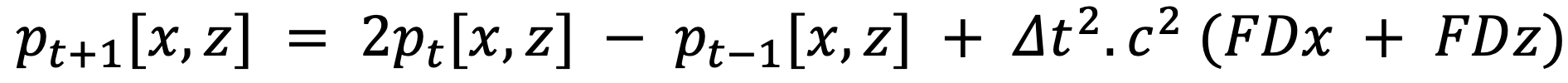
where FDx and FDz denote
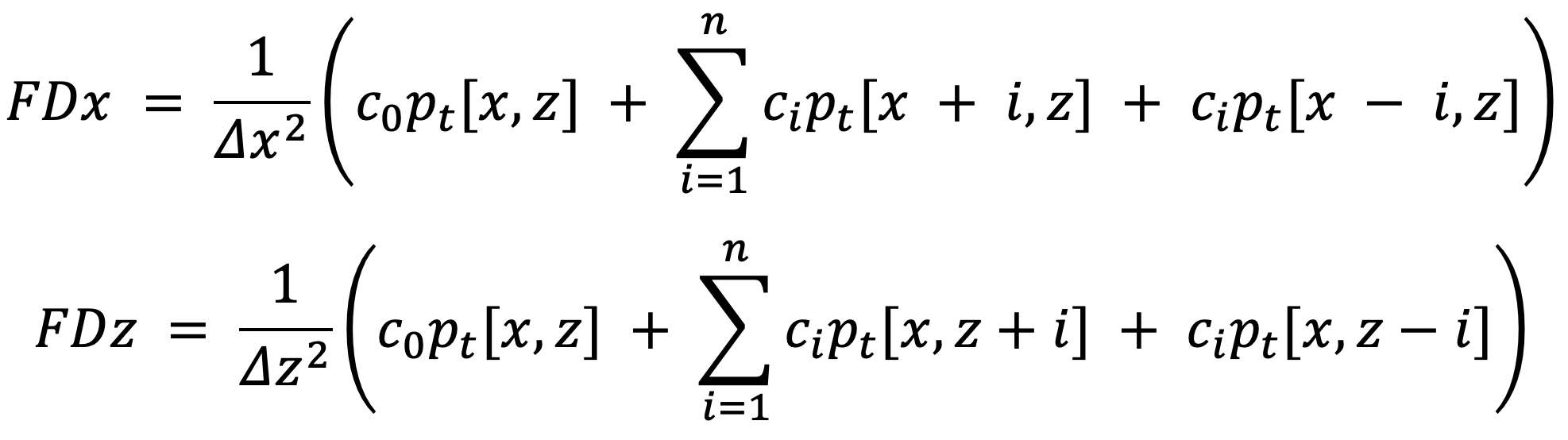
To obtain the final image, we apply a simple imaging condition13 to correlate the two wavefields S and R, forward-propagated from the source and back-propagated from the receivers, respectively
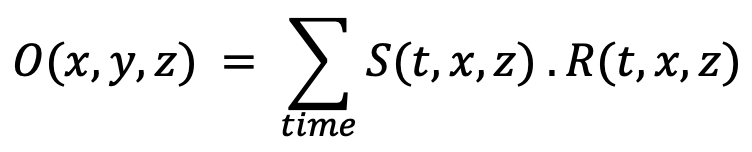
The advantage of this full implementation compared to iso3dfd is that it illustrates the kernels that can be offloaded versus the ones that may stay on the host. This work partitioning is an important consideration, especially when compressing the wavefield and the associated I/O. Being able to handle real data as well as analyzing various boundary conditions is another advantage of having a 2D RTM implemented as a 3D testbed platform.
Moreover, with simple parameterization and low code-divergence, Brightskies' DPC++-enabled RTM codebase is implemented to run on multiple architectures (CPU, GPU) with (typically) just a recompile.
In RTM, there exist custom kernels for the wave equation part for performance tuning, one using shared local memory for GPU and the other for CPU.

Figure 1 shows a snippet from the cross-correlation kernel, showing nx * nz (ny=1, because it is 2D) element-wise multiplication and addition operations, meaning for each point in our wavefield grid, we'd have to perform two floating-point operations.
The global range describes the total image size in nx * nz (ny=1, because it is 2D), the local_range stands for the workgroup size which is recommended to be 256 for most architectures to maintain proper caching, and the global_nd_range is created from both ranges to be passed into the command.
A DPC++ nd_item encapsulates a function object executing on an individual data point in a DPC++ nd_range. When a kernel is executed, it is associated with an individual item in a range and acts upon it. Think of it as an iterator that points to the current element in the range at any given thread.
For each nd_item, we get the item's index and calculate the product of the 1st pressure, which represents the source pressure, and the 2nd pressure, which represents the receiver pressure, and we accumulate them in the output of the correlation kernel.
Along with productivity, evaluating performance is extremely important. In the following analysis, the idea is to quickly evaluate the performance of the different kernels of the application with respect to the maximum achievable performance, as well as looking at possible vectorization or threading issues and any other bottlenecks.
For this purpose, we use the Intel® Advisor, which now features new views of the data movement with respect to the achievable total performance for each of the functions in the application.
Starting with Intel® Parallel Studio 2020 Update 2, Intel® Advisor implements a new powerful feature called multi-level roofline model. Based on cache simulation, Intel® Advisor evaluates the data transactions between the different memory layers available on the system and provides automatic guidance to improve performance.
A nice feature of the multi-level roofline is that it provides an implementation of the roofline close to the classic roofline model by only looking at DRAM data transfers.
All the tests with the OpenMP and DPC++ versions of RTM presented here were collected by Brightskies in June and July 2020 on a 2-socket Intel® Xeon® Gold 6252N system with 24 cores, 192GB of DDR4 memory and over six memory channels per socket, providing a theoretical bandwidth of 281.568 GB/s. Hyperthreading and turbo BIOS settings were disabled.
The application was built with Intel® oneAPI DPC++ Compiler revision Beta07, and as an early evaluation, we observed bandwidth and cache occupancy on a single UMA node (1 socket) with OpenMP and DPC++ implementations.
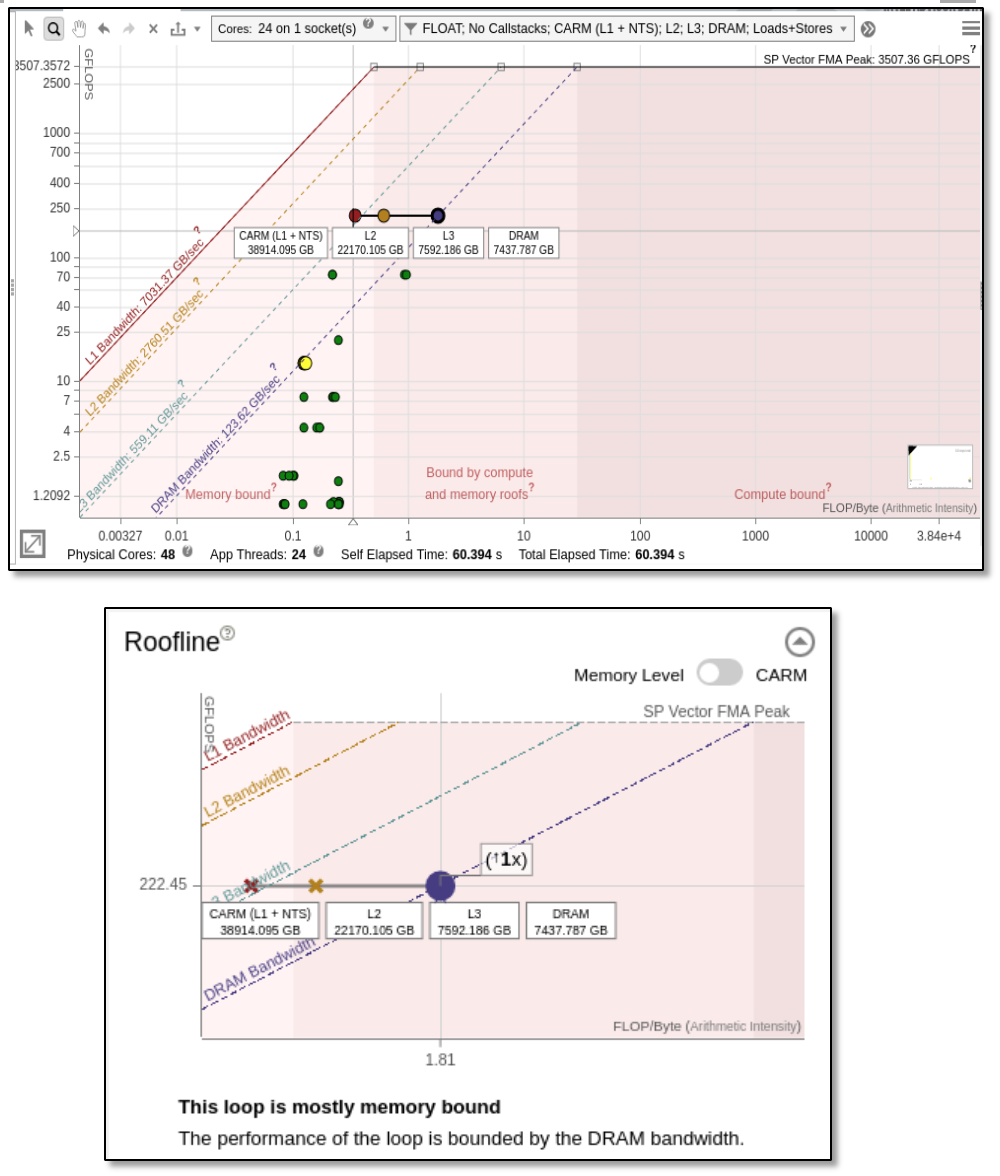
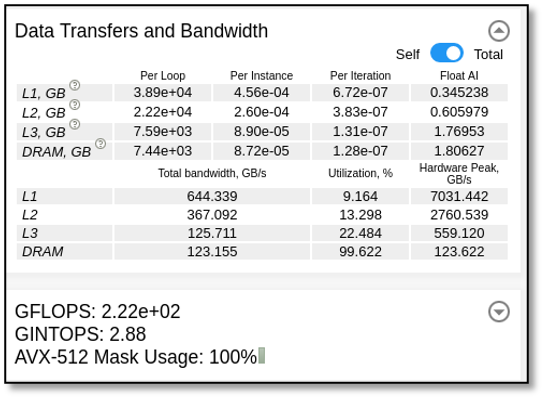
For the OpenMP implementation running on a single socket, we can see in Figure 2 that the implementation is strongly bound by DRAM bandwidth. Intel ® Advisor can detect that there is only "1x speedup" possible with respect to the DRAM, meaning that we are already at the maximum achievable bandwidth (99.622% for all threads).
More advice is provided in the recommendations tab, such as implementing cache blocking or changing the data structure to reduce memory transfers from DRAM.
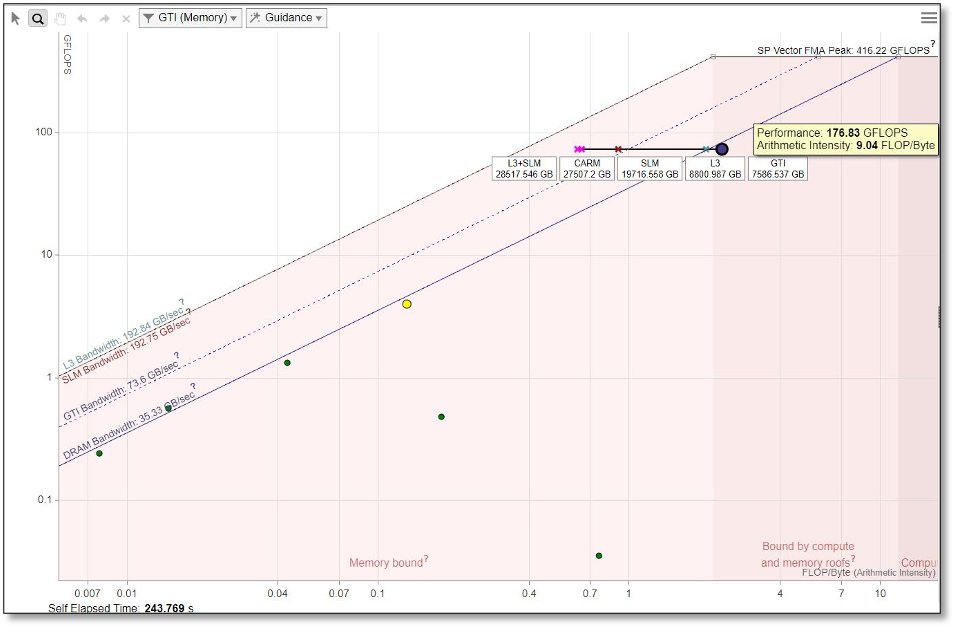
At the bottom of Figure 2, we see a zoom showing four dots for the single loop selected from the top figure. Each dot indicates the same performance (vertical position) and different arithmetic intensities (horizontal position). Arithmetic intensity is the ratio of flops divided by bytes (operations divided by memory movements). To provide these four dots for a single loop, Intel® Advisor computes the arithmetic intensity with data coming from the cache simulation and considers the following:
- memory transfers between registers and L1 (CARM dot)
- memory transfers between L1 and L2 (L2 dot)
- memory transfers between L2 and LLC (L3 dot)
- memory transfers between LLC and DRAM (DRAM dot)
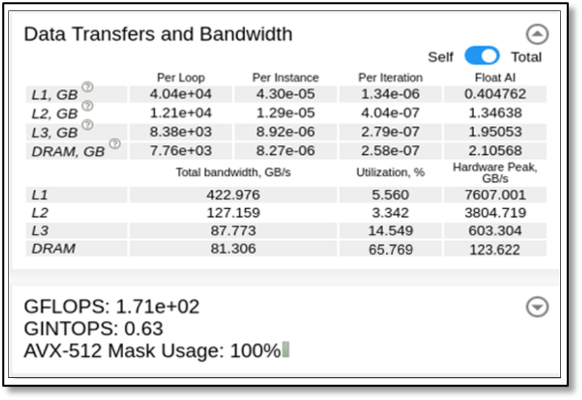
All the data transfers and bandwidth provide memory metrics on the different layers (L1, L2, L3 and DRAM) (see Figure 4 for the OpenMP implementation and Figure 5 for the DPC++ implementation). Included in these captures is the amount of data transferred for a single thread (self) or all threads (total), as well as bandwidth.
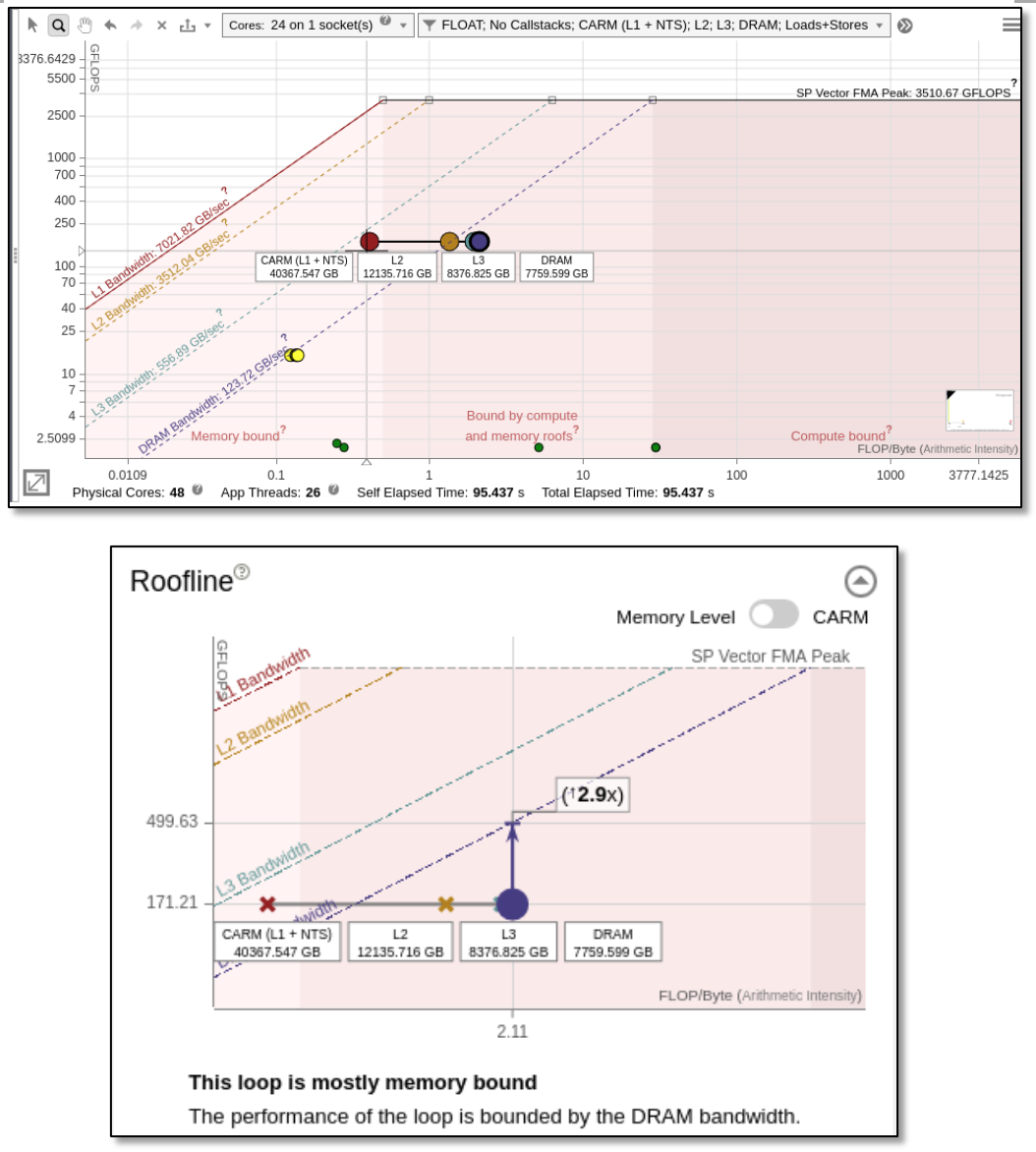
For the DPC++ implementation, we can see in Figure 3 that the DRAM bandwidth again limits the application. Intel® Advisor predicts that there is only a 2.9x speedup possible with respect to the DRAM. The L3 and DRAM dots are very close on the horizontal axis, so L3 and DRAM usage is similar, meaning that L3 and DRAM are not used efficiently.
The goal of this initial paper was to show the comparison between an OpenMP and a DPC++ implementation on CPU and to provide access to the application on GitHub12; we also ran the same DPC++ code on Intel® Processor Graphics, namely an Intel® Xeon® E-2176G with Intel® UHD Graphics P630 (350 – 1200 MHz) freely available on Intel® DevCloud3.
Managing Large Amounts of Data
As mentioned before, during a standard RTM implementation run, many snapshots of the forward-propagated wavefield need to be stored for reuse and cross-correlation during the back-propagation phase. This can quickly go up to 10s of terabytes of data.
Several options are available to limit the amount of snapshot data, such as optimal checkpointing6, or partly saving only the boundaries during the forward propagation. One can also avoid the snapshot by adding a third propagation. In addition to back-propagating the seismic data, it is also possible to back-propagate the source wavefield, making the correlation of source and receiver wavefields straightforward and the RTM IO-less.
The original implementation is still frequently used, especially since high-speed and accurate compression algorithms are available to reduce large files by one or two orders of magnitude; Brightskies adopted the open-source ZFP implementation from LLNL9 in their OpenMP version of RTM.
ZFP is a BSD-licensed open-source library for compressed floating-point arrays that support high throughput read and write random access. It often achieves compression ratios on the order of 100:1 (i.e., to less than 1 bit per value of compressed storage with often imperceptible or numerically negligible errors introduced after compression.)
A fully-vectorized version using Intel® AVX2 and Intel®AVX-512 instructions is available in the Intel® Integrated Performance Primitives (Intel IPP) library for data compression for 3D single-precision arrays11 providing us with an average compression and decompression speedup of 2x and 4x, respectively. Both serial (0.5.2) and multithreaded (0.5.5) versions are now available as a patch provided with the IPP library.
Intel IPP also supports several different compression methods: Huffman and variable-length coding, dictionary-based coding methods (including support of ZLIB compression), and methods based on Burrows-Wheeler Transform.
By leveraging Intel® AVX-512-optimized ZFP compression, we achieved a speedup of more than 5.3x compared with a conventional RTM that doesn't use compression on Intel® 3DNAND P4800x SSD, though the speedup will vary with the type of disk and tolerance used in compression5.
Conclusion
Brightskies is spearheading innovation for the oil and gas industry by offering a full version of RTM in open source12, using multiple components of Intel's oneAPI offering: programming environments (DPC++, OpenMP), libraries (Intel® IPP for data compression), analysis tools (such as Intel® Advisor), and cloud environments (the Intel® DevCloud), with the express purpose of creating an implementation that is easily portable across multiple architectures and maximizes their effective use. For this, they started with an OpenMP version that worked on CPU and created a codebase in DPC++ that can run on CPU and GPU. They accomplished this by carefully selecting kernels that had heavy bandwidth requirements (memory-bound propagation, random velocity boundary, and second-order wave equation kernels), and were able to easily implement them in DPC++, as the programming language itself is based on modern C++ standards.
The roofline analysis substantiates the claim that Brightskies' RTM implementation on single UMA nodes is maximizing the use of available DRAM bandwidth.
As we saw, the DPC++ implementation shows lower bandwidth consumption than that of the OpenMP implementation because of known DPC++ compiler enhancements that are planned for a later release. Intel plans to analyze this application's performance on multiple NUMA nodes once performance adjustments are made to Intel's DPC++ compiler (anticipated this summer).
This foundational work is the basis from which industry and academia can advance the performance of RTM and maximize the exploitation of heterogeneous architectures through oneAPI.
Acknowledgements
Brightskies would like to thank Philippe Thierry from Intel Corporation for his chief advisory role throughout this project, and Sunny Gogar and Belinda Liviero from Intel Corporation for their assistance during the validation phase of the work.
References
1. Intel Corporation. 2020. Fact Sheet: oneAPI.
2. Intel Corporation. 2020. DPC++ overview.
3. Intel Corporation. 2020. Intel® DevCloud.
4. Mrozek, M., Ashbaugh, B., Brodman, J. 2020. Taking Memory Management to the Next Level: Unified Shared Memory in Action. Proceedings of the International Workshop on OpenCL.
5. Andreolli, C., Borges, L., Thierry, P. 2014. Eight Optimizations for 3-Dimensional Finite Difference (3DFD) Code with an Isotropic acoustic wave equation.
6. Metwaly, K., Elamrawi, K., Algizawy, E., Morad, K., Monir, I., ElBasyouni, M., Thierry, P. 2018. Accelerated Reverse Time Migration with optimized IO. ISC2018 Conference.
7. Symes, W. W. 2007. Reverse time migration with optimal checkpointing: Geophysics, 72, 213–221.
8. Imbert, D., Imadoueddine, K., Thierry, P., Chauris, H., Borges, L. 2011. Tips and tricks for finite difference and i/o‐less FWI. SEG, Expanded Abstracts, 30, 3174.
9. Clapp, R. G. 2009. "Reverse time migration with random boundaries," SEG Technical Program Expanded Abstracts 2009, Society of Exploration Geophysicists, pp. 2809–2813.
10. Lindstrom, P. 2014. Fixed-Rate Compressed Floating-Point Arrays. IEEE Transactions on Visualization and Computer Graphics, 20(12):2674-2683.
11. Intel Corporation. 2020. Intel® Integrated Performance Primitives Developer Reference.
12. Brightskies Inc. 2020. Brightskies RTM repository (Version 1.0.0).
13. Chattopadhyay, S and McMehan, G. 2008. Imaging conditions for prestack reverse-time migration. GEOPHYSICS 73: S81-S89.
Notices and Disclaimers
Software and workloads used in performance tests may have been optimized for performance only on Intel microprocessors.
Performance tests, such as SYSmark and MobileMark, are measured using specific computer systems, components, software, operations and functions. Any change to any of those factors may cause the results to vary. You should consult other information and performance tests to assist you in fully evaluating your contemplated purchases, including the performance of that product when combined with other products. For more complete information visit www.intel.com/benchmarks.
Intel's compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Intel technologies may require enabled hardware, software or service activation.
Intel does not control or audit third-party data. You should consult other sources to evaluate accuracy.
Your costs and results may vary. © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.