Big data and analytics play a central role in today’s smart and connected world, and are continuously driving the convergence of big data, analytics, and machine learning/deep learning. We open sourced BigDL, a distributed deep learning library for Apache Spark*, in December 2016, for the very purpose of uniting the deep learning community and the big data community. The rest of this article provides an overview of recent enhancements available in the BigDL 0.1.0 release (as well as in the upcoming 0.1.1 release).
- Python* Support
Python* is one of the most widely used languages in the big data and data science community, and BigDL provides full support for Python APIs (using Python 2.7), based on PySpark since its 0.1.0 release; this allows users to use deep learning models in BigDL together with existing Python libraries (for example, NumPy and Pandas), which automatically run in a distributed fashion to process large volumes of data across Hadoop*/Spark clusters. For instance, we can create the LeNet-5 model, a classic convolutional neural network, using the BigDL Python API as follows:
def build_model(class_num): model = Sequential() model.add(Reshape([1, 28, 28])) model.add(SpatialConvolution(1, 6, 5, 5).set_name('conv1')) model.add(Tanh()) model.add(SpatialMaxPooling(2, 2, 2, 2).set_name('pool1')) model.add(Tanh()) model.add(SpatialConvolution(6, 12, 5, 5).set_name('conv2')) model.add(SpatialMaxPooling(2, 2, 2, 2).set_name('pool2')) model.add(Reshape([12 * 4 * 4])) model.add(Linear(12 * 4 * 4, 100).set_name('fc1')) model.add(Tanh()) model.add(Linear(100, class_num).set_name('score')) model.add(LogSoftMax()) return modelIn addition, we continue to improve Python support in BigDL; the upcoming BigDL 0.1.1 release will add Python 3.5 support, as well as support for users to automatically deploy their customized Python dependency across YARN* clusters.
- Notebook Integration
With full Python API support in BigDL, data scientists and analysts can now explore their data using powerful notebooks (such as the Jupyter Notebook) in a distributed fashion across the cluster, combining Python libraries, Spark SQL / DataFrames and MLlib, deep learning models in BigDL, as well as interactive visualization tools. For instance, the Jupyter Notebook tutorial contained in BigDL 0.1.0 demonstrates how we can evaluate the prediction result of a text classification model (using both accuracy and confusion matrix) as follows:
predictions = trained_model.predict(val_rdd).collect() def map_predict_label(l): return np.array(l).argmax() def map_groundtruth_label(l): return l[0] - 1 y_pred = np.array([ map_predict_label(s) for s in predictions]) y_true = np.array([map_groundtruth_label(s.label) for s in val_rdd.collect()]) acc = accuracy_score(y_true, y_pred) print "The prediction accuracy is %.2f%%"%(acc*100) cm = confusion_matrix(y_true, y_pred) cm.shape df_cm = pd.DataFrame(cm) plt.figure(figsize = (10,8)) sn.heatmap(df_cm, annot=True,fmt='d');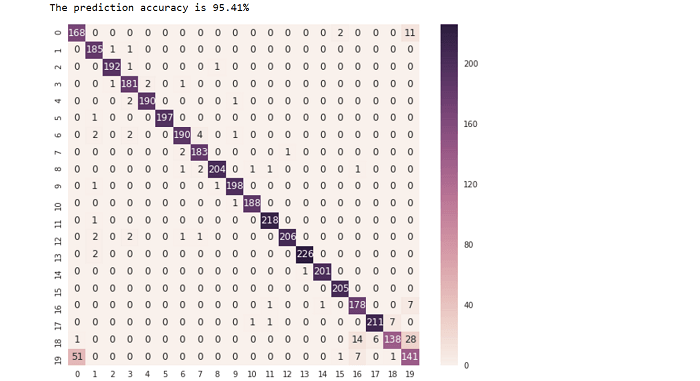
- TensorBoard* Support
TensorBoard* is a suite of web applications for inspecting and understanding deep learning program runs and graphs, and BigDL 0.1.0 provides support for visualizations using TensorBoard (as well as inline plotting libs such as Matplotlib* within the notebook). First, a BigDL program can be configured to generate summary information for training and/or validation, as illustrated below (using Python APIs):
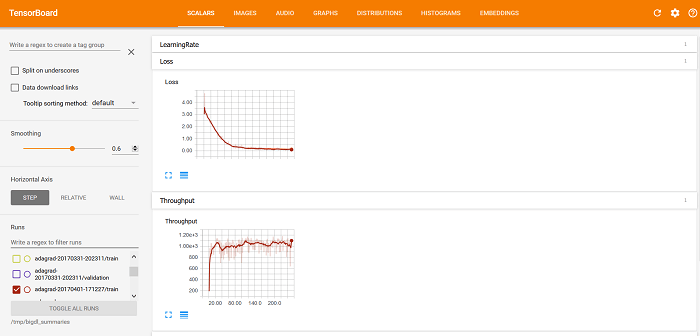
optimizer = Optimizer(...) ... log_dir = 'mylogdir' app_name = 'myapp' train_summary = TrainSummary(log_dir=log_dir, app_name=app_name) val_summary = ValidationSummary(log_dir=log_dir, app_name=app_name) optimizer.set_train_summary(train_summary) optimizer.set_val_summary(val_summary) ... trainedModel = optimizer.optimize()After we start to run the BigDL program, the train and validation summary is saved to and respectively; after that, we can use TensorBoard to visualize the behaviors of the BigDL program, including the Loss and Throughput curves under the SCALARS tab (as illustrated below).
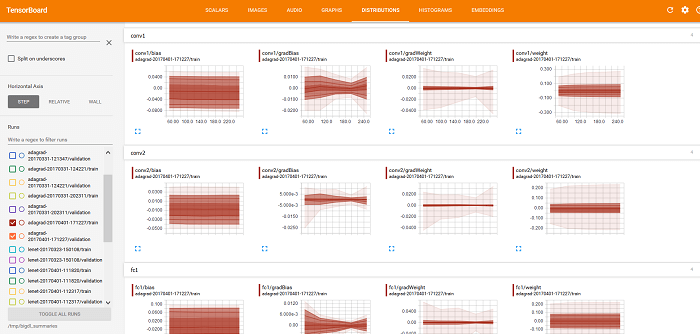
We can also use TensorBoard to visualize weights, bias, gradientWeights, and gradientBias under the DISTRIBUTIONS and HISTOGRAMS tabs (as illustrated below).
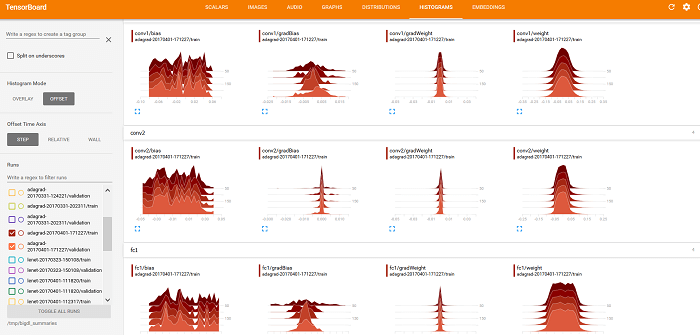
- Better RNN Support
Recurrent neural networks (RNN) are powerful models for analyzing speech, text, times series, sensor data, and so on. The BigDL 0.1.0 release provides comprehensive support for RNN, including different variants of long short-term memory such as gated recurrent unit (GRU), LSTM with peephole, and dropout in recurrent neural networks. For instance, we can create a simple LSTM model (using the Python API) as follows:
model = Sequential() model.add(Recurrent() .add(LSTM(embedding_dim, 128))) model.add(Select(2, -1)) model.add(Linear(128, 100)) model.add(Linear(100, class_num))
We have seen major advancements in deep learning in recent years; while the deep learning community continues to push the technology envelope, BigDL helps make these breakthroughs more accessible and convenient to use for data scientists and data engineers (who are not necessarily experts in deep learning technologies). We continue to work on enhancements in BigDL beyond the 0.1 release (for example, support for reading/writing TensorFlow models, Convolutional Neural Network (CNN) implementations for 3D images, recursive nets, and so on), so that big data users can continue the use of familiar tools and infrastructure to build their deep learning-powered analytics applications.