
Previously, we shared how to boost large language models (LLM) with PyTorch* on Intel® Xeon® processors, which provides the best practices for general inference scenarios with publicly available LLMs. This article guides you more advanced scenarios such as how to achieve peak performance on a customized LLM or your own private LLMs. Customized LLMs usually have specific model structures that cannot follow general practices for optimized performance. This article describes a fine-grained optimization to overcome this challenge.
A New Feature Supports Customizing LLMs with Private Structures
In the past year, LLMs have flourished with many open models contributing to the community. While researchers are building their own LLMs from transformer blocks with variants in the implementation details, models with private structures are required to secure competitive business advantages. To help with these scenarios and improve productivity, Intel® Extension for PyTorch* v2.3 provides a module-level LLM optimization API. This new feature provides module-level optimizations for commonly used LLM modules and functionalities. LLM creators can adopt this new API set to replace those basic blocks with optimized alternatives in models to obtain peak performance.
There are three categories of module-level LLM optimization APIs:
Category 1: Linear Post-op APIs
Linear+post operations patterns commonly exist in transformer blocks in LLM models, such as the Linear+activation function inside MLP and Feedforward layers. The following APIs provide the fusion optimization to reduce the post operations and fuse them into the linear computation to assist with performance speedup.
# using module init and forward
ipex.llm.modules.linearMul
ipex.llm.modules.linearGelu
ipex.llm.modules.linearNewGelu
ipex.llm.modules.linearAdd
ipex.llm.modules.linearAddAdd
ipex.llm.modules.linearSilu
ipex.llm.modules.linearSiluMul
ipex.llm.modules.linear2SiluMul
ipex.llm.modules.linearRelu
Category 2: Attention-Related APIs
Attention layers are the most important part of LLM models, where the mha and key_value caches are computed to support LLM generation tasks. The following APIs provide more performing Attention layers for customizing LLMs, such as IndirectAccessKVCacheAttention, RotaryEmbedding, normalization, VarlenAttention, and PagedAttention.
# using module init and forward
ipex.llm.modules.RotaryEmbedding
ipex.llm.modules.RMSNorm
ipex.llm.modules.FastLayerNorm
ipex.llm.modules.VarlenAttention
ipex.llm.modules.PagedAttention
ipex.llm.modules.IndirectAccessKVCacheAttention
# using as functions
ipex.llm.functional.rotary_embedding
ipex.llm.functional.rms_norm
ipex.llm.functional.fast_layer_norm
ipex.llm.functional.indirect_access_kv_cache_attention
ipex.llm.functional.varlen_attention
Category 3: Generation-Related APIs
Hugging Face* provides different generation functions as APIs to support different LLM decoding strategies. The following APIs provide support for some of those generation functions with optimizations like prompt sharing.
# using for optimizing huggingface generation APIs with prompt sharing
ipex.llm.generation.hf_beam_sample
ipex.llm.generation.hf_beam_search
ipex.llm.generation.hf_greedy_search
ipex.llm.generation.hf_sample
How to Apply the Optimized Software Stack for an LLM
As a demonstration for applying Intel Extension for PyTorch module-level LLM optimization APIs, we used Llama 3 from HuggingFace/Transformers. There are four layers of Llama 3 (also for most LLMs) that need to be modified: LlamaAttention, LlamaMLP, LlamaDecoderLayer, and LlamaModel. Functions and modules that can be optimized are:
- Fusion of linear2SiluMul at LlamaMLP layer
- Fusion of linearAdd from LlamaAttention layer and LlamaMLP layer with a residual add from the LlamaDecoderLayer layer
- Fusion of RotaryEmbedding and IndirectAccessKVCacheAttention at the LlamaAttention layer
- Fusion of RMSNorm at the LlamaDecoderLayer and lamaModel layers
Besides the previous optimizations, for the LlamaForCausalLM layer, we must rewrite its functions of prepare_inputs_for_generation and _reorder_cache to work with IndirectAccessKVCacheAttention, as shown in this example.
The following sections give more details.
Optimization for LlamaAttention
class LlamaAttention(nn.Module):
def __init__(……):
# default attributes init and naming are the same as transformers design.
# changes to init IndirectAccessKVCacheAttention and RotaryEmbedding from ipex.llm layers
self.IPEXAttention = ipex.llm.modules.IndirectAccessKVCacheAttention(
self.max_position_embeddings
)
self.ipex_rotary_emb = ipex.llm.modules.RotaryEmbedding(
self.max_position_embeddings,
self.head_dim,
self.rope_theta,
self.config.architectures[0],
)
def forward(……):
# QKV projections, reshape and get kv_seq_len are skipped
# changes to apply RotaryEmbedding
key_states = self.ipex_rotary_emb(
key_states,
position_ids,
self.num_key_value_heads,
self.head_dim,
self.head_dim // 2,
self.head_dim,
kv_seq_len,
)
query_states = self.ipex_rotary_emb(
query_states,
position_ids,
self.num_heads,
self.head_dim,
self.head_dim // 2,
self.head_dim,
kv_seq_len,
)
# changes to apply IndirectAccessKVCacheAttention
(attn_output, attn_weights, past_key_value) = self.IPEXAttention (
query_states,
key_states,
value_states,
math.sqrt(self.head_dim),
past_key_value,
None,
attention_mask,
)
# self.o_proj is moved to LlamaDecoderLayer to enable linear+add fusion
return attn_output, attn_weights, past_key_value
Optimization for LlamaMLP and LlamaDecoderLayer
class LlamaMLP(nn.Module):
def __init__(……):
# default attributes init and naming are the same as transformers design.
def forward(……):
# changes to apply Linear2SiluMul fusion from ipex.llm layers
if not hasattr(self, "ipex_fusion"):
self.ipex_fusion = ipex.llm.modules.Linear2SiluMul(
self.gate_proj, self.up_proj
)
return self.ipex_fusion(x)
# self.down_proj is move to LlamaDecoderLayer to enable linear+add fusion
class LlamaDecoderLayer(nn.Module):
def __init__(……..):
# default attributes init and naming are the same as transformers design.
# changes to apply RMSNorm from ipex.llm layers
self.input_layernorm = ipex.llm.modules.RMSNorm(
config.hidden_size, eps=config.rms_norm_eps
)
self.post_attention_layernorm = ipex.llm.modules.RMSNorm(
config.hidden_size, eps=config.rms_norm_eps
)
def forward(……):
# get residual, run norm layer, run attention layer are skipped
# changes to apply LinearAdd fusion from ipex.llm layers
if not hasattr(self, "ipex_fusion_mha_linear_add"):
self. ipex_fusion_mha_linear_add = ipex.llm.modules.LinearAdd(self.self_attn.o_proj)
hidden_states = self. ipex_fusion_mha_linear_add(hidden_states, residual)
# get residual, run norm layer, run mlp layer are skipped
# changes to apply LinearAdd fusion from ipex.llm layers
if not hasattr(self, " ipex_fusion_mlp_linear_add "):
self.ipex_fusion_mlp_linear_add = ipex.llm.modules.LinearAdd(self.mlp.down_proj)
hidden_states = self.ipex_fusion_mlp_linear_add(hidden_states, residual)
outputs = (hidden_states,)
outputs += (present_key_value,)
return outputs
Optimization for LlamaModel
class LlamaModel(PreTrainedModel):
def __init__(…….):
# default attributes init and naming are the same as transformers design.
# changes to apply RMSNorm from ipex.llm layers
self.norm = ipex.llm.modules.RMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(……): # no changes from transformers design
To apply optimizations when calling model.generate() from the Hugging Face text generation API:
# Taking beam search as example here
hf_beam_search = ipex.llm.generation.hf_beam_search.__get__(model, model.__class__)
setattr(model, "beam_search", hf_beam_search)
Benchmark Results Demonstrate LLM Performance
The following are benchmark results based on the previous optimizations using a single 4th gen Intel® Xeon® Scalable processor. The benchmarks compare the performance before and after applying this module-level optimization API from Intel Extension for PyTorch. The benchmarking is performed with an input token length from 1K to 8K to simulate different use scenarios and is run under the bfloat16 datatype with Llama 3 as the example model.
As shown in figures 1 and 2, module-level LLM optimization API can produce approximately a 5x performance boost across different input token sizes, while for next token latency, the benefit grows when size increases from 3x on a 1K token input to more than 5x on an 8K token input.
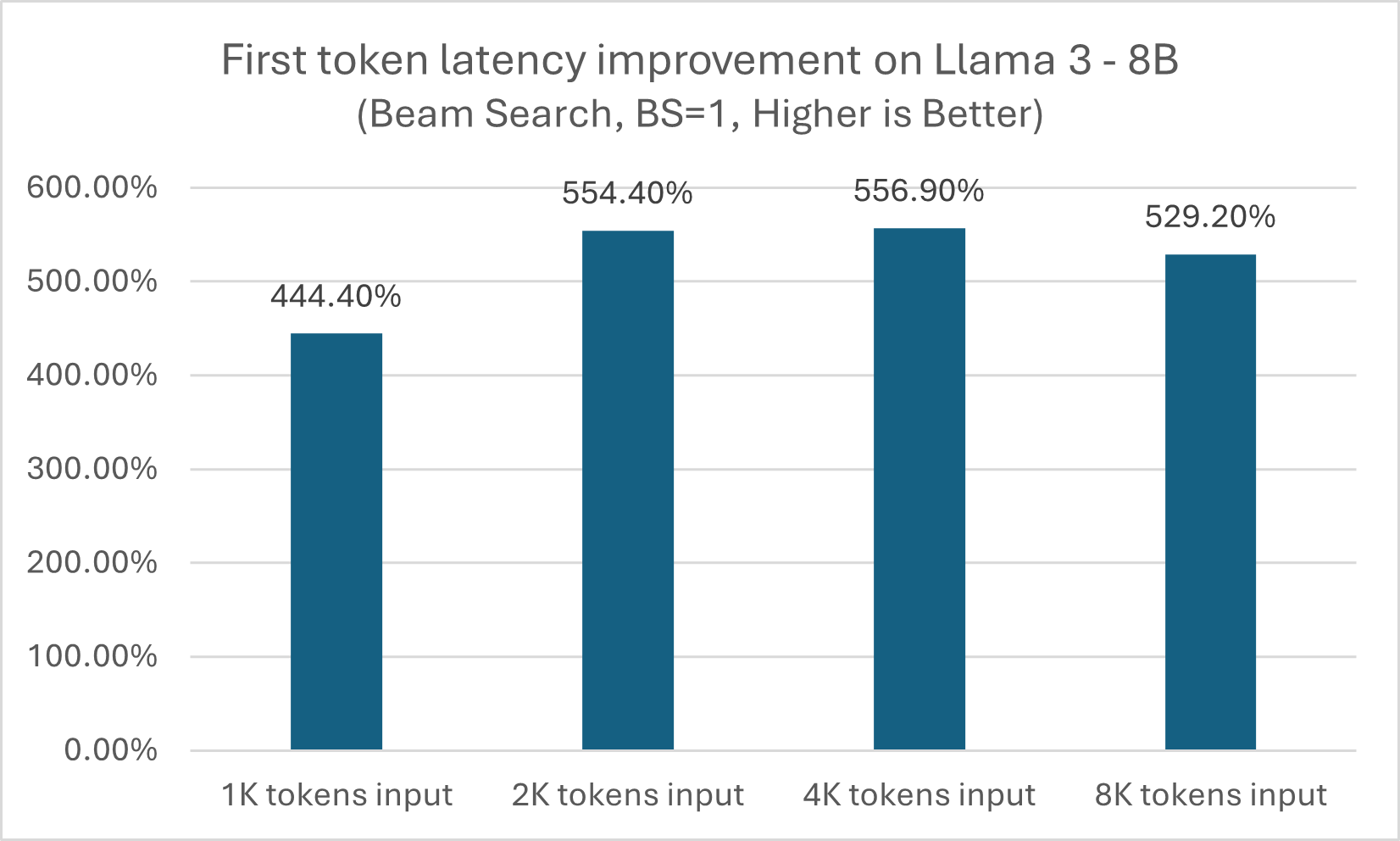
Figure 1. First token latency improvement with a module-level LLM optimization API
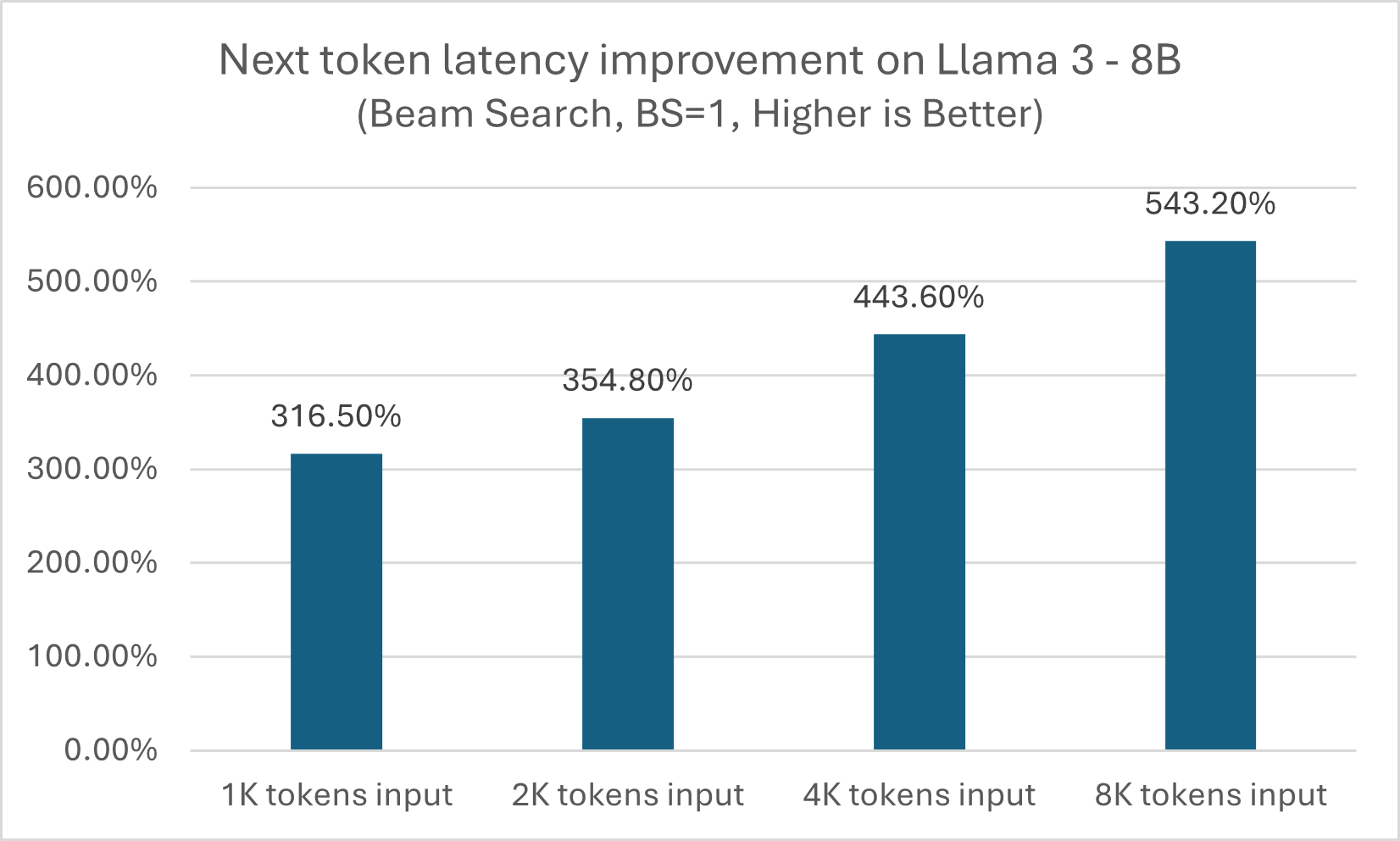
Figure 2. Next token latency improvement with a module-level LLM optimization API
Conclusion
The new module-level LLM optimization API from Intel Extension for PyTorch provides good LLM inference performance for customized or private LLMs. Furthermore, this new API set can be applied to LLM-serving frameworks like vLLM and text generation inference (TGI), which also have their own customized LLM models. To provide good LLM performance on Intel Xeon processors, work for the adoption of this API set for these frameworks is ongoing. To adopt these optimizations and improve the performance for LLM models, we are also upstreaming these optimizations into PyTorch and a related ecosystem project.
We encourage you to also check out and incorporate Intel’s other AI and machine learning framework optimizations and end-to-end portfolio of tools into your AI workflow. Learn about the unified, open, standards-based oneAPI programming model that forms the foundation of Intel® AI Portfolio to help you prepare, build, deploy, and scale your AI solutions.
Product and Performance Information
Performance benchmarking configuration: Amazon Web Services (AWS)* m7i.metal-48xl, Intel® Xeon® Platinum 8488C CPU, 96 cores, 192 threads, microcode 0x2b000590; Ubuntu* 22.04.4 LTS, 6.5.0-1016-aws; PyTorch v2.3.0; Intel Extension for PyTorch v2.3.0; DeepSpeed v0.14.0; Model: Llama 3 8B; Token Length: 128/1024/2048/8064 (in), 128 (out); Tested on one socket, BS=1, beam=4, precision: bfloat16. Tested by Intel on April 30, 2024.